Бессерверный запрос Synapse в виде секционированных данных Delta Lake отображает дублированные данные
У нас есть процесс elt для хранения данных, разделенных по годам, в дельта-озере, обработанных с помощью Databricks. В Databricks запрошенное расположение отображает данные правильно, без дублирования и изменения общего количества. Когда я создаю представление с помощью Synapse Serverless, одни и те же секционированные данные отображаются с дубликатами после обновления данных, а когда данные создаются впервые, никаких проблем не возникает. Я устранил неполадки и обнаружил, что это происходит только при использовании представлений для секционированных данных после обновления. Если вы используете внешнюю таблицу без указания раздела, результаты также будут правильными.
Обзор секционированных данных Delta Lake

Данные Databricks читаются правильно.
select count(*) from mytable --407,421
О бессерверном Synapse
CREATE VIEW MY_TABLE_VIEW AS
SELECT *,
results.filepath(1) as [Year]
FROM
OPENROWSET(
BULK 'mytable/Year=*/*.parquet',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'PARQUET'
)
WITH(
[param1] nvarchar(4000),
[param2] float,
[PKCOLUMNS] nvarchar(4000)
) AS [results]
GO
select PKCOLUMNS, count(*) from mytable
group by PKCOLUMNS
having count(*)>1 --duplicates
GO
select PKCOLUMNS, count(*) from mytable
group by PKCOLUMNS
having count(*)>1 --814,842
1 ответ
Проблема связана с представлением, созданным в Synapse Serverless.
Вместо использования «OPENROWSET» для прямого доступа к файлам Delta Lake вы можете попробовать создать пример внешней таблицы (EXT.EDW_Table1) в Synapse, которая указывает на файлы Delta Lake.
Таким образом, вы можете получить метаданные Delta Lake для автоматического разделения данных и обеспечения правильного обновления разделов при изменении данных.
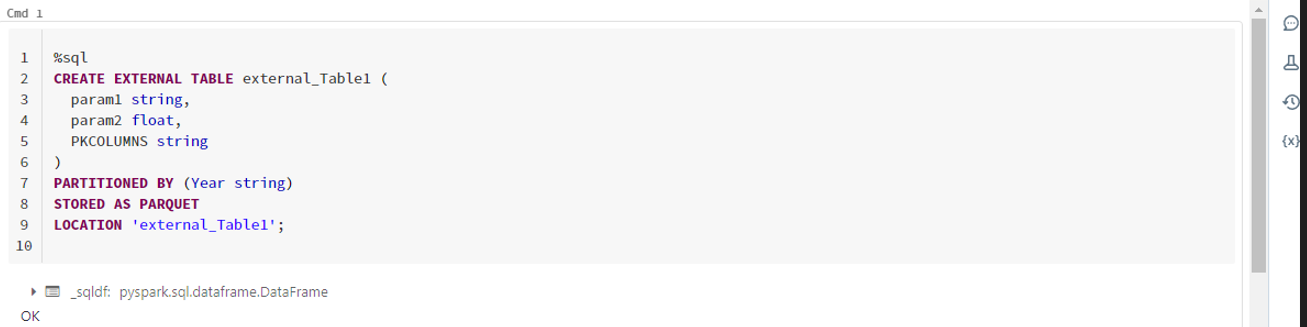
Шаг 1:
CREATE VIEW
CREATE EXTERNAL TABLE external_Table1
param1 string,
param2 float,
PKCOLUMNS string
)
PARTITIONED BY (Year string)
STORED AS PARQUET
LOCATION 'external_Table1
На шаге 1 файлы дельта-озера (паркета) сохраняются в «external_Table1» и разделяются по столбцу «ГОД».
Шаг 2:
Попробуйте SELECT, чтобы проверить наличие дубликатов в представлении.
SELECT PKCOLUMNS, COUNT(*) FROM external_Table1
GROUP BY PKCOLUMNS HAVING COUNT(*) > 1;

Если после обновления вы по-прежнему видите повторяющиеся значения. Тир использует операцию ВАКУУМ над файлами озера Дельта. Шаг 3:
%sql
VACUUM external_Table1;
Обратите внимание, что выполнение операции ВАКУУМ может занять некоторое время в зависимости от размера ваших данных.