Сжатие больших файлов (> 15 ГБ) и загрузка на S3 без OOM
У меня есть одна проблема с памятью при архивировании больших файлов/папок (результат zip>15 ГБ) и загрузке их в хранилище S3. Я могу создать zip-файл на диске и добавить файлы/папки, загрузить этот файл с частями на S3. Но по моему опыту это не лучший способ решить эту проблему. Знаете ли вы какие-нибудь хорошие шаблоны для сжатия больших файлов/папок и загрузки их на S3 без проблем с памятью (например, OOM)? Было бы хорошо, если бы я мог добавить эти файлы/папки в S3 напрямую к какому-нибудь загруженному zip-архиву.
Заархивируйте файлы/папки на диск и загрузите этот zip-файл по частям на S3.
3 ответа
Вы можете использовать AWS Lambda для архивирования файлов перед их загрузкой в корзину S3. Вы даже можете настроить запуск Lambda и заархивировать файлы при загрузке . Вот пример Java -функции Lambda для сжатия больших файлов. Эта библиотека ограничена 10 ГБ, но это можно преодолеть с помощью EFS.
Временное хранилище Lambda ограничено 10 ГБ , но вы можете подключить хранилище EFS для обработки больших файлов. Стоимость должна быть близка к нулю, если вы удалите файлы после использования.
Кроме того, не забудьте использовать многокомпонентную загрузку при загрузке файла размером более 100 МБ на S3. Если вы используете SDK, он должен справиться с этим за вас.
Основная причина, по которой вы получаете OOM, заключается в том, как работает алгоритм deflate zlib.
Представьте себе эту установку: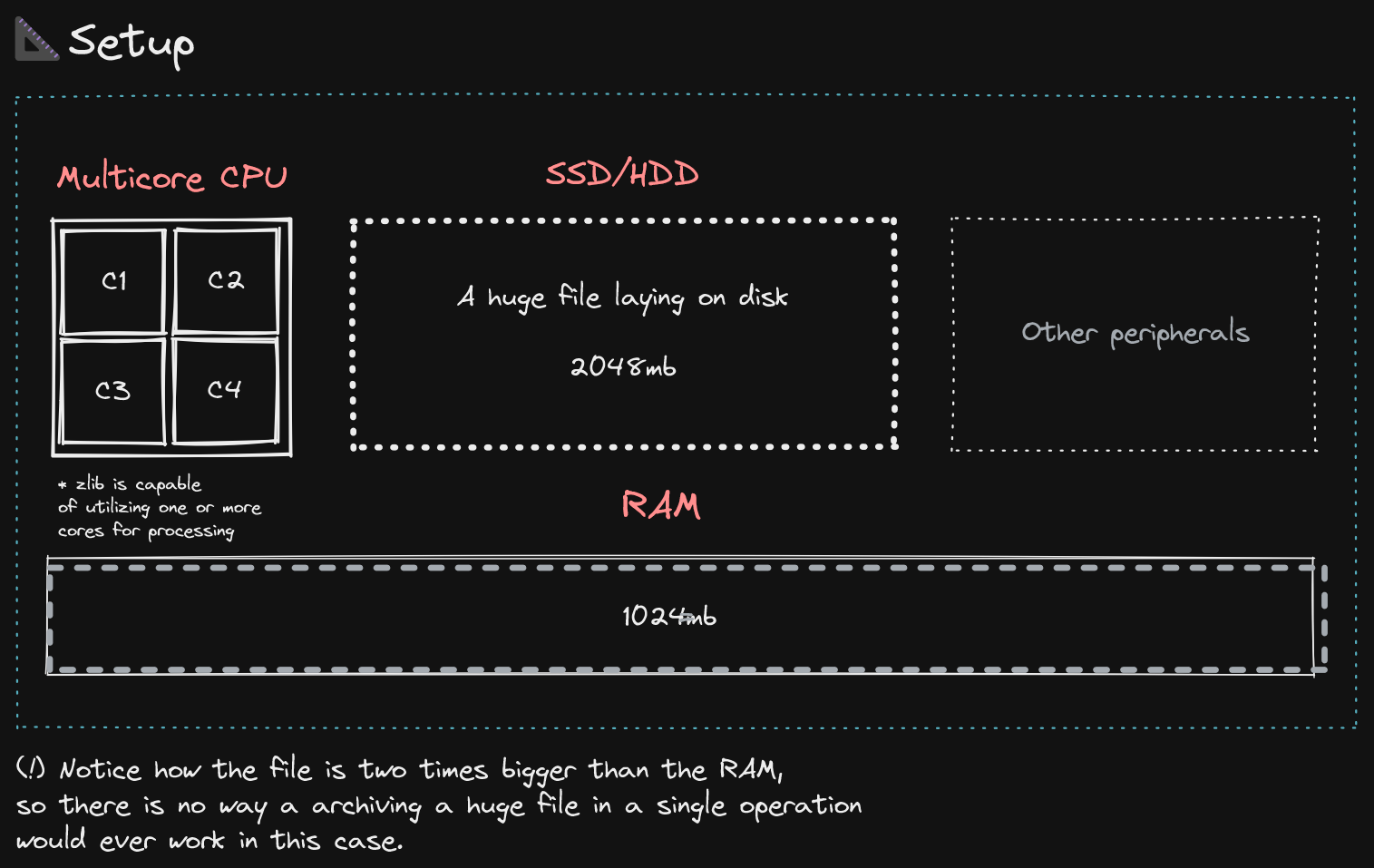
- Он начинает читать весь файл, открывая доступный для чтения поток.
