Как я могу использовать снижающуюся скорость обучения в DeepSpeed?
Я тренирую Долли 2.0.
Когда я это сделаю, я получаю следующий вывод из терминала:
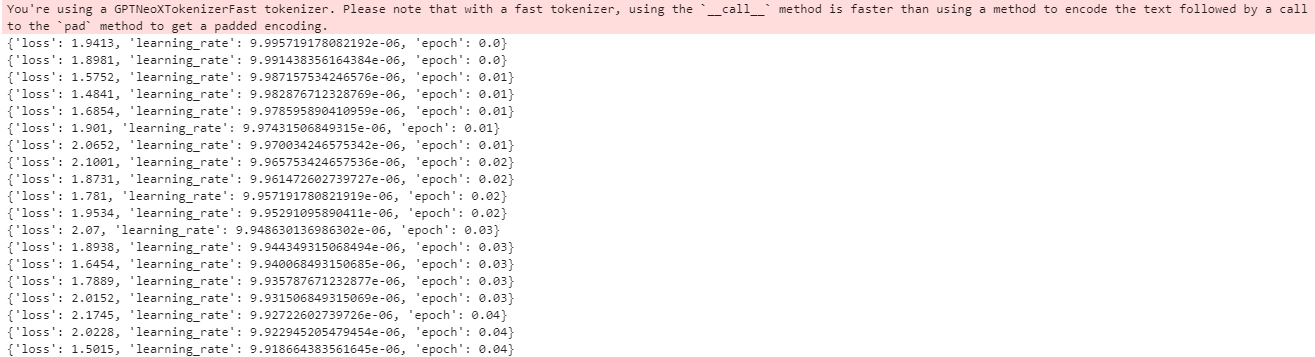
Если я использую DeepSpeed для выполнения этого обучения, я отмечаю, что скорость обучения не улучшилась:
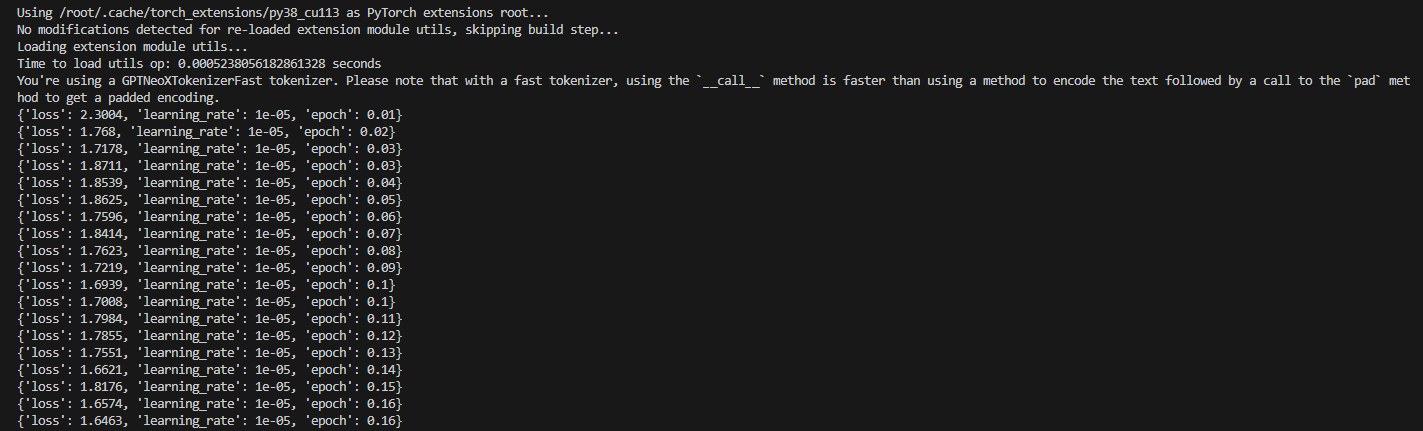
Почему скорость обучения не улучшилась?
Это конфигурация DeepSpeed, которую я использую
{
"fp16": {
"enabled": false
},
"bf16": {
"enabled": true
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
1 ответ
Согласно документам , вы можете использовать затухающую скорость обучения следующим образом:
"optimizer": {
"type": "Adam",
"params": {
"lr": 0.001,
"betas": [
0.8,
0.999
],
"eps": 1e-8,
"weight_decay": 3e-7
}
}
Имейте в виду, что по умолчанию скорость обучения снижается каждую эпоху , а не каждый шаг, согласно этому ответу GitHub.