Модель линии крыши с руководством по CUDA и Nsight Compute
У меня есть очень простое ядро векторного сложения, написанное для CUDA. Я хочу рассчитать арифметическую интенсивность, а также GFLOP/s для этого ядра. Рассчитанные мной значения заметно отличаются от значений, полученных в разделе «Анализ линии крыши» Nsight Compute.
Поскольку у меня очень простое ядро векторного сложения фермыC = A + Bпоскольку все три вектора имеют ожидаемый мной размер, я ожидаю:Nарифметические операции и3 x N x 4(при условииsizeof(float)==4) байтов, то это приведет к арифметической интенсивности примерно 0,083.
Кроме того, я ожидал бы, что тогда, за исключением GFLOP/s, будетN x 1e-9 / kernel_time_in_secondsЗначения, которые я вычисляю, заметно отличаются от вычислений Nsight. Я знаю, что вычисления Nsight уменьшают тактовую частоту, но я ожидаю, что значения арифметической интенсивности (операции на байт) будут такими же (или примерно такими же, поскольку они есть). профилирует код).
Мои ядра CUDA выглядят следующим образом:
#include <iostream>
#include <cuda_runtime.h>
#define N 200000
__global__ void vectorAdd(float* a, float* b, float* c)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
if (tid < N)
{
c[tid] = a[tid] + b[tid];
}
}
int main()
{
// Declare and initialize host vectors
float* host_a = new float[N];
float* host_b = new float[N];
float* host_c = new float[N];
for (int i = 0; i < N; ++i)
{
host_a[i] = i;
host_b[i] = 2 * i;
}
// Declare and allocate device vectors
float* dev_a, * dev_b, * dev_c;
cudaMalloc((void**)&dev_a, N * sizeof(float));
cudaMalloc((void**)&dev_b, N * sizeof(float));
cudaMalloc((void**)&dev_c, N * sizeof(float));
// Copy host vectors to device
cudaMemcpy(dev_a, host_a, N * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, host_b, N * sizeof(float), cudaMemcpyHostToDevice);
// Define kernel launch configuration
int blockSize, gridSize;
cudaOccupancyMaxPotentialBlockSize(&gridSize, &blockSize, vectorAdd, 0, N);
// Start timer
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start);
// Launch kernel
vectorAdd<<<gridSize, blockSize>>>(dev_a, dev_b, dev_c);
// Stop timer and calculate execution duration
cudaEventRecord(stop);
cudaEventSynchronize(stop);
float milliseconds = 0;
cudaEventElapsedTime(&milliseconds, start, stop);
// Copy result from device to host
cudaMemcpy(host_c, dev_c, N * sizeof(float), cudaMemcpyDeviceToHost);
cudaDeviceSynchronize();
// Print execution duration
std::cout << "Kernel execution duration: " << milliseconds << " ms" << std::endl;
int numFloatingPointOps = N;
int numBytesAccessed = 3 * N * sizeof(float);
float opsPerByte = static_cast<float>(numFloatingPointOps) / static_cast<float>(numBytesAccessed);
std::cout << "Floating-point operations per byte: " << opsPerByte << std::endl;
float executionTimeSeconds = milliseconds / 1e3;
float numGFLOPs = static_cast<float>(numFloatingPointOps) / 1e9;
float GFLOPs = numGFLOPs / executionTimeSeconds;
std::cout << "GFLOP/s: " << GFLOPs << std::endl;
// Cleanup
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
delete[] host_a;
delete[] host_b;
delete[] host_c;
return 0;
}
Пример вывода на моем компьютере:
Kernel execution duration: 0.014144 ms
Floating-point operations per byte: 0.0833333
GFLOP/s: 14.1403
Скомпилировано и запущено/профилировано просто с помощью:
nvcc vectorAdd.cu
sudo env "PATH=$PATH" ncu -f -o vectorAdd_rep --set full ./a.out
Nsight Comput говорит, что арифметическая интенсивность равна 0,12, у меня есть фото: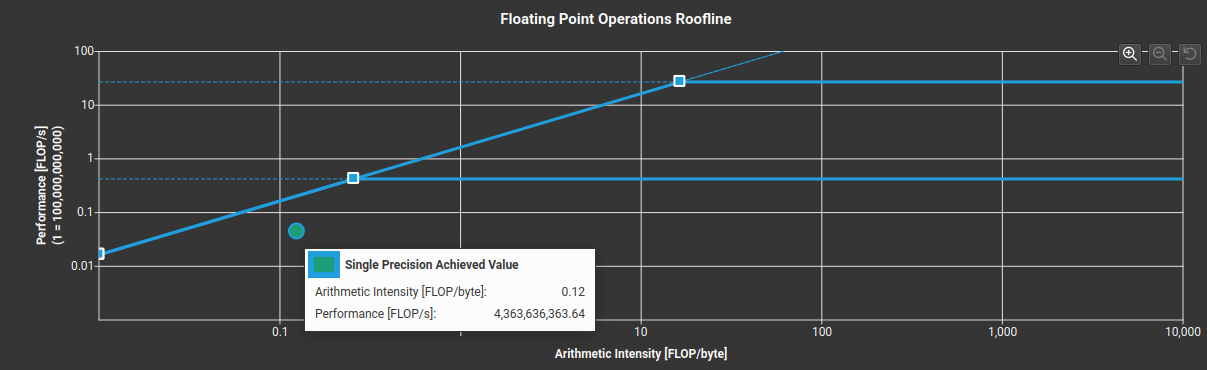
Когда я смотрю на статистику инструкций, операции, связанные с глобальной загрузкой (LDG) и сохранением (STG), в 3 раза больше FADD (поэлементное плавающее сложение) с размером в 4 байта, я бы не ожидал 0,083, но это не так. В чем же причина несоответствия двух арифметических интенсивностей, я делаю что-то не так? Другие инструкции, которые я проверил, похоже, не имеют отношения к арифметическому расчету интенсивности.
