Многоуровневые круговые диаграммы с последовательной раскраской
Я пытаюсь создать многоуровневую круговую диаграмму для нескольких файлов в следующем формате:
117.txt
compartment percent sequence
dna 90 AAGTGT
dna 3 AAGTGG
dna 0 AAAAAA
...
rna 75 AAGTGT
rna 10 AAAAAA
rna 10 AAGTGG
...
...
plasma 75 AAGTGT
plasma 10 AAGTGG
plasma 0 AAAAAA
Я пытаюсь создать концентрические круговые диаграммы в виде фигуры с помощью ggplot с уникальным цветом для каждой отдельной последовательности на основе каждого файла, например, упрощенного файла выше (который я могу прочитать как информационный кадр). df). Для каждого отделения имеется 2951 уникальных последовательностей, которые присутствуют и имеют процент, указанный или обозначенный "0", если нет. Поэтому каждый файл имеет 2951 секв *3 отделения = 8853 строки.
Пока что код, который у меня есть, хорошо работает для отдельных файлов, порядок последовательностей не обязательно соответствует порядку моей пользовательской палитры, и цвета не являются одинаковыми для каждого файла (т. Е. Так, что последовательность "AAGTGT" всегда имеет одинаковый цвет по всему разные входные файлы). @Prem мне немного помог с подобным вопросом, но я не могу понять, что здесь происходит. Код ниже:
library(ggplot2)
library(randomcoloR)
pal<-c(randomColor(count=2951))
ggplot(df, aes( x=compartment, y=percent, fill=sequence) ) + labs(title="117")
+ geom_bar(stat = "identity") + scale_fill_manual(values=pal)
+ scale_x_discrete(limits=c("dna", "rna", "plasma"), labels=c("plasma"="Plasma\nvRNA", "rna"="RNA","dna"="DNA"))
+ theme_bw() + theme(legend.position="none") + coord_polar(theta="y")
+ theme(axis.line = element_blank(), panel.grid.major.x = element_blank(), panel.grid.major.y = element_blank(),
panel.grid.minor = element_blank(), panel.border = element_blank(), panel.background = element_blank())
+ theme(axis.text=element_blank(), axis.title = element_blank(), axis.ticks = element_blank())
+ theme(plot.title = element_text(colour="black", face="bold", size=24, hjust=0.5))
