Rio и Haven случайным образом интерпретируют NA в столбце даты как 1582-10-14 при импорте из SPSS
Я импортирую данные из SPSS (файл сохранения). В этом наборе данных есть несколько столбцов дат, некоторые из которых содержат ячейки с отсутствующими значениями. Все столбцы даты импортируются как переменные даты в R, пока все хорошо. Все записи дат из SPSS корректно импортируются в R, пока все хорошо. Однако некоторые из отсутствующих значений в SPSS интерпретируются как 1582-10-14 при импорте в R. Я понимаю, что это начало григорианского календаря, поэтому я подумал, что, возможно, некоторые из ячеек в SPSS равны 0 вместо NA, но при проверке указанных ячеек они действительно пусты и выглядят точно так же, как и другие пустые ячейки, которые правильно импортированы как NA в R.
Мне жаль, что я не могу придумать воспроизводимый пример, и я не могу поместить сюда свой файл SPSS по соображениям целостности.
Я попытался импортировать с помощью rio (import_list) и гавань (read_sav), и одни и те же ячейки интерпретируются как 1582-10-14 при использовании обоих методов. Может быть, это не случайно и в файле SPSS есть какие-то скрытые данные, не видимые в интерфейсе SPSS?
Любая идея, почему я получаю эту ошибку? Может ли это быть ошибкой? Мой опыт, однако, что это редко. Кто-нибудь еще испытал это?
Возможным решением было бы просто удалить все записи 1582-10-14 в R, но я хотел бы знать причину, по которой это произошло. Что делать, если другие данные, импортированные из SPSS, неверны?
Изменить:этот пост был предложен в качестве решения, а это не так. Этот пост касается импорта R дат из SPSS в виде абсолютных чисел в секундах от 1582-10-14 и того, как преобразовать эти значения в фактические даты, если я правильно понимаю. Этот пост касается R, неправильно интерпретирующего некоторые отсутствующие значения столбца даты SPSS как 1582-10-14.
Вот скриншот того, как данные выглядят в SPSS иdput()того, как это выглядит после импорта в R.
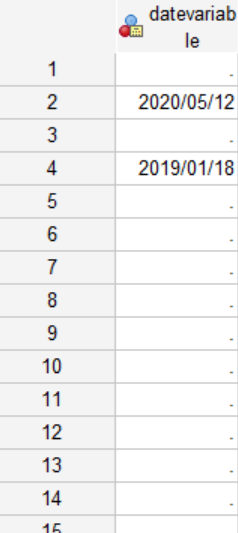
datetest <- structure(list(datevariable = structure(c(NA, 18394,
NA, 17914, -141428, -141428, NA, -141428, NA, NA, NA,
-141428, NA, NA, -141428, -141428, NA, NA, NA, NA, NA,
NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 17765, NA, NA,
NA, NA, NA, NA, NA, -141428, NA, NA, NA, NA, NA, NA, NA,
19278, NA, NA, NA, NA, NA, NA, NA, 19121, NA, NA, NA,
NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,
NA, NA, NA, NA), label = "datevariable", class = "Date", format.spss = "SDATE10")),
class = c("tbl_df", "tbl", "data.frame"), row.names = c(NA, -77L))
Как видите, номера строк 2 и 4 импортированы правильно. Отсутствующие значения строк 5,6,8,12,15... импортируются как 1582-10-14.
1 ответ
У меня есть неполный и, возможно, неудовлетворительный ответ.
Я скачал ваш файл и запустил следующий код:
library(foreign)
library(rio)
x1 <- read.spss("spss_test.sav")
x2 <- rio::import("spss_test.sav")
x3 <- haven::read_spss("spss_test.sav")
Фактически,rioэто просто оболочка для кода вhavenили (альтернативно, если требуется)foreignпакеты, так чтоx2является излишним ... Я проверил результаты, используяprint_hex()функцию, определенную ниже, и просмотр файла в "hexl-режиме" в Emacs (думаю, вы можете найти другие шестнадцатеричные редакторы в Интернете и т. д.). Преимущество сравненияforeign::read.spss()иhaven::read_spss()в том, чтоread.spssна самом деле меньше обрабатывает данные (создавая странные длинные числа, которые затем можно преобразовать в даты), что немного облегчает понимание того, что происходит.
Глядя на результаты, сравнивая первые несколько элементовx1[[i]](числовое значение);print_hex(x1[[i]])(основное шестнадцатеричное представление); иx3[[i]](значение даты), мы получаем
- элементы 1 и 3: нет данных, 7ff00000000007a2, нет данных
- элемент 2: 13808620800, 4209b876a8000000, 12 мая 2020 г.
- элемент 4: 13767148800, 4209a4b028000000, 18 января 2019 г.
- элемент 5: 0, 0, 1582-10-14
Так что определенно дело в том, что некоторые пропущенные значения кодируются SPSS как ноль, а некоторые какNAценить. К сожалению, почему отсутствующие значения кодируются по-разному, для меня загадка.
Я пытался посмотреть дамп необработанного шестнадцатеричного кода, но это болезненно и не очень помогает. В конце строки 2 ниже вы можете увидеть шестнадцатеричное значение, соответствующее элементу 2, закодированное как00 0000 a876 b809 42, то есть в обратном обратном порядке , т.е. начните с последней пары (42) и читайте каждую пару справа налево (09, b8, 76...). Значение элемента 4 кажется сразу после него (конец строки 2, начало строки 3). Это то, где я теряюсь, потому что я не знаю, какое сжатие/другая магия выполняется в кодировке файла...
01 0000 5554 462d 38e7 0300 0000 0000 00ff ..UTF-8.........
02 000001f0: fdff fd64 64ff 6400 0000 a876 b809 4200 ...dd.d....v..B.
03 00000200: 0000 28b0 a409 42ff ffff 64ff ff64 64ff ..(...B...d..dd.
04 00000210: ffff ffff ffff ffff ffff ffff ffff fd00 ................
05 00000220: 0000 ac8c 9e09 42ff ffff ffff ffff 64ff ......B.......d.
Rcpp::cppFunction('void print_hex(double x) {
uint64_t y;
static_assert(sizeof x == sizeof y, "Size does not match!");
std::memcpy(&y, &x, sizeof y);
Rcpp::Rcout << std::hex << y << std::endl;
}', plugins = "cpp11", includes = "#include <cstdint>")