Нужен ли Provisioned IOPS для экземпляра RDS, который использует 60 IOPS в соответствии с мониторингом?
У нас есть экземпляр PostgreSQL, обслуживающий десятки запросов в секунду.
- Тип экземпляра: db.m3.2xlarge
- IOPS, обеспеченный экземпляром (SSD): 1000
- Размер хранилища экземпляров: 100 ГБ, размер базы данных составляет около 5-10 ГБ.
Он обслуживает сотни клиентов одновременно с запросами на чтение и запись. Тем не менее, когда мы смотрим на Cloudwatch Monitoring, он показывает IOPS в диапазоне 20-60.
И чтение iOPS составляет около 0!
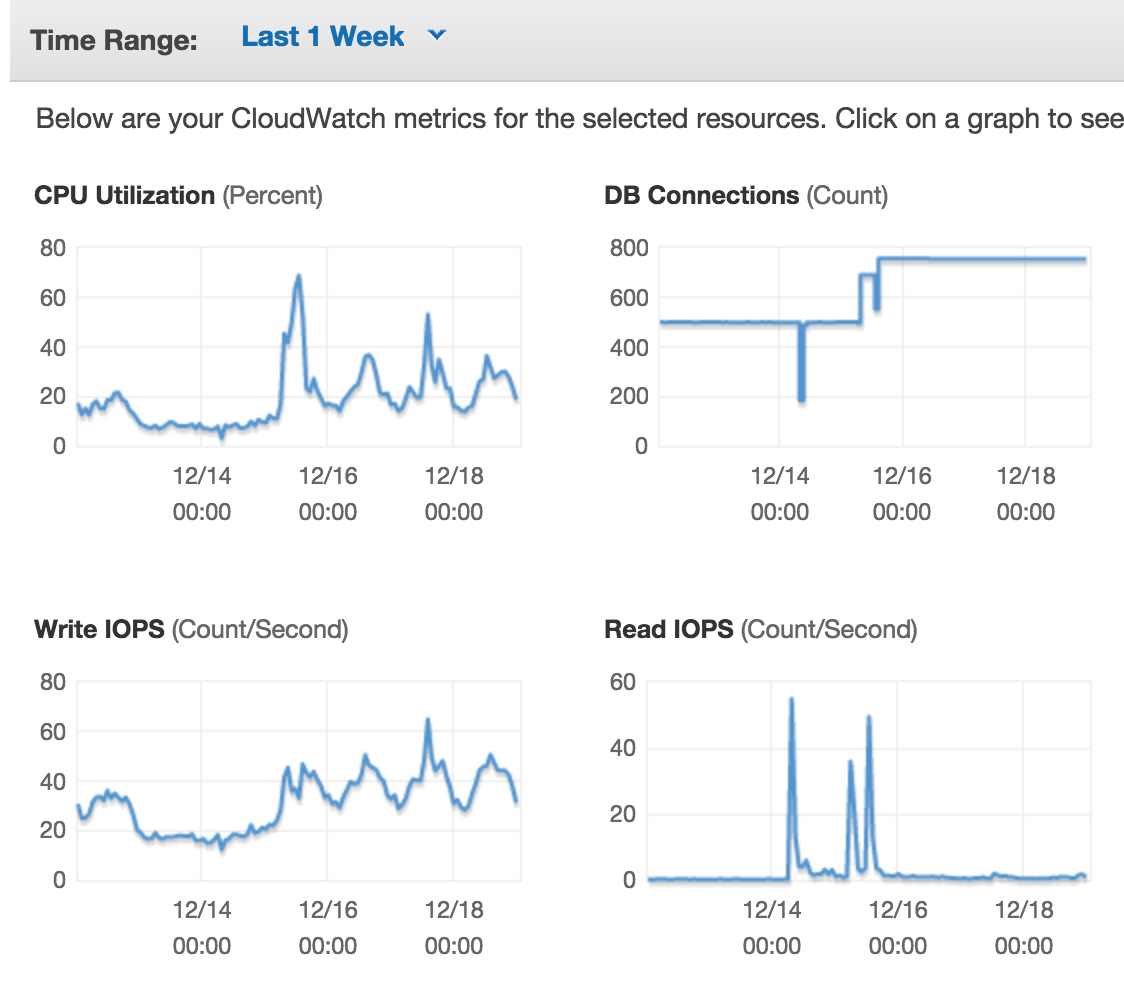
Это не может быть правильно с сотнями соединений и клиентами, выполняющими запросы чтения / записи все время? Конфигурация Postgres является стандартной, мы не отключали fsync.