Когда я запускаю его в моем более крупном файле данных с моими 2951 последовательностями для каждого из трех отделений, не только цвета моей палитры не обязательно соответствуют порядку последовательностей, но они не согласованы между графиками (см. Прилагаемый рисунок для наборов данных #117 и № 129, чьи основные последовательности должны быть одного цвета). 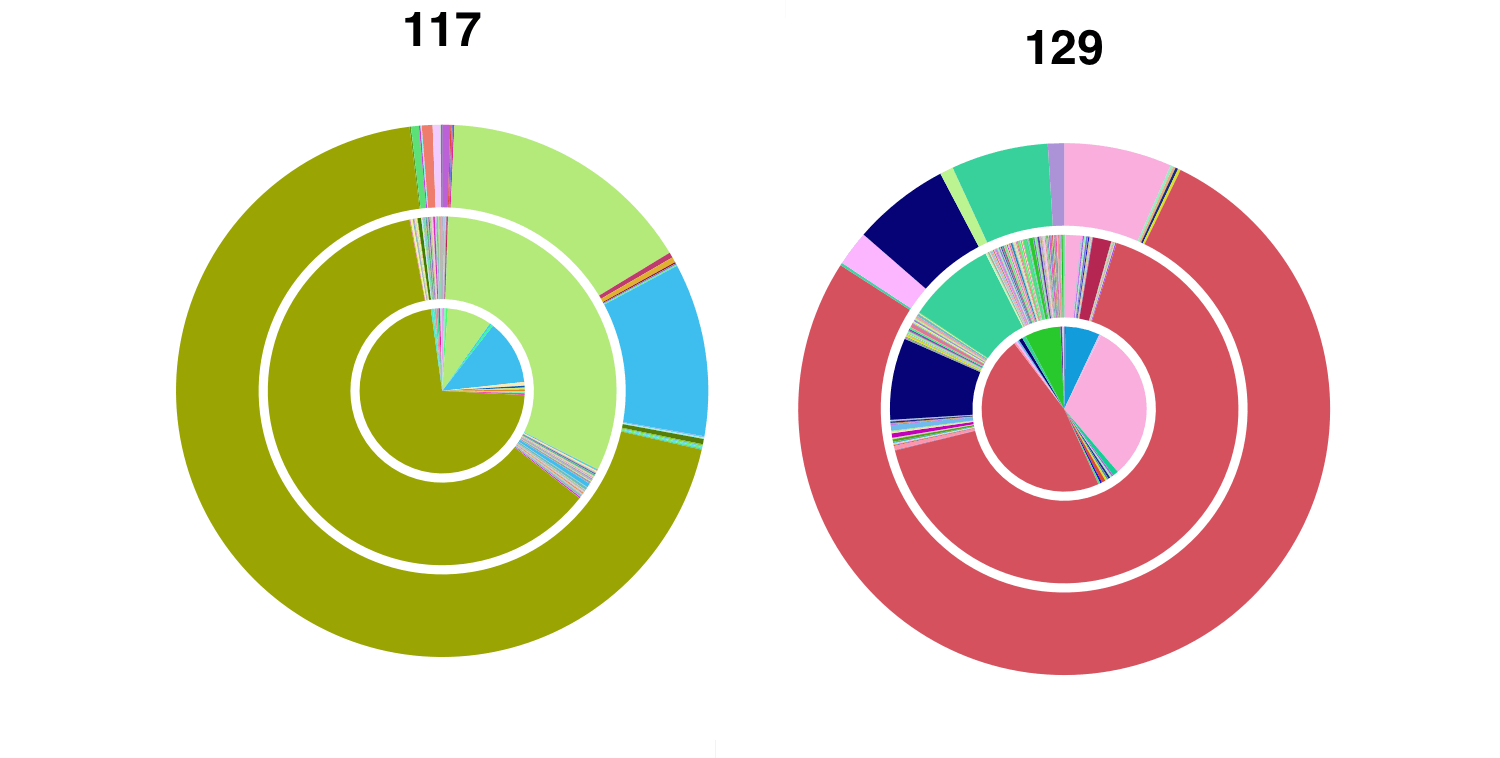
Любая помощь будет чрезвычайно признательна, так как я думаю, что это представление действительно полезно для сообщения моих данных. Спасибо всем!
1 ответ
Я не могу быть уверен без воспроизводимого примера для работы, но я думаю, что именованный вектор цветов заливки даст согласованные цвета. Например:
set.seed(2) # For reproducibility of random color vector
pal <- randomColor(count=2951)
pal = setNames(pal, unique(df$sequence))
Теперь запустите код вашего графика как обычно. Используя именованный вектор цветов, где имена являются уровнями sequenceВы должны всегда получать один и тот же цвет, назначенный одной и той же последовательности.
(Я также предполагаю, что в приведенном выше коде есть 2951 уникальных уровней sequence, Лучший подход был бы pal <- randomColor(count=length(unique(df$sequence))) так что вы получаете количество цветов из данных, а не жестко их кодируете.)
Вышеупомянутое будет работать для одного фрейма данных или для группы фреймов данных, где каждый фрейм данных включает в себя все возможные последовательности, которые могут появляться в любом фрейме данных.
Если у вас есть несколько фреймов данных, которые могут содержать разные последовательности, создайте именованный цветовой вектор на основе набора уникальных последовательностей во всех фреймах данных. В идеале, ваши фреймы данных должны быть в списке (предположим, это называется df.list) где каждый элемент является фреймом данных. Тогда вы могли бы сделать:
sequences = unique(unlist(sapply(df.list, function(d) d$sequence)))
set.seed(2)
pal <- randomColor(count=length(sequences))
pal = setNames(pal, sequences)
Если ваши фреймы данных загружены как отдельные объекты (т.е. не в списке), вы можете сделать:
sequences = unique(unlist(sapply(list(df1, df2, df3), function(d) d$sequence)))
где df1, df2, а также df3 ваши отдельные кадры данных.