Несбалансированное чтение и запись памяти в CUDA
Я заметил несбалансированный объем чтения и записи памяти при профилировании нижнего ядра cuda с помощью ncu.
__global__ void kernel(void* mem, int n) {
int* ptr = reinterpret_cast<int*>(mem);
for (int offset = (threadIdx.x + blockIdx.x * blockDim.x)*32; offset < n; offset += blockDim.x * gridDim.x * 32) {
#pragma unroll
for (int i = 0; i < 16; i++) {
ptr[offset + i] = ptr[offset + i + 16];
}
}
}
int main() {
int* mem;
int N = 1024 * 256 * 256;
cudaMalloc((void**)&mem, sizeof(int) * N);
cudaMemset(mem, 0, sizeof(int) * N);
kernel<<<8192, 256>>>(mem, N);
cudaFree(mem);
return 0;
}
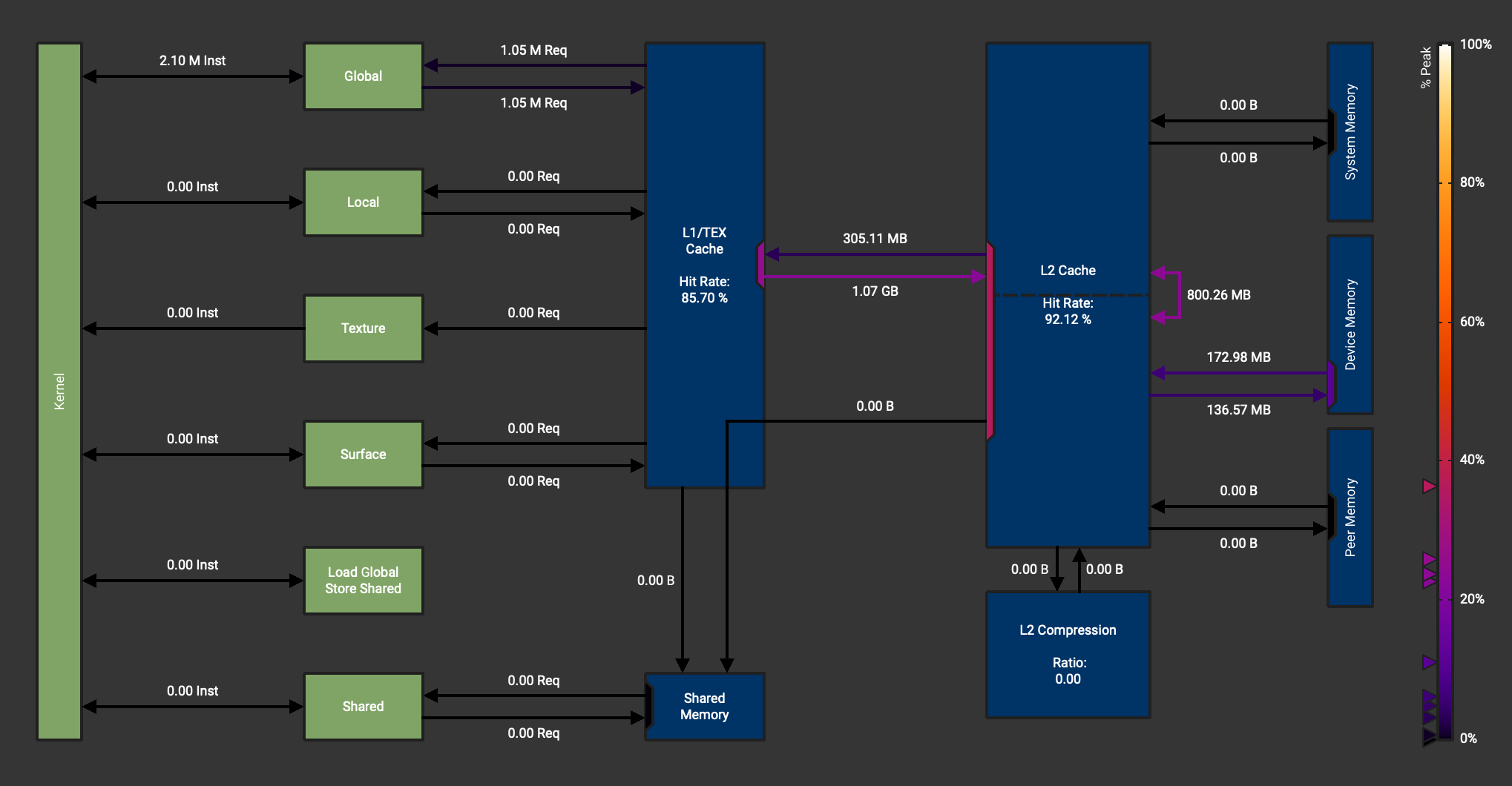
В ncu мне сообщается, что чтение памяти составляет 305 МБ, а запись в память - 1,07 ГБ. Я понимаю, что существует глобальное объединение памяти, но разве объем памяти для чтения и записи не должен быть равен примерно 1 ГБ, а не только для чтения 305 МБ? И даже если для чтения памяти нет глобального объединения памяти, разве объем чтения памяти не должен быть равен примерно 128 МБ?
Спасибо.
1 ответ
разве объем памяти для чтения и записи не должен быть равен примерно 1 ГБ, а не только для чтения 305 МБ?
Трафик, который вы определили:
он сообщает мне, что чтение памяти составляет 305 МБ, а запись в память - 1,07 ГБ.
на самом деле это трафик между кэшами L1 и L2.
Кэш L1 графического процессора обычно описывается как «сквозная запись» (например, слайд 43). Это может привести к значительному «дисбалансу» трафика L1<->L2 для «сбалансированного» кода чтения/записи: операции записи могут вызвать трафик на L2 при каждой записи, операции чтения могут попасть в L1, поэтому не генерирует соответствующий трафик для L2.
разве объем чтения памяти не должен быть равен примерно 128 МБ?
Трафик от L1 к L2 превышает фактический трафик памяти, поскольку кэш L1 относительно мал и не может вместить весь объем памяти, занимаемый вашим кодом. Динамический след вашего кода гораздо выше, чем необходимо для выполнения фактической работы, которую вы выполняете, из-за несвязанного шаблона доступа и неэффективного использования ресурсов памяти. Поэтому трафик от L1 до L2 может быть намного выше 128 МБ.
Что касается трафика L2 в память, в зависимости от вашего графического процессора L2 также может быть меньше 128 МБ. В этом случае, опять же, наличие большего, чем необходимо, динамического следа (память затрагивается из-за искажений в полете) в сочетании с неэффективным использованием памяти означает, что вы также можете эффективно перегрузить L2, что приведет к более высокому, чем необходимо, трафику в памяти.