Код Pyspark дает странную ошибку пробела
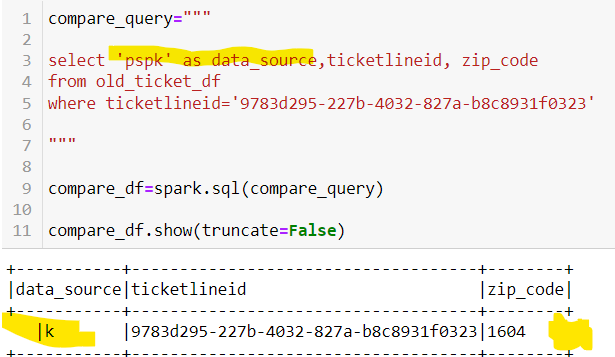
Когда я выполнил этот запрос,
zip codeполучает некоторые скрытые пробелы, которые перемещаются в столбец источника данных. Пробовал функцию и
trimпри возврате каретки пробелы не удаляются. Какие-либо предложения?
Примечание: оконный раздел использовался для получения почтового индекса.
select
distinct x,
first_value(zip_code)
over(partition by x order by date_time_closed desc) as zip_code
from table