Каким образом GPT-подобные преобразователи используют только декодер для генерации последовательности?
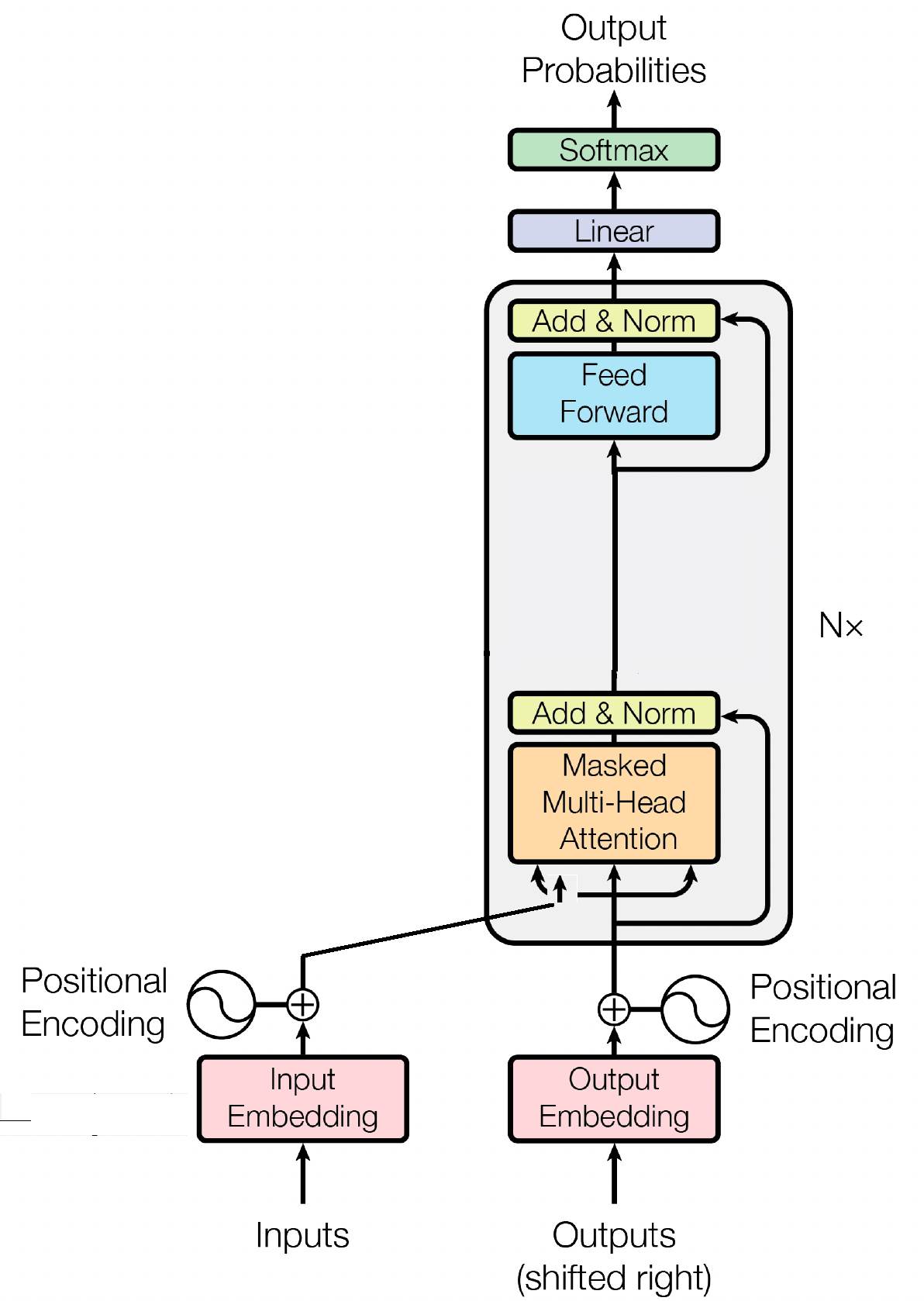
Я хочу написать GPT-подобный преобразователь для конкретной задачи генерации текста. GPT-подобные модели используют только блок декодера (в стеках) [1] . Я знаю, как закодировать все подмодули блока декодера, показанного ниже (от внедрения до слоя softmax) в Pytorch. Однако я не знаю, что мне следует предоставить в качестве входных данных. Там написано (на рисунке) «Выход сдвинут вправо».
Например, это мои данные (где < и > — токены sos и eos):
- <abcdefgh>
Что мне следует дать моей GPT-подобной модели, чтобы она правильно обучилась?
Кроме того, поскольку я не использую кодировщик, должен ли я по-прежнему вводить данные в многоголовочный блок внимания?
Извините, если мои вопросы покажутся немного глупыми, я новичок в трансформерах.
3 ответа
Входные данные для модели только для декодера, такой как GPT, обычно представляют собой последовательность токенов, как и в модели кодировщик-декодер. Однако разница заключается в том, как обрабатывается ввод.
В модели кодера-декодера входная последовательность сначала обрабатывается компонентом кодера, который создает представление входных данных фиксированного размера, часто называемое «вектором контекста». Вектор контекста затем используется компонентом декодера для генерации выходной последовательности.
Напротив, в модели, использующей только декодер, такой как GPT, отдельный компонент кодировщика отсутствует. Вместо этого входная последовательность напрямую подается в декодер, который генерирует выходную последовательность, обрабатывая входную последовательность с помощью механизмов самообслуживания.
В обоих случаях входная последовательность обычно представляет собой последовательность токенов, которые представляют обрабатываемые текстовые данные. Токенами могут быть слова, подслова или символы, в зависимости от конкретного подхода к моделированию и степени детализации обрабатываемых текстовых данных.
Ваш вопрос не глупый, описания модели трансформера иногда немного расплывчаты.
Когда GPT-x говорит, что использует архитектуру «только для декодера», это также означает, что в декодере отсутствует блок внимания кодера, поскольку нет кодера; см. изображение ниже.
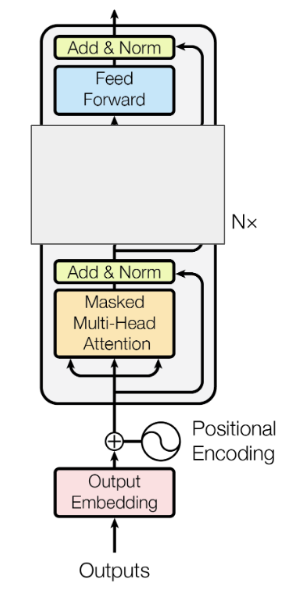
Если присмотреться, то теперь это похоже на кодер, верно? Таким образом, вы также можете сказать, что это архитектура «только для кодировщиков». Важным отличием является то, что вам по-прежнему требуется маска причинного внимания (т. е. маска внимания «не смотреть вперед»), которая используется в декодере по умолчанию.
Если я не ошибаюсь, стек только для кодировщика должен выглядеть примерно так.