- Он создает временный выходной файл размером 0 байт с самого начала.
- Затем он считывает данные порциями, называемыми
dictionary size, затем он отправляет его в ЦП для дальнейшей обработки и сжатия, которые распространяются обратно в ОЗУ. - Когда он закончил с определенным словарем фиксированного размера, он переходит к следующему и так далее, пока не достигнет терминатора END OF FILE.
- После этого он захватывает все эти дефлированные (сжатые) байты из ОЗУ и записывает их в реальный файл.
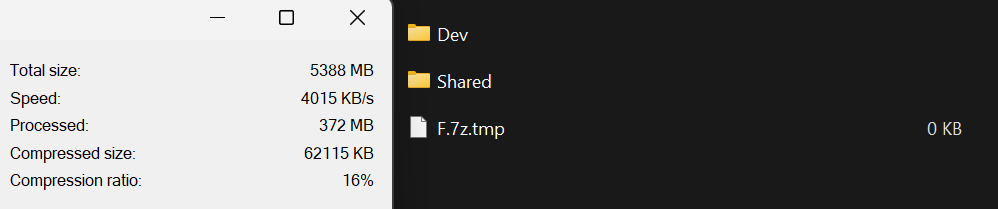
Вы можете наблюдать и делать выводы об этом поведении, инициировав операцию выкачивания, пример ниже.
(Файл создан, обработано 372 МБ, но ничего не записывается в файл до последнего обработанного байта.)
Технически вы можете взять все части, СНОВА заархивировать их в tar.gz, а затем загрузить в AWS как один файл, но вы можете столкнуться с той же проблемой с памятью, но теперь в части загрузки.
Вот ограничения на размер файла:
https://docs.aws.amazon.com/AmazonS3/latest/userguide/upload-objects.html .
Если вы используете CLI, технически вы можете это сделать, если вам нужно или нужно использовать REST API, это не вариант для вас, поскольку ограничение составляет всего 5 ГБ на запрос.
Кроме того, вы не указали максимальный размер, поэтому, если он даже больше 160 ГБ, это не вариант ДАЖЕ с использованием интерфейса командной строки AWS (который заботится об освобождении памяти после каждого загруженного фрагмента). Так что лучше всего будет многостраничная загрузка.
https://docs.aws.amazon.com/cli/latest/reference/s3api/create-multipart-upload.html
Всего наилучшего!
Сжатие файла за 1 раз - не совсем правильный способ. Подумайте, что лучший способ - разбить проблему таким образом, чтобы вы не загружали все данные за один раз, а считывали их байт за байтом и отправляли в пункт назначения байт за байтом. Таким образом, вы не только получите скорость (~x10), но и устраните эти OOM.
Пунктом назначения может быть веб-конечная точка экземпляра EC2 или веб-служба с интерфейсом API-шлюза в зависимости от выбранного вами варианта архитектуры.
Таким образом, по сути, часть 1 решения заключается в ПОТОКЕ - заархивируйте его байт за байтом и отправьте в конечную точку http. Часть 2 может заключаться в использовании многокомпонентных интерфейсов загрузки из AWS SDK (в вашем месте назначения) и отправке их параллельно S3.
Путь в = Paths.get("abc.huge"); Выходной путь = Paths.get("abc.huge.gz");
try (InputStream in = Files.newInputStream(in);
OutputStream fout = Files.newOutputStream(out);) {
GZipCompressorOutputStream out2 = new GZipCompressorOutputStream(
new BufferedOutputStream(fout));
// Read and write byte by byte
final byte[] buffer = new byte[buffersize];
int n = 0;
while (-1 != (n = in.read(buffer))) {
out2.write(buffer, 0, n);
}
}