Добавляю фото по статистике инструкции: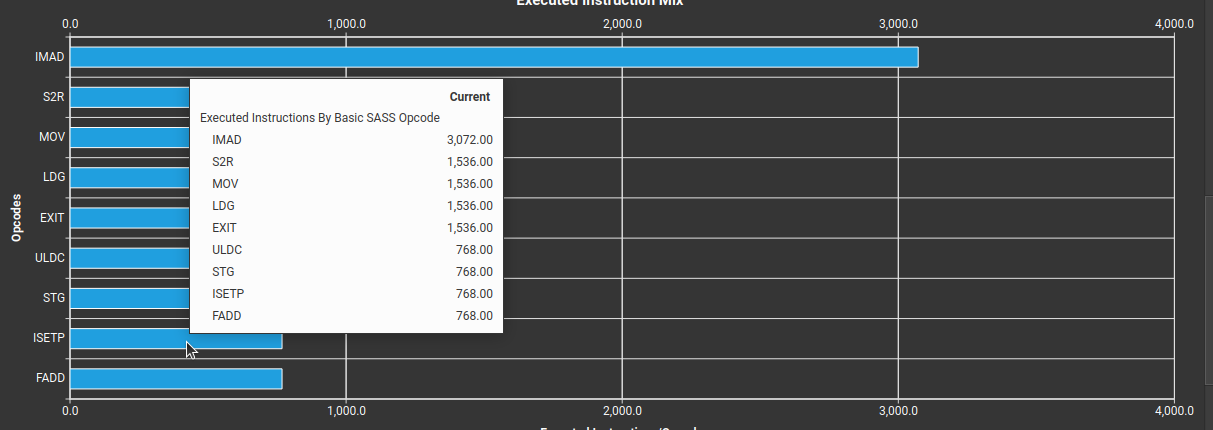
1 ответ
Благодаря обновленному коду по совету user12939557 я смог выявить проблему. Во-первых, результаты, полученные с помощью Nsight Compute, неточны для малых размеров сетки. При достаточном количестве элементов результаты Nsight Compute довольно близки к моим.
