Преобразование данных байтового типа из файла .tiff в PDF
TODO: преобразовать файл TIFF из URL в PDF
У меня есть файл на основе .tiff, который мне нужно загрузить/получить по URL-адресу. При попытке сохранить/загрузить этот файл в cwd он загружается, однако я не могу его открыть.
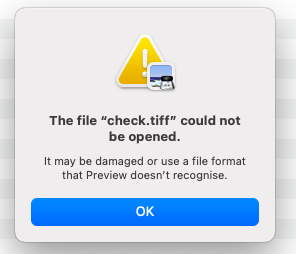
1. Команда для загрузки файла в cwd:
import urllib.request
sample_tiff_url = "https://www.gati.com/viewPOD2.jsp?dktno=322012982"
urllib.request.urlretrieve(sample_tiff_url, "check.tiff")
Моя причина для загрузки заключалась в том, что я загружу его локально, а затем конвертирую в pdf, используя эту тему.
2. Но поскольку файл не открывается в локальном формате, я попробовал другой подход, думая, что преобразую полученные байты ответа в PDF.
import requests
sample_tiff_url = "https://www.gati.com/viewPOD2.jsp?dktno=322012982"
resp = requests.get(sample_tiff_url,stream=True)
print(resp.content)
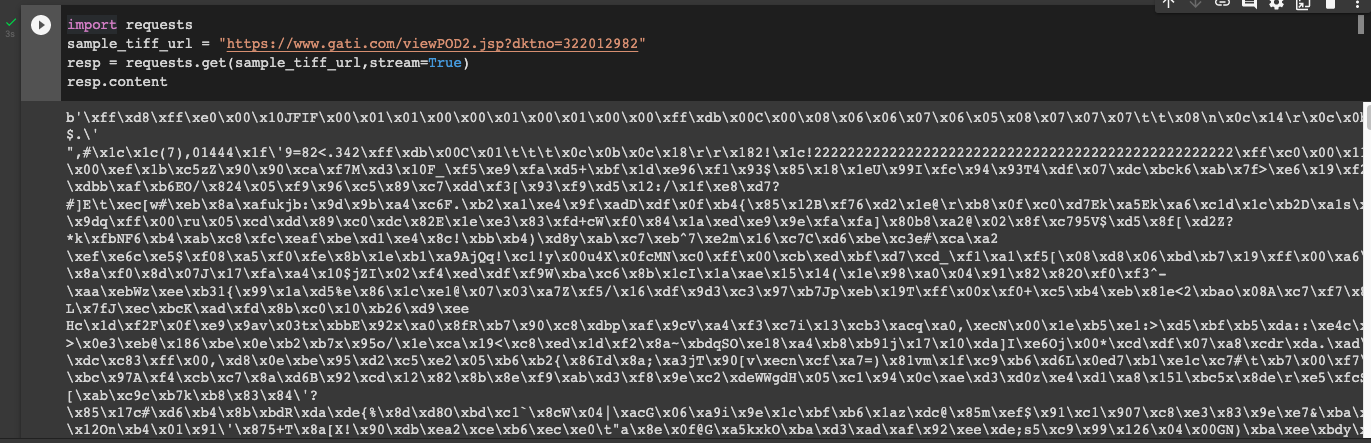
print(type(resp.content))
>>>bytes
3. Еще одна вещь, которую я пробовал:
import img2pdf
import base64
img_content = base64.b64decode(resp.content)
content = img2pdf.convert(img_content)
который дает следующую ошибку:
ImageOpenError: cannot read input image (not jpeg2000). PIL: error reading image: cannot identify image file <_io.BytesIO object at 0x7ff46368c410>
Наряду с этим;
from PIL import Image
import io
pil_bytes = io.BytesIO(resp.content)
pil_image = Image.open(pil_bytes)
Ошибка:
UnidentifiedImageError: cannot identify image file <_io.BytesIO object at 0x7ff4642e2650>
4. Наконец;
import requests
from PyPDF2 import PdfFileMerger, PdfFileReader
sample_tiff_url = ""https://www.gati.com/viewPOD2.jsp?dktno=322012982""
resp = requests.get(sample_tiff_url,stream=True)
PdfFileReader(resp.content)
который дает: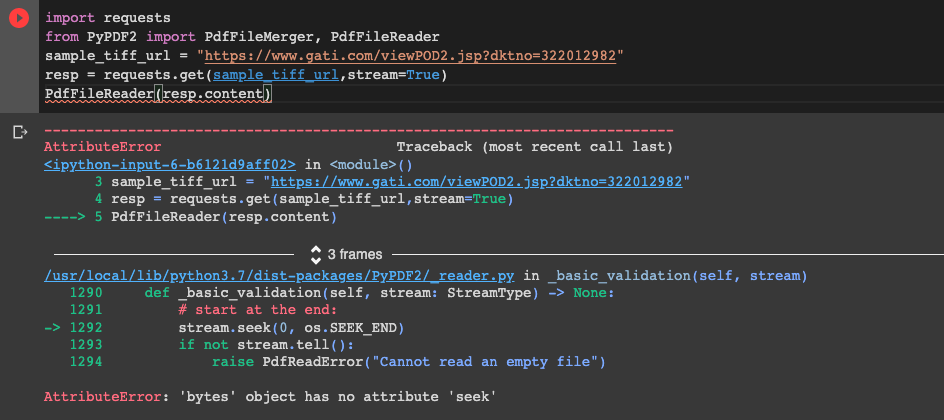
TBH, я не работал с библиотеками изображений и файлами, поэтому я не понимаю всех ошибок, которые я получаю.
TLDR; Либо загрузите файл .tiff на локальный сервер, либо как прочитать содержимое этого URL-адреса, указав данные типа байтов, и преобразовать/записать его в PDF.
1 ответ
import requests
import io
from PIL import Image
url = 'https://www.gati.com/viewPOD2.jsp?dktno=322012982'
r = requests.get(url)
pil_bytes = io.BytesIO(r.content)
pil_image = Image.open(pil_bytes)
# Needed to get around ValueError: cannot save mode RGBA
rgb = Image.new('RGB', pil_image.size)
rgb.paste(pil_image)
rgb.save('downloaded_image.pdf', 'PDF')