langchain векторный магазин: вопрос и ответ из одного встраивания в векторный магазин
Я работал над созданием векторного хранилища из серии абзацев текстового документа. Текст документа не зря разбит на непересекающиеся абзацы, поскольку они представляют разную информацию. В эти абзацы включены метаданные.
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.schema import Document
import time
paragraphs_document_list = []
for paragraph in paragraph_list:
documents_list.append(Document(page_content=paragraph,
metadata=dict(paragraph_id=paragraph_id,
page=pageno))
db = FAISS.from_documents(documents = paragraphs_document_list,
embedding = OpenAIEmbeddings(model="gpt-4")
)
Обычно я могу запросить общее содержание моего документа, задав вопрос о нем в целом.
qa_chain = RetrievalQA.from_chain_type(
llm=ChatOpenAI(temperature = 0.0, model='gpt-4'),
chain_type="stuff",
retriever=db_test.as_retriever(),
verbose=False
)
label_output = qa_chain.run(query="What is this document about?")
Однако вместо этого я хотел бы получить различные вложения в моем векторном хранилище FAISS, а затем запросить их по отдельности, используя в качестве запроса что-то вроде «О чем этот абзац?».
Есть ли возможность запросить конкретное вложение или использовать в качестве средства извлечения одно конкретное вложение? В любом случае я хотел бы получить доступ к исходному абзацу, который я запрашиваю, вместе с его метаданными.
Я попробовал фильтровать с использованием метаданных, чтобы ответить на основе определенного абзаца:
filter_dict = {"paragraph_id":19, "page":5}
results = db.similarity_search(query, filter=filter_dict, k=1, fetch_k=1)
1 ответ
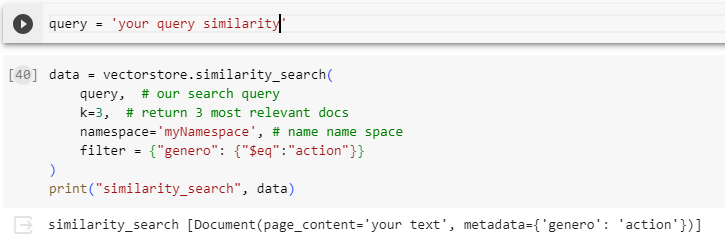
если вы используете сосновую шишку doc= https://docs.pinecone.io/docs/metadata-filtering
в шишке твой вектор
векторное хранилище = Сосновая шишка (индекс, embed.embed_query, «текст»)