Многократный вложенный запрос с помощью scrapy
Я пытаюсь собрать информацию о расписании самолетов на сайте www.flightradar24.com для исследовательского проекта.
Иерархия файла json, которую я хочу получить, выглядит примерно так:
Object ID
- country
- link
- name
- airports
- airport0
- code_total
- link
- lat
- lon
- name
- schedule
- ...
- ...
- airport1
- code_total
- link
- lat
- lon
- name
- schedule
- ...
- ...
Country а также Airport хранятся с использованием элементов, и, как вы можете видеть в файле JSON CountryItem (ссылка, имя атрибута), наконец, хранить несколько AirportItem (code_total, ссылка, лат, долг, имя, расписание):
class CountryItem(scrapy.Item):
name = scrapy.Field()
link = scrapy.Field()
airports = scrapy.Field()
other_url= scrapy.Field()
last_updated = scrapy.Field(serializer=str)
class AirportItem(scrapy.Item):
name = scrapy.Field()
code_little = scrapy.Field()
code_total = scrapy.Field()
lat = scrapy.Field()
lon = scrapy.Field()
link = scrapy.Field()
schedule = scrapy.Field()
Вот мой скрап-код AirportsSpider сделать это:
class AirportsSpider(scrapy.Spider):
name = "airports"
start_urls = ['https://www.flightradar24.com/data/airports']
allowed_domains = ['flightradar24.com']
def clean_html(self, html_text):
soup = BeautifulSoup(html_text, 'html.parser')
return soup.get_text()
rules = [
# Extract links matching 'item.php' and parse them with the spider's method parse_item
Rule(LxmlLinkExtractor(allow=('data/airports/',)), callback='parse')
]
def parse(self, response):
count_country = 0
countries = []
for country in response.xpath('//a[@data-country]'):
if count_country > 5:
break
item = CountryItem()
url = country.xpath('./@href').extract()
name = country.xpath('./@title').extract()
item['link'] = url[0]
item['name'] = name[0]
count_country += 1
countries.append(item)
yield scrapy.Request(url[0],meta={'my_country_item':item}, callback=self.parse_airports)
def parse_airports(self,response):
item = response.meta['my_country_item']
airports = []
for airport in response.xpath('//a[@data-iata]'):
url = airport.xpath('./@href').extract()
iata = airport.xpath('./@data-iata').extract()
iatabis = airport.xpath('./small/text()').extract()
name = ''.join(airport.xpath('./text()').extract()).strip()
lat = airport.xpath("./@data-lat").extract()
lon = airport.xpath("./@data-lon").extract()
iAirport = AirportItem()
iAirport['name'] = self.clean_html(name)
iAirport['link'] = url[0]
iAirport['lat'] = lat[0]
iAirport['lon'] = lon[0]
iAirport['code_little'] = iata[0]
iAirport['code_total'] = iatabis[0]
airports.append(iAirport)
for airport in airports:
json_url = 'https://api.flightradar24.com/common/v1/airport.json?code={code}&plugin\[\]=&plugin-setting\[schedule\]\[mode\]=&plugin-setting\[schedule\]\[timestamp\]={timestamp}&page=1&limit=50&token='.format(code=airport['code_little'], timestamp="1484150483")
yield scrapy.Request(json_url, meta={'airport_item': airport}, callback=self.parse_schedule)
item['airports'] = airports
yield {"country" : item}
def parse_schedule(self,response):
item = response.request.meta['airport_item']
jsonload = json.loads(response.body_as_unicode())
json_expression = jmespath.compile("result.response.airport.pluginData.schedule")
item['schedule'] = json_expression.search(jsonload)
Пояснение:
В моем первом разборе я вызываю запрос для каждой ссылки на страну, которую нашел
