Конвертировать PDF в изображение с высоким разрешением
Я пытаюсь использовать программу командной строки convertвзять PDF в изображение (JPEG или PNG). Вот один из PDF-файлов, которые я пытаюсь конвертировать.
Я хочу, чтобы программа убрала лишние пробелы и вернула изображение достаточно высокого качества, чтобы верхние индексы можно было легко прочитать.
Это моя лучшая попытка. Как видите, обрезка работает нормально, мне просто нужно немного повысить разрешение. Это команда, которую я использую:
convert -trim 24.pdf -resize 500% -quality 100 -sharpen 0x1.0 24-11.jpg
Я пытался принять следующие сознательные решения:
- изменить его размер больше (не влияет на разрешение)
- сделать качество как можно выше
- использовать
-sharpen(Я пробовал диапазон значений)
Любые предложения по получению разрешения изображения в финальном PNG/JPEG выше будут с благодарностью!
24 ответа
Похоже, что следующие работы:
convert \
-verbose \
-density 150 \
-trim \
test.pdf \
-quality 100 \
-flatten \
-sharpen 0x1.0 \
24-18.jpg
Это приводит к левому изображению. Сравните это с результатом моей оригинальной команды ( изображение справа):


(Чтобы по- настоящему увидеть и оценить различия между ними, щелкните правой кнопкой мыши по каждому из них и выберите "Открыть изображение в новой вкладке...".)
Также имейте в виду следующие факты:
- Хуже размытое изображение справа имеет размер файла 1,941,702 байт (1,85 МБайт). Его разрешение составляет 3060x3960 пикселей с использованием 16-битного цветового пространства RGB.
- Лучшее четкое изображение слева имеет размер файла 337,879 байт (330 кБайт). Его разрешение составляет 758х996 пикселей, используется 8-битное цветовое пространство Grey.
Таким образом, нет необходимости изменять размер; добавить -density флаг. Значение плотности 150 странно - попытка диапазона значений приводит к ухудшению изображения в обоих направлениях!
Лично мне это нравится.
convert -density 300 -trim test.pdf -quality 100 test.jpg
Это чуть более чем в два раза больше размера файла, но для меня это выглядит лучше.
-density 300 устанавливает dpi, в котором отображается PDF.
-trim удаляет все краевые пиксели того же цвета, что и угловые пиксели.
-quality 100 устанавливает высокое качество сжатия JPEG.
Вещи как -sharpen не очень хорошо работают с текстом, потому что они отменяют действия вашей системы рендеринга шрифтов, чтобы сделать их более разборчивыми.
Если вы действительно хотите, чтобы он был взорван, используйте здесь изменить размер и, возможно, большее значение dpi, например targetDPI * scalingFactor Это отразит PDF в разрешении / размере, которое вы намереваетесь.
Описания параметров на imagemagick.org здесь
У меня действительно не было хорошего успеха с convert [обновление в мае 2020 года: на самом деле: у меня это почти никогда не работает], но у меня был ОТЛИЧНЫЙ успех с pdftoppm. Вот пара примеров создания высококачественных изображений из PDF:
[Производит файлы размером ~25 МБ на один pg] Выводит несжатый файл формата .tif с разрешением 300 точек на дюйм в папку под названием "images" с файлами с именами pg-1.tif, pg-2.tif, pg-3.tif, так далее:
mkdir -p images && pdftoppm -tiff -r 300 mypdf.pdf images/pg[Производит файлы размером ~1 МБ на страницу] Вывод в формате .jpg с разрешением 300 точек на дюйм:
mkdir -p images && pdftoppm -jpeg -r 300 mypdf.pdf images/pg[Производит файлы размером ~2 МБ на страницу] Вывод в формате .jpg с максимальным качеством (наименьшее сжатие) и все еще с разрешением 300 точек на дюйм:
mkdir -p images && pdftoppm -jpeg -jpegopt quality=100 -r 300 mypdf.pdf images/pg
Дополнительные объяснения, варианты и примеры см. В моем полном ответе здесь:
https://askubuntu.com/questions/150100/extracting-embedded-images-from-a-pdf/1187844.