Кэш настолько эффективен, что IOPS не является фактором с размером базы данных 5 ГБ? Или неверная консоль мониторинга AWS?
Плата за 1000 IOPS обойдется в 300 долларов за этот экземпляр БД. И минимальное количество IOPS, которое вы можете купить, составляет 1000.
Мне интересно, можем ли мы обойтись без IOPS?
- Или мониторинг AWS не правильный?
- Или 20 IOPS, которые мы имеем сейчас, снизят производительность сервера, если у нас будет не IOPS сервер?
- Или с базой данных 5 ГБ она в основном помещается в кэш, и IOPS не является фактором?
2 ответа
@CraigRinger правильный. Если ваш набор данных достаточно мал, чтобы полностью поместиться в памяти, вам не понадобятся подготовленные IOPS, поскольку трафик вставки / обновления и журналы являются единственными потребляющими IOPS.
Но если кто-то найдет эту тему, вот как выглядит CloudWatch, когда вы исчерпали свои кредиты GP2. Как вы можете видеть, диаграммы IOPS для чтения и записи мало что нам говорят, но диаграммы задержки чтения / записи показывают огромные всплески.
Для контекста, это 2 недели реплики чтения PostgreSQL, используемой для аналитики. Переход от 100 ГБ GP2 (300 базовых операций ввода-вывода в секунду, 11,50 долл. США в месяц) к 100 ГБ ввода-вывода 1 (1000 операций ввода-вывода в секунду, 112,50 долл. США в месяц) происходит примерно на 2/3 пути через эти графики (больше не возникает пиков задержки). Более дешевый вариант - увеличить объем памяти GP2. Предоставленные IOPS являются чрезмерно завышенными, но предсказуемое поведение во время тяжелых рабочих нагрузок в этом случае имело смысл.


Ваша БД почти полностью кешируется в оперативной памяти. (Вы можете подтвердить это с помощью pg_buffercache расширение). Эти цифры IOPS вполне ожидаемы. Я ожидал бы, что этот сервер будет в порядке без подготовленного IOPS.
Если вы перезапустите экземпляр, он будет некоторое время работать медленнее, поскольку он создаст резервную копию кеша, но 5 ГБ - это немного. Кроме того, наличие iops на самом деле усугубляет это, потому что, помимо установки минимальной скорости ввода / вывода, piops также устанавливает максимум. Это целевая ставка, а не минимальная.
В отличие от этого, обычные тома могут иметь намного более высокие скорости чтения, чем тома piops, поэтому они будут работать лучше, когда вы прогреваете кэш после перезагрузки.
КСТАТИ:
Перезапуск базы данных не сильно ее замедлит, поскольку ему нужно только прочитать данные из дискового кэша ОС обратно в shared_buffers. Только если вы перезапустите всю машину, некоторое время вы увидите замедление. Если вы хотите смоделировать это без перезапуска, вы можете использовать Linux drop_caches особенность:
echo 1 | sudo tee -a /proc/sys/vm/drop_caches
Это на самом деле хуже, чем ситуация после перезапуска, поскольку она также удаляет двоичные файлы и библиотеки из памяти. Поначалу система будет очень сильно загружаться, поскольку она читает часто используемые двоичные файлы и библиотеки, которые она выполняет, обратно в ОЗУ. Затем вы начнете видеть поведение восстановления кэша, как после перезагрузки.
Кроме того, у вас настроено слишком много соединений. Установите pgbouncer, поместите его перед базой данных и уменьшите ваши max_connections. Вы получите лучшую производительность.