Извлеките 12-битные «слова» из необработанного файла данных ARINC.
Я пытаюсь декодировать и анализировать некоторые необработанные данные, закодированные в формате ARINC 573. Это означает, что значения хранятся в 12-битных словах в потоке данных. Один кадр данных содержит 4 секунды данных, разделенных на 4 подкадра. Каждый подкадр содержит 64 слова, из которых первое всегда является выделенным синхрословом. Для первого субкадра синхрослово равно 0x247, для второго 0x5B8, для третьего 0xA47 и для четвертого 0xDB8.
На компьютере файл данных представляет собой файл .TSC, который можно открыть с помощью блокнота, но я думаю, что он пытается декодировать его как символы ANSI, и в результате получается нечитаемая строка.
Обновлено: файл .TSC содержит заголовок с некоторой базовой информацией об устройстве сбора данных и некоторый код. Это выглядит как:
00-G 01-G 02-G 03-G 04-G 05-G 06-G 07-G
08-G 09-G 10-G 11-G 12-G 13-G 14-G 15-G
16-B 17-B 18-B 19-B 20-B 21-B 22-B 23-B
24-B 25-B 26-B 27-B 28-B 29-B 30-B 31-B
Part Number
Hardware Version
Software Version
Serial Number XXXX
Date of Manufacture 02/15/01
Checksum 362D
QAR Capacity 2
˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙˙THE TIME CHIP SERIAL NUMBER IS: 0000000000000000. THE CURRENT TIME STAMP IS: 0000000000. THE CODE ID IS: MQ06A411. END OF TIME STAMP.wŚô^ Ŕh wÖÇ8’0„ Ŕţr'w‰ôŕ
V w¨}8 °„ ţx'wŹä^ p wÔw8 °„ °ţu'w†„ p¸Ą wÄt8wź„ Ŕţxw‹ä^ a wÍw8•đ °ţu'w†ôŕ Y w¨ť8 0„ °ţuwŹä^ p wÉw8 °„ °ţtw‰ Gş wÄt8Zź °ţywŽT_ d wŇG8’đ„ °ţxw‰ôŔ
] w¨˝8 p„ ŔţzwŹt_ € wŇw8 p„ °ţzw‰P ¸Í wÄt8?ź„ °ţz'wŤt_ ŔfŕvËG8•0„ ŔţuGw‰ôŔ
@ Vŕv§ť8 đ„ Ŕţx'w’t_ € wćW8 đ„ Ŕţvw‡ đGŇ“%wÄ”8#ß„ Ŕţxw‰t_ f wÖw8•° Ŕţyw‡ôŔ ...
Конец обновленного раздела.
Я попробовал несколько основных конвертеров для преобразования файла в двоичный, но я думаю, что из-за 12-битной сегментации они не дают мне правильный двоичный поток данных. Как я могу извлечь этот файл в Excel, где каждое 12-битное слово помещается в отдельную ячейку?
Я не особо увлекаюсь программированием, просто хочу использовать данные из файлов для инженерных целей. Я также открыт для других сред, таких как Python или C#.
2-е обновление: после того, как я открыл файл в двоичном редакторе и оказалось, что он имеет обратный порядок байтов, я нашел слова синхронизации и шаблон подкадра.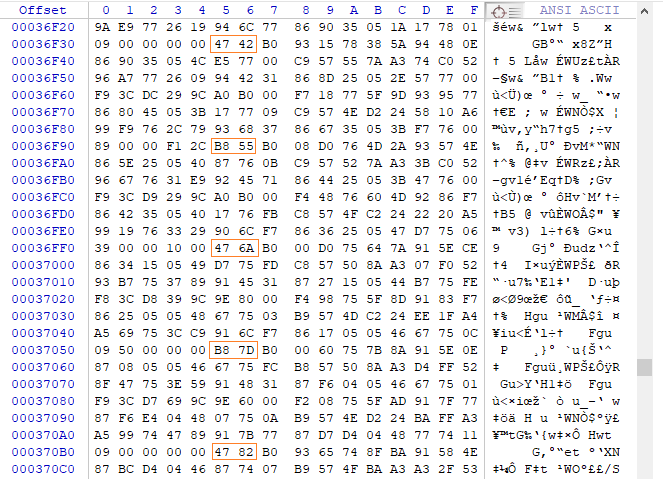
Итак, теперь я могу немного конкретизировать свой вопрос: могу ли я использовать Excel, чтобы открыть этот файл и поместить шестнадцатеричные значения в отдельные ячейки, как это делает двоичный редактор?