Связанные с:
- [Как превратить PDF в PDF с возможностью поиска с
pdf2searchablepdf] https://askubuntu.com/questions/473843/how-to-turn-a-pdf-into-a-text-searchable-pdf/1187881 - Сшитые:
Я использую pdftoppm в командной строке, чтобы получить исходное изображение, как правило, с разрешением 300 точек на дюйм, поэтому pdftoppm -r 300затем используйте convert сделать обрезку и преобразование PNG.
Обычно я извлекаю внедренное изображение с помощью pdfimages в собственном разрешении, а затем использую преобразование ImageMagick в нужный формат:
$ pdfimages -list fileName.pdf
$ pdfimages fileName.pdf fileName # save in .ppm format
$ convert fileName-000.ppm fileName-000.png
это генерирует лучший и самый маленький файл результатов.
Примечание. Для встроенных изображений с потерями в формате JPG необходимо использовать -j:
$ pdfimages -j fileName.pdf fileName # save in .jpg format
С недавним попплером вы можете использовать -all, который сохраняет убытки как jpg и без потерь как png
На небольшой предоставляемой платформе Win вам пришлось загрузить недавний (0.37 2015 г.) бинарный файл poppler-util с http://blog.alivate.com.au/poppler-windows/
В ImageMagick вы можете делать "суперсэмплинг". Вы указываете большую плотность, а затем уменьшаете размер до желаемого для конечного выходного размера. Например с вашим изображением:
convert -density 600 test.pdf -background white -flatten -resize 25% test.png

Загрузите изображение для просмотра в полном разрешении для сравнения.
Я не рекомендую сохранять в JPG, если вы ожидаете дальнейшей обработки.
Если вы хотите, чтобы размер выходного файла был таким же, как у входного, измените размер до величины, обратной отношению вашей плотности к 72. Например, -density 288 и -resize 25%. 288=4*72 и 25%=1/4
Чем больше плотность, тем лучше полученное качество, но обработка займет больше времени.
Я обнаружил, что это быстрее и стабильнее, когда пакетная обработка больших PDF-файлов в PNG и JPG использует базовый gs (ака Ghostscript) команда, которая convert использует.
Вы можете увидеть команду в выводе convert -verbose и есть еще несколько возможных настроек (YMMV), к которым трудно / невозможно получить прямой доступ через convert,
Тем не менее, было бы сложнее выполнить обрезку с помощью gsтак что, как я уже сказал, YMMV!
Это также дает вам хорошие результаты:
exec("convert -geometry 1600x1600 -density 200x200 -quality 100 test.pdf test_image.jpg");
Пользователь Linux здесь: я попробовал convert утилита командной строки (для PDF в PNG), и я не был доволен результатами. Я нашел, что это было проще, с лучшим результатом:
- извлеките pdf-страницу с помощью pdftk
- например:
pdftk file.pdf cat 3 output page3.pdf
- например:
- открыть (импортировать) этот PDF с
GIMP- важно: изменить импорт
Resolutionот100в300или же600 pixel/in
- важно: изменить импорт
- в
GIMPэкспортировать как PNG (изменить расширение файла на.png)
Редактировать:
Добавлена картинка, как того требует Comments, Используемая команда преобразования:
convert -density 300 -trim struct2vec.pdf -quality 100 struct2vec.png
GIMP: импортируется с разрешением 300 точек на дюйм (пикс / дюйм); экспортируется как уровень сжатия PNG 3.
Я не использовал GIMP в командной строке (см. Мой комментарий ниже).

