Вопросы о распределенной точной настройке модели трансформаторов (chatglm) с помощью Accelerate в графических процессорах Kaggle
Я пытаюсь настроить модель Chatglm-6b, используя LoRA с трансформаторами и peft в графических процессорах Kaggle (2*T4). Структура модели:
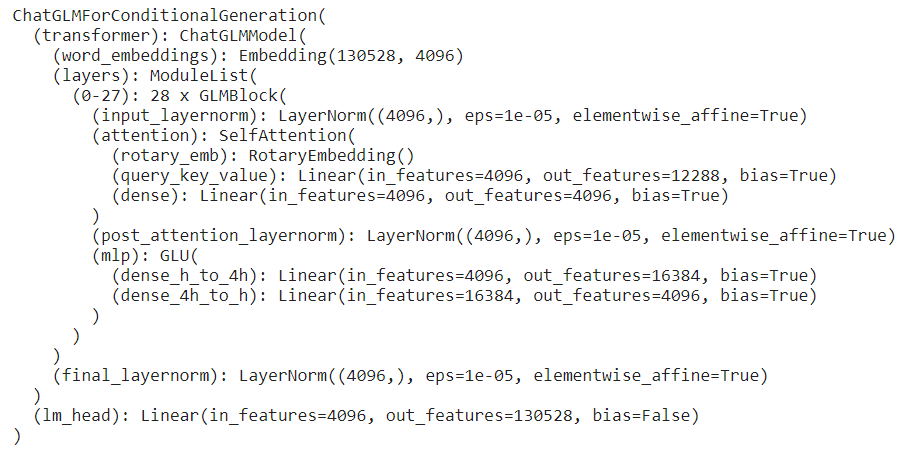
Традиционный метод загрузки (AutoModel.from_pretrained) требует сначала загрузить саму модель (15 ГБ) в ЦП, тогда как память ЦП в Kaggle составляет 13 ГБ, и модель не может быть загружена.
Таким образом, я использовал функцию load_checkpoint_and_dispatch() Accelerate для загрузки модели:
from transformers import AutoTokenizer, AutoModel, AutoConfig
from accelerate import load_checkpoint_and_dispatch, init_empty_weights
from huggingface_hub import snapshot_download
FilePath = snapshot_download(repo_id='THUDM/chatglm-6b')
config = AutoConfig.from_pretrained(FilePath, load_in_8bit=True, trust_remote_code=True)
with init_empty_weights():
model = AutoModel.from_config(config, trust_remote_code=True).half()
model = load_checkpoint_and_dispatch(
model, FilePath, device_map='auto', no_split_module_classes=["GLMBlock"]
)
С помощью этого метода модель можно успешно загрузить как в ЦП, так и в графические процессоры.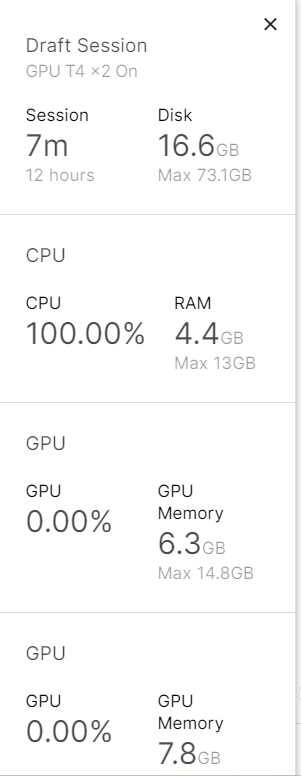
Затем к адаптерам LoRA добавили пефт.
from peft import get_peft_model, LoraConfig, TaskType
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False, r=32, lora_alpha=32, lora_dropout=0.1, bias='none',
# ['dense','dense_h_to_4h','dense_4h_to_h'] # 'query_key_value',
target_modules=['query_key_value',],
)
model = get_peft_model(model, peft_config)
Теперь модель может генерировать выходные данные напрямую с помощью
outputs = model(**tokenizer(['Hello world!'], return_tensors='pt).to(model.device))
Однако после использования Accelerator.prepare() для переноса модели, загрузчика данных и т. д. я получил ошибку RuntimeError.
accelerator = Accelerator()
train_dataloader, val_dataloader, model, optimizer = \
accelerator.prepare(train_dataloader, val_dataloader, model, optimizer)
train_loss = []
epoch_correct_num, epoch_total_num = 0, 0
model.train()
for batch in tqdm(train_dl):
labels = batch['labels']
outputs = model(**batch)
loss, logits = outputs.loss, outputs.logits
optim.zero_grad()
# loss.backward()
accelerator.backward(loss)
grad_norm = torch.nn.utils.clip_grad_norm_(model.parameters(), 2.0)
optim.step()
scheduler.step()

Есть ли какие-то методы решения этой проблемы?