CountryItemсоздан с помощьюmeta={'my_country_item':item}, Каждый из этих запросов обратного вызоваself.parse_airportsНа моем втором уровне разбора
parse_airports, я ловлюCountryItemсоздан с использованиемitem = response.meta['my_country_item']и я создаю новый предметiAirport = AirportItem()для каждого аэропорта я нашел на этой странице страны. Теперь я хочу получитьscheduleинформация для каждогоAirportItemсоздан и хранится вairportsсписок.На втором уровне разбора
parse_airportsя запускаю цикл поairportsловитьscheduleинформация с использованием нового запроса. Поскольку я хочу включить эту информацию о расписании в свой AirportItem, я включаю этот элемент в метаинформациюmeta={'airport_item': airport}, Обратный вызов этого запроса запускаparse_scheduleНа третьем уровне разбора
parse_schedule, я добавляю информацию о расписании, собранную с помощью скрапа, в AirportItem, ранее созданныйresponse.request.meta['airport_item']
Но у меня есть проблема в моем исходном коде, scrap правильно удаляет всю информацию (страна, аэропорты, расписание), но мое понимание вложенного элемента, кажется, не правильно. Как вы можете видеть, JSON, который я произвел, содержит country > list of (airport), но нет country > list of (airport > schedule )
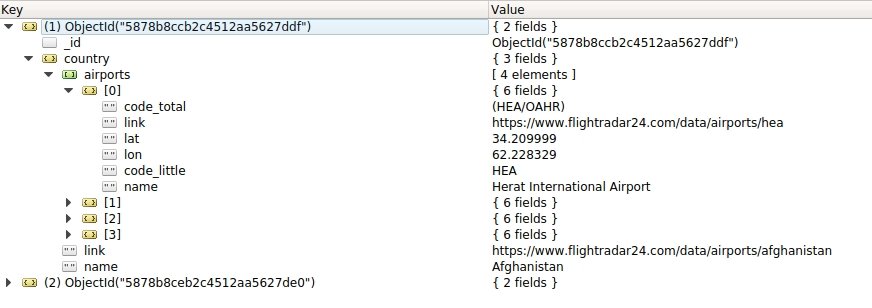
Мой код находится на GitHub: https://github.com/IDEES-Rouen/Flight-Scrapping
1 ответ
Проблема заключается в том, что вы разветвляете свой предмет, где, согласно вашей логике, вам нужен только 1 предмет на страну, поэтому вы не можете выдать несколько предметов в любой момент после анализа страны. То, что вы хотите сделать, это сложить их все в один предмет.
Для этого вам нужно создать цикл синтаксического анализа:
def parse_airports(self, response):
item = response.meta['my_country_item']
item['airports'] = []
for airport in response.xpath('//a[@data-iata]'):
url = airport.xpath('./@href').extract()
iata = airport.xpath('./@data-iata').extract()
iatabis = airport.xpath('./small/text()').extract()
name = ''.join(airport.xpath('./text()').extract()).strip()
lat = airport.xpath("./@data-lat").extract()
lon = airport.xpath("./@data-lon").extract()
iAirport = dict()
iAirport['name'] = 'foobar'
iAirport['link'] = url[0]
iAirport['lat'] = lat[0]
iAirport['lon'] = lon[0]
iAirport['code_little'] = iata[0]
iAirport['code_total'] = iatabis[0]
item['airports'].append(iAirport)
urls = []
for airport in item['airports']:
json_url = 'https://api.flightradar24.com/common/v1/airport.json?code={code}&plugin\[\]=&plugin-setting\[schedule\]\[mode\]=&plugin-setting\[schedule\]\[timestamp\]={timestamp}&page=1&limit=50&token='.format(
code=airport['code_little'], timestamp="1484150483")
urls.append(json_url)
if not urls:
return item
# start with first url
next_url = urls.pop()
return Request(next_url, self.parse_schedule,
meta={'airport_item': item, 'airport_urls': urls, 'i': 0})
def parse_schedule(self, response):
"""we want to loop this continuously for every schedule item"""
item = response.meta['airport_item']
i = response.meta['i']
urls = response.meta['airport_urls']
jsonload = json.loads(response.body_as_unicode())
item['airports'][i]['schedule'] = 'foobar'
# now do next schedule items
if not urls:
yield item
return
url = urls.pop()
yield Request(url, self.parse_schedule,
meta={'airport_item': item, 'airport_urls': urls, 'i': i + 1})