В Pyspark, как перебирать каждую строку во фрейме данных, сохраняют ли вычисления значение и используют его на следующем этапе за разделом
Пример ввода: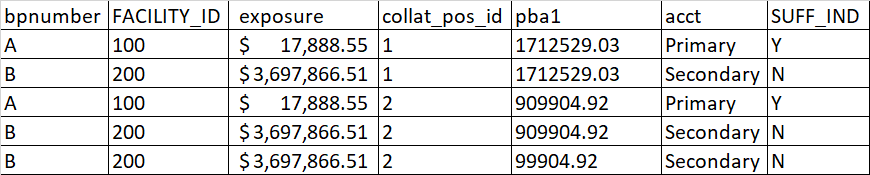
Ожидаемый результат:
Как мне написать код в Pyspark для решения вышеуказанной проблемы?
Описание проблемы:
Соответствующий код будет перебирать каждую строку набора данных, разделенного по Col_id_latest. Для всех первых записей total_alloc будет нулевым, а для остальных в зависимости от условия If else будет создан новый столбец, заключительный. Total_alloc необходимо сохранить и использовать в следующей итерации. Я попытался в pyspark написать цикл for для перебора каждой строки, что очень неэффективно. А на больших наборах данных выдает ошибки памяти. Есть ли лучший способ написания или какие-либо предложения по написанию кода pyspark? Может ли кто-нибудь написать пример кода, на который я мог бы ссылаться? Я пробовал написать цикл for, который очень неэффективен и требует времени для выполнения любых лучших методов с использованием оконного метода, но мне нужно сохранить значение и использовать его в следующей итерации.
Ниже приведен код SAS:
data x;
set y;
by coll_id_latest;
retain total_alloc 0;
if first.coll_id_latest then
do;total_alloc=0;end;
if lowcase(acct)="primary" then
do;
if exposure not in (.,0) and total_alloc<pba1 then
final_pba = min(exposure,(pba1-total_alloc));
else final_pba = 0;
end;
if lowcase(acct)="secondary"
and lowcase(suff_ind)^='y' and total_alloc < pba1 then
do;
final_pba =min(max(pba1-total_alloc,0),exposure);
end;
total_alloc=sum(total_alloc,final_pba);
run;