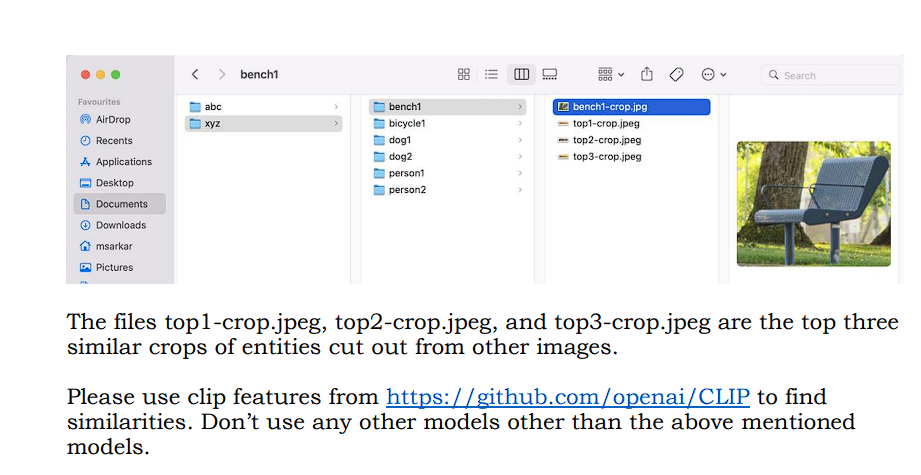
Yolo и Clip находят топ-3 похожих изображений
import os
import clip
import numpy as np
from PIL import Image
from tqdm import tqdm
from typing import List, Dict
import concurrent.futures
import pickle
import time
def tokenize_text(text: List[str], tokenizer):
"""
Tokenize the input text using the CLIP tokenizer.
Parameters:
text (List[str]): List of input texts to be tokenized.
tokenizer (clip.simple_tokenizer.SimpleTokenizer): The CLIP tokenizer.
Returns:
List of tokenized texts.
"""
return [tokenizer.encode(t) for t in text]
def cosine_similarity(a, b):
"""
Calculate the cosine similarity between two vectors.
Parameters:
a (numpy.ndarray): The first vector.
b (numpy.ndarray): The second vector.
Returns:
float: The cosine similarity between the two vectors.
"""
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
def process_image(image_path, entity, tokenizer, preprocess, model):
"""
Process a single image and calculate the similarity score with a given entity.
Parameters:
image_path (str): The file path of the image to be processed.
entity (str): The entity to compare the image with.
tokenizer (clip.simple_tokenizer.SimpleTokenizer): The CLIP tokenizer.
preprocess (Callable): Image preprocessing function from the CLIP model.
model (clip.model.CLIP): The CLIP model.
Returns:
Tuple: The image path and the similarity score between the image and entity.
"""
with Image.open(image_path) as image:
text = tokenize_text([entity], tokenizer)
image_input = preprocess(image).unsqueeze(0)
image_features = model.encode_image(image_input).detach().numpy()
text_features = model.encode_text(text).detach().numpy()
similarity = cosine_similarity(image_features, text_features)
return image_path, similarity
def compute_embeddings(all_images_folder, model, tokenizer, preprocess):
"""
Pre-compute embeddings for all images and cache them for faster retrieval.
Parameters:
all_images_folder (str): The folder containing all images.
model (clip.model.CLIP): The CLIP model.
tokenizer (clip.simple_tokenizer.SimpleTokenizer): The CLIP tokenizer.
preprocess (Callable): Image preprocessing function from the CLIP model.
"""
image_files = [file for file in os.listdir(all_images_folder) if file.endswith(".jpg")]
embeddings = {}
for image_file in tqdm(image_files, desc="Computing Embeddings"):
image_path = os.path.join(all_images_folder, image_file)
with Image.open(image_path) as image:
image_input = preprocess(image).unsqueeze(0)
image_features = model.encode_image(image_input).detach().numpy()
embeddings[image_file] = image_features
with open('embeddings_cache.pkl', 'wb') as f:
pickle.dump(embeddings, f)
def find_closest_matches(tagged_images_folder: str, all_images_folder: str):
"""
Find the top 3 similar images for each entity and save them in respective folders.