Еще одно важное замечание заключается в том, что профилированный код выполняется на меньшей тактовой частоте, поскольку теоретические границы (по передаче памяти и достигаемым пиковым значениям FLOP/с) меньше значений, которые можно получить с помощью вызовов API CUDA. Я могу также убедиться, что и в моем коде, и в Nsight Compute достигнутый процент пиковой производительности (с учетом интенсивности арифметических вычислений) весьма схож. Вот обновленный код:
#include <iostream>
#include <cuda_runtime.h>
constexpr size_t N = static_cast<size_t>(1e9 / static_cast<float>(sizeof(float)));
#define CHECK_ERR checkErr(__FILE__,__LINE__)
std::string PrevFile = "";
int PrevLine = 0;
void checkErr(const std::string &File, int Line) {{
#ifndef NDEBUG
cudaError_t Error = cudaGetLastError();
if (Error != cudaSuccess) {{
std::cout << std::endl << File
<< ", line " << Line
<< ": " << cudaGetErrorString(Error)
<< " (" << Error << ")"
<< std::endl;
if (PrevLine > 0)
std::cout << "Previous CUDA call:" << std::endl
<< PrevFile << ", line " << PrevLine << std::endl;
throw;
}}
PrevFile = File;
PrevLine = Line;
#endif
}}
__global__ void vectorAdd(float* a, float* b, float* c)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
if (tid < N)
{
c[tid] = a[tid] + b[tid];
}
}
int main()
{
// Declare and initialize host vectors
float* host_a = new float[N];
float* host_b = new float[N];
float* host_c = new float[N];
for (int i = 0; i < N; ++i)
{
host_a[i] = i;
host_b[i] = 2 * i;
}
// Declare and allocate device vectors
float* dev_a, * dev_b, * dev_c;
cudaMalloc((void**)&dev_a, N * sizeof(float)); CHECK_ERR;
cudaMalloc((void**)&dev_b, N * sizeof(float)); CHECK_ERR;
cudaMalloc((void**)&dev_c, N * sizeof(float)); CHECK_ERR;
// Copy host vectors to device
cudaMemcpy(dev_a, host_a, N * sizeof(float), cudaMemcpyHostToDevice); CHECK_ERR;
cudaMemcpy(dev_b, host_b, N * sizeof(float), cudaMemcpyHostToDevice); CHECK_ERR;
// Define kernel launch configuration
// int blockSize, gridSize;
// cudaOccupancyMaxPotentialBlockSize(&gridSize, &blockSize, vectorAdd, 0, N); CHECK_ERR;vectorAdd<<<gridSize, blockSize>>>(dev_a, dev_b, dev_c); CHECK_ERR;
int blockSize = 256;
int gridSize = (N + blockSize - 1) / blockSize;
// Fire first kernel and discard
vectorAdd<<<gridSize, blockSize>>>(dev_a, dev_b, dev_c); CHECK_ERR;
cudaDeviceSynchronize();
// Start timer
cudaEvent_t start, stop;
cudaEventCreate(&start); CHECK_ERR;
cudaEventCreate(&stop); CHECK_ERR;
cudaEventRecord(start); CHECK_ERR;
// Launch kernel
vectorAdd<<<gridSize, blockSize>>>(dev_a, dev_b, dev_c); CHECK_ERR;
// Stop timer and calculate execution duration
cudaEventRecord(stop); CHECK_ERR;
cudaEventSynchronize(stop); CHECK_ERR;
float milliseconds = 0;
cudaEventElapsedTime(&milliseconds, start, stop); CHECK_ERR;
// Copy result from device to host
cudaMemcpy(host_c, dev_c, N * sizeof(float), cudaMemcpyDeviceToHost); CHECK_ERR;
cudaDeviceSynchronize(); CHECK_ERR;
for (int i = 0; i < N; ++i)
{
if (host_c[i] > 1.001f * (3.0f * static_cast<float>(i)) ||
host_c[i] < 0.999f * (3.0f * static_cast<float>(i))){
throw std::runtime_error("Results different from expected " + std::to_string(host_c[i]) + " != " + std::to_string(3.0f * static_cast<float>(i)));
}
}
// Print execution duration
std::cout << "Kernel execution duration: " << milliseconds << " ms" << std::endl;
size_t numFloatingPointOps = N;
size_t numBytesAccessed = 3 * N * sizeof(float);
float opsPerByte = static_cast<float>(numFloatingPointOps) / static_cast<float>(numBytesAccessed);
std::cout << "Floating-point operations per byte: " << opsPerByte << std::endl;
float executionTimeSeconds = milliseconds / 1e3;
float numGFLOPs = static_cast<float>(numFloatingPointOps) / 1e9;
float GFLOPs = numGFLOPs / executionTimeSeconds;
std::cout << "GFLOP/s: " << GFLOPs << std::endl;
float peakMemoryBandwidthTheo = 176.032; // GB /s
float peakGFLOPTheo = 4329.47; // GFlop /s
float peakGFLOPforIntensity = std::min(peakMemoryBandwidthTheo * opsPerByte, peakGFLOPTheo);
float achievedPeak = (static_cast<float>(GFLOPs) / peakGFLOPforIntensity) * 100.0f;
std::string strAchievedPeak(6, '\0');
std::sprintf(&strAchievedPeak[0], "%.2f", achievedPeak);
std::cout << "Percentage of Peak Performance: " << strAchievedPeak << "%" << std::endl;
float GBPerSecond = (static_cast<float>(numBytesAccessed) * 1e-9) / executionTimeSeconds;
std::cout << "GB per Second: " << GBPerSecond << std::endl;
// Cleanup
cudaFree(dev_a); CHECK_ERR;
cudaFree(dev_b); CHECK_ERR;
cudaFree(dev_c); CHECK_ERR;
delete[] host_a;
delete[] host_b;
delete[] host_c;
return 0;
}
Пример вывода моего RTX 3050:
Kernel execution duration: 17.6701 ms
Floating-point operations per byte: 0.0833333
GFLOP/s: 14.1482
Percentage of Peak Performance: 96.45%
GB per Second: 169.778