Преобразование C# XML в документ Fast-Infoset неожиданно обрезает пробелы и символы CR
Мне нужно закодировать обычный XML-файл в XML-документ Fast Infoset. В пакете Nuget я установил пакет LiquidTechnologies.FastInfoset (единственный, который я нашел)
Мой документ XML для преобразования, как показано ниже
<?xml version="1.0" encoding="utf-8"?> <GomsStockRequest xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema" callerMethod="pushInfinityAllocatedStockLevel" transactionType="InventoryJob"> <stockRequestEntry> <productCode>100001</productCode> <availableQuantity>1</availableQuantity> <reservedQuantity>0</reservedQuantity> <inventoryType>Job_Import</inventoryType> </stockRequestEntry> </GomsStockRequest>
После transactionType="InventoryJob"> и перед дочерними элементами есть символы CR LF и пробелы. Моя целевая система использует Java, и они могут читать документы Fast Infoset, закодированные с помощью Java, следующим образом:
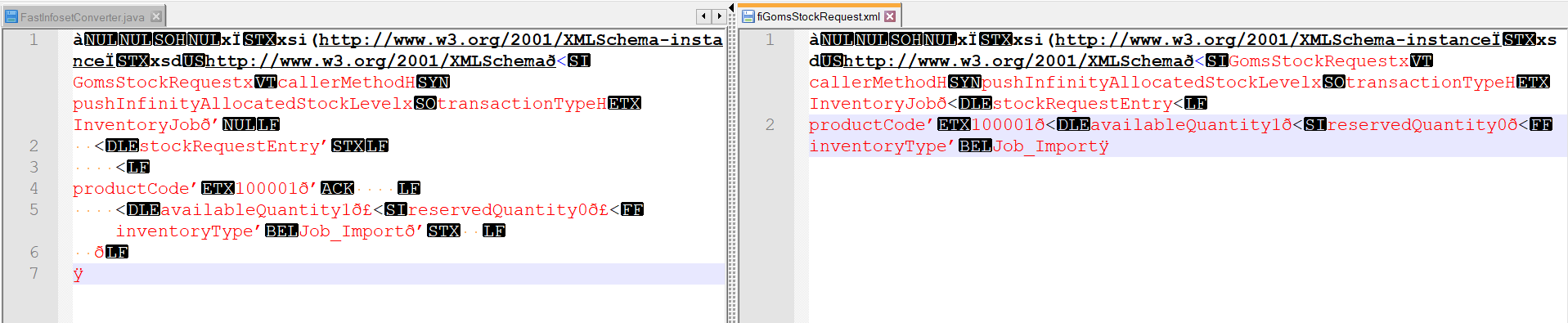
à � xÏ�xsi(http://www.w3.org/2001/XMLSchema-instanceÏ�xsd�http://www.w3.org/2001/XMLSchemað<�GomsStockRequestx�callerMethodH�pushInfinityAllocatedStockLevelx�transactionTypeH�InventoryJobð’ <�stockRequestEntry’� < productCode’�100001ð’� <�availableQuantity�1ð£<�reservedQuantity�0ð£<inventoryType’�Job_Importð’� ð� ÿ
который сохранил пробелы и, возможно, просто проигнорировал символ CR.
Однако для меня, используя С#, результат после записи документа Fast Infoset выглядит следующим образом:
à � xÏ�xsi(http://www.w3.org/2001/XMLSchema-instanceÏ�xsd�http://www.w3.org/2001/XMLSchemað<�GomsStockRequestx�callerMethodH�pushInfinityAllocatedStockLevelx�transactionTypeH�InventoryJobð<�stockRequestEntry< productCode’�100001ð<�availableQuantity�1ð<�reservedQuantity�0ð<inventoryType’�Job_Importÿ
что кажется, что пробел и символ CR обрезаны
Мои модели ниже
public class GomsStockRequest
{
[XmlAttribute("callerMethod")]
public string callerMethod { get; set; }
[XmlAttribute("transactionType")]
public string transactionType { get; set; }
public StockRequestEntry stockRequestEntry { get; set; }
}
public class StockRequestEntry
{
public string productCode { get; set; }
public int availableQuantity { get; set; }
public int reservedQuantity { get; set; }
public string inventoryType { get; set; }
}
Программа следующая:
var gomsstockrequest = new GomsStockRequest()
{
callerMethod = "pushInfinityAllocatedStockLevel",
transactionType = "InventoryJob",
stockRequestEntry = new StockRequestEntry()
{
productCode = "100001",
availableQuantity = 1,
reservedQuantity = 0,
inventoryType = "Job_Import"
}
};
var serializer = new XmlSerializer(typeof(GomsStockRequest));
XmlWriter fwriter = XmlWriter.Create(new FIWriter("fiGomsStockRequest.xml"));
serializer.Serialize(fwriter, gomsstockrequest);
У кого-нибудь есть опыт в этой кодировке?
Когда я просматриваю данные в Notepad++, разница такая же, как на скриншоте.
Пожалуйста, порекомендуйте. Спасибо
1 ответ
При использовании LiquidTechnologies.FastInfoset незначительные пробелы игнорируются при кодировании XML-данных как FastInfoset, поскольку они не имеют практического значения.
У FI Encoder нет возможности включить кодирование незначащих пробелов.
Если вам нужен форматированный XML-документ, вы можете отформатировать XML-данные после того, как они были декодированы FI с использованием классов Microsoft .Net Framework Xml.