Parameters:
tagged_images_folder (str): The folder containing tagged images for each entity.
all_images_folder (str): The folder containing all images.
Notes:
This function uses the CLIP model for image and text embeddings and the cosine similarity metric
to find the top 3 most similar images for each entity.
"""
model, preprocess = clip.load("ViT-B/32", jit=False)
tokenizer = clip.simple_tokenizer.SimpleTokenizer()
# Check if embeddings are cached
if os.path.exists('embeddings_cache.pkl'):
with open('embeddings_cache.pkl', 'rb') as f:
embeddings = pickle.load(f)
else:
compute_embeddings(all_images_folder, model, tokenizer, preprocess)
with open('embeddings_cache.pkl', 'rb') as f:
embeddings = pickle.load(f)
entity_folders = [folder for folder in os.listdir(tagged_images_folder) if os.path.isdir(os.path.join(tagged_images_folder, folder))]
for entity_folder in entity_folders:
entity_images_folder = os.path.join(tagged_images_folder, entity_folder)
entity_cropped_folder = os.path.join(all_images_folder, "results", entity_folder)
os.makedirs(entity_cropped_folder, exist_ok=True)
image_files = [file for file in os.listdir(entity_images_folder) if file.endswith((".jpg",".jpeg",".png"))]
# Initialize a dictionary to store similarity scores for each entity
entity_similarities = {}
# Process images and calculate similarity for each entity
with concurrent.futures.ProcessPoolExecutor() as executor:
future_to_path = {executor.submit(process_image, os.path.join(entity_images_folder, file), os.path.splitext(file)[0], tokenizer, preprocess, model): file for file in image_files}
for future in tqdm(concurrent.futures.as_completed(future_to_path), total=len(future_to_path), desc=f"Processing {entity_folder}"):
img_path, similarity = future.result()
entity = os.path.splitext(os.path.basename(img_path))[0]
# Add similarity score to the dictionary
if entity not in entity_similarities:
entity_similarities[entity] = []
entity_similarities[entity].append((img_path, similarity))
# Save the top 3 similar images for each entity in its respective folder
for entity, similarities in entity_similarities.items():
# Sort similarities for the current entity
similarities.sort(key=lambda x: x[1], reverse=True)
# Create a folder for the current entity if it doesn't exist
entity_output_folder = os.path.join(entity_cropped_folder, entity)
os.makedirs(entity_output_folder, exist_ok=True)
# Save the main image in the entity folder
main_image_path = os.path.join(entity_output_folder, "main_image.jpg")
main_image = Image.open(similarities[0][0])
main_image.save(main_image_path)
# Create a subfolder for similar images
similar_images_folder = os.path.join(entity_output_folder, "similar_images")
os.makedirs(similar_images_folder, exist_ok=True)
# Save the top 3 similar images (cropped out) in the similar_images subfolder
for i, (img_path, _) in enumerate(similarities[:3]):
similar_img = Image.open(img_path)
similar_img.save(os.path.join(similar_images_folder, f"top{i+1}-{os.path.basename(img_path)}"))
if __name__ == "__main__":
tagged_images_folder = r"c:\Users\amrit\Aryan\CS\python\Adobe hack-a-thon\Round 2 prep\Aithon\adobe_aithon_alpha\question1\All_Images"
all_images_folder = r"c:\Users\amrit\Aryan\CS\python\Adobe hack-a-thon\Round 2 prep\Aithon\adobe_aithon_alpha\question1\boxed_images"
start_time = time.time()
find_closest_matches(tagged_images_folder, all_images_folder)
end_time = time.time()
total_time = end_time - start_time
print(f"Total time taken: {total_time:.2f} seconds")
Код должен выводить изображения с этой файловой структурой.
boxed_images/results/entity_folder/main_image.jpg и boxed_images/results/entity_folder/similar_images/topX-image_name.jpg для каждого объекта.
Я пытаюсь оптимизировать код и сделать его быстрым, но на данный момент я просто хочу, чтобы код работал.
Это два изображения, откуда я взял вопросы