Ошибка «Объект DataFrame не имеет атрибута добавления»
Я пытаюсь добавить словарь к объекту DataFrame, но получаю следующую ошибку:
AttributeError: объект «DataFrame» не имеет атрибута «добавление»
Насколько я знаю, в DataFrame есть метод «добавить».
Фрагмент кода:
df = pd.DataFrame(df).append(new_row, ignore_index=True)
я ждал словаряnew_rowбудет добавлен как новая строка.
Как я могу это исправить?
4 ответа
Начиная с версии pandas 2.0 (ранее устаревший) был удален .
Вам нужно использовать вместо этого (для большинства приложений):
df = pd.concat([df, pd.DataFrame([new_row])], ignore_index=True)
Как отметил @cottontail , также можно использовать loc, хотя это работает только в том случае, если новый индекс еще не присутствует в DataFrame (обычно это происходит, если индекс являетсяRangeIndex:
df.loc[len(df)] = new_row # only use with a RangeIndex!
Почему его удалили?
Мы часто видим, как новые пользователи pandas пытаются писать код так, как если бы они делали это на чистом Python. Они используют iterrowsдля доступа к элементам в цикле (см. здесь , почему этого не следует делать) или способом, аналогичным Python .
Однако, как отмечено в выпуске pandas #35407, pandas и на самом деле не одно и то же . находится на месте, а pandas создает новый DataFrame:
Я думаю, что нам следует исключить Series.append и DataFrame.append. Они проводят аналогию со list.append, но это плохая аналогия, поскольку поведение не является (и не может быть) на месте. Для создания результата необходимо скопировать данные для индекса и значений.
Это также очевидно популярные методы. DataFrame.append занимает примерно 10-е место по посещаемости в нашей документации API.
Если я не ошибаюсь, пользователям всегда лучше создать список значений и передать его конструктору или создать список NDFrames, за которым следует один конкат.
Как следствие, в то время какlist.appendамортизируется O(1) на каждом шаге цикла, pandas' равен
O(n), что делает его неэффективным при повторной вставке .
Что делать, если мне нужно повторить процесс?
С использованиемappendилиconcatмногократно — не очень хорошая идея (это имеет квадратичное поведение, поскольку для каждого шага создается новый DataFrame).
В таком случае новые элементы должны быть собраны в список, а в конце цикла преобразованы в исходные и в конечном итоге объединены с ними.DataFrame.
lst = []
for new_row in items_generation_logic:
lst.append(new_row)
# create extension
df_extended = pd.DataFrame(lst, columns=['A', 'B', 'C'])
# or columns=df.columns if identical columns
# concatenate to original
out = pd.concat([df, df_extended])
Отказ от ответственности: этот ответ, похоже, пользуется популярностью, но предложенный подход не следует использовать . не был изменен на , является частным внутренним методом и был удален из API панд. Утверждение : «Метод в pandas похож на list.append в Python. Вот почему метод добавления в pandas теперь изменен на ». совершенно неверно. Ведущий_означает только одно: метод является частным и не предназначен для использования вне внутреннего кода pandas.
В новой версии Pandas метод изменен на . Вы можете просто использовать вместо , т.е.df._append(df2).
df = df1._append(df2,ignore_index=True)
Почему оно изменено?
The appendМетод в pandas похож на list.append в Python. Вот почему метод добавления в pandas теперь изменен на_append.
Если это одна строка , это также может выполнить эту работу.
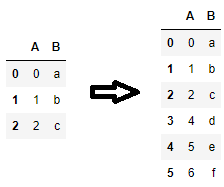
df.loc[len(df)] = new_row
При вызове кадр данных увеличивается с помощью индексной метки.len(df), что имеет смысл только в том случае, если индекс равен ;RangeIndexсоздается по умолчанию, если явный индекс не передается конструктору фрейма данных.
Рабочий пример:
df = pd.DataFrame({'A': range(3), 'B': list('abc')})
df.loc[len(df)] = [4, 'd']
df.loc[len(df)] = {'A': 5, 'B': 'e'}
df.loc[len(df)] = pd.Series({'A': 6, 'B': 'f'})
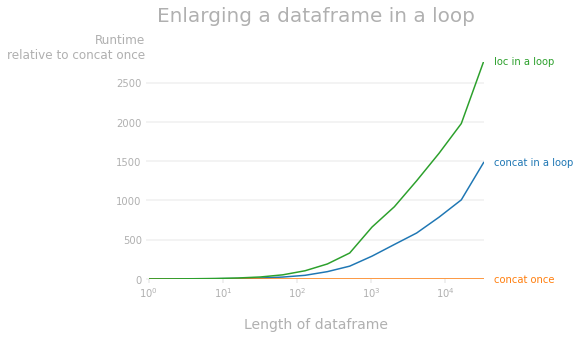
Тем не менее, если вы увеличиваете кадр данных в цикле, используяDataFrame.appendили или рассмотрите возможность переписать свой код, чтобы увеличить список Python и один раз создать кадр данных.
Как отметил @mozway, увеличение кадра данных pandas имеет сложность O(n^2), поскольку на каждой итерации необходимо прочитать и скопировать весь кадр данных. Следующий график показывает разницу во времени выполнения относительно однократной конкатенации. 1 Как видите, оба способа увеличения фрейма данных намного медленнее, чем увеличение списка и однократное создание фрейма данных (например, для фрейма данных с 10 тысячами строкconcatв цикле примерно в 800 раз медленнее иlocв цикле примерно в 1600 раз медленнее).
1 Код, используемый для создания графика производительности:
import pandas as pd
import perfplot
def concat_loop(lst):
df = pd.DataFrame(columns=['A', 'B'])
for dic in lst:
df = pd.concat([df, pd.DataFrame([dic])], ignore_index=True)
return df.infer_objects()
def concat_once(lst):
df = pd.DataFrame(columns=['A', 'B'])
df = pd.concat([df, pd.DataFrame(lst)], ignore_index=True)
return df.infer_objects()
def loc_loop(lst):
df = pd.DataFrame(columns=['A', 'B'])
for dic in lst:
df.loc[len(df)] = dic
return df
perfplot.plot(
setup=lambda n: [{'A': i, 'B': 'a'*(i%5+1)} for i in range(n)],
kernels=[concat_loop, concat_once, loc_loop],
labels= ['concat in a loop', 'concat once', 'loc in a loop'],
n_range=[2**k for k in range(16)],
xlabel='Length of dataframe',
title='Enlarging a dataframe in a loop',
relative_to=1,
equality_check=pd.DataFrame.equals);
AttributeError: объект «DataFrame» не имеет атрибута «добавление». Вы имели в виду: '_append'?
Для Pandas с совместимостью TensorFlow 2.12 пользователям просто нужно внести небольшое изменение для успеха.
all_data = train_df.append(test_df)
Измените добавление на _aqppend
all_data = train_df._append(test_df)
И тогда программа сможет работать корректно.