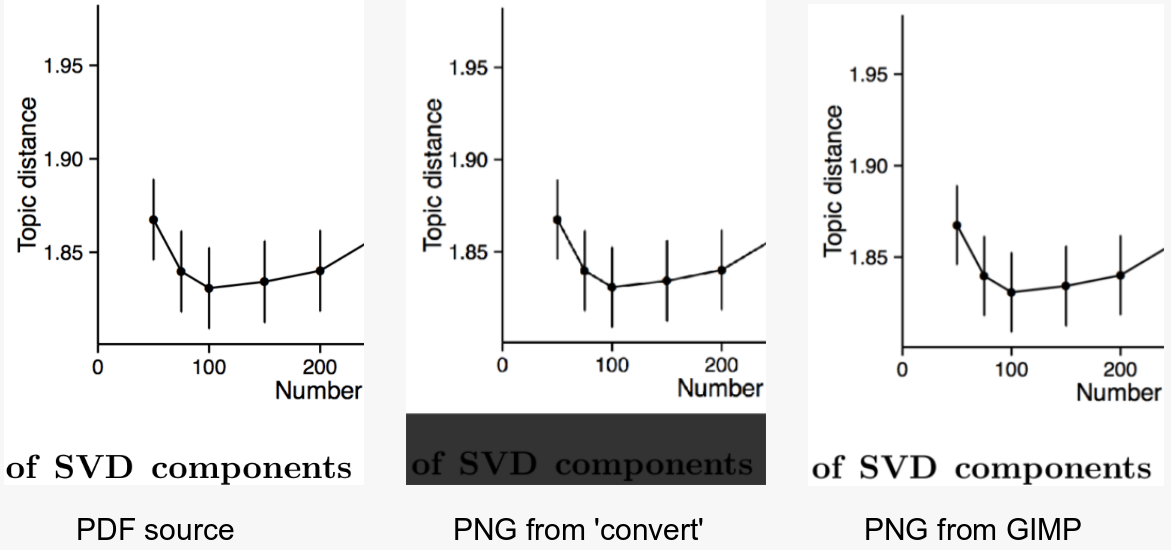
Еще одно предложение заключается в том, что вы можете использовать GIMP.
Просто загрузите файл PDF в GIMP-> сохранить как.xcf, и тогда вы сможете делать с изображением все, что захотите.
Я использовал pdf2image. Простая библиотека Python, которая работает как шарм.
Сначала установите poppler на машину без Linux. Вы можете просто скачать zip-архив. Разархивируйте в Program Files и добавьте корзину в Machine Path.
После этого вы можете использовать pdf2image в классе python следующим образом:
from pdf2image import convert_from_path, convert_from_bytes
images_from_path = convert_from_path(
inputfile,
output_folder=outputpath,
grayscale=True, fmt='jpeg')
Я плохо разбираюсь в python, но смог сделать из него exe. Позже вы можете использовать exe с параметром ввода и вывода файла. Я использовал его на C#, и все работает нормально.
Качество изображения хорошее. OCR работает нормально.
Для Windows (проверено на W11):
magick.exe -verbose -density 150 "input.pdf" -quality 100 -sharpen 0x1.0 output.jpg
Вам нужно установить:
ImageMagick https://imagemagick.org/index.php
Ghostscript https://www.ghostscript.com/releases/gsdnld.html
Дополнительная информация:
Следите за использованием
-flattenпараметр, так как он может создавать только первую страницу как изображениеИспользовать
-scene 1параметр для начала с индекса 1 с именами изображенийconvertупомянутая команда устарела в пользуmagick
получить изображение из PDF в iOS Swift Лучшее решение
func imageFromPdf(pdfUrl : URL,atIndex index : Int, closure:@escaping((UIImage)->Void)){
autoreleasepool {
// Instantiate a `CGPDFDocument` from the PDF file's URL.
guard let document = PDFDocument(url: pdfUrl) else { return }
// Get the first page of the PDF document.
guard let page = document.page(at: index) else { return }
// Fetch the page rect for the page we want to render.
let pageRect = page.bounds(for: .mediaBox)
let renderer = UIGraphicsImageRenderer(size: pageRect.size)
let img = renderer.image { ctx in
// Set and fill the background color.
UIColor.white.set()
ctx.fill(CGRect(x: 0, y: 0, width: pageRect.width, height: pageRect.height))
// Translate the context so that we only draw the `cropRect`.
ctx.cgContext.translateBy(x: -pageRect.origin.x, y: pageRect.size.height - pageRect.origin.y)
// Flip the context vertically because the Core Graphics coordinate system starts from the bottom.
ctx.cgContext.scaleBy(x: 1.0, y: -1.0)
// Draw the PDF page.
page.draw(with: .mediaBox, to: ctx.cgContext)
}
closure(img)
}
}
//Использование
let pdfUrl = URL(fileURLWithPath: "PDF URL")
self.imageFromPdf2(pdfUrl: pdfUrl, atIndex: 0) { imageIS in
}
Я использую icepdf - движок java pdf с открытым исходным кодом. Посмотрите демо-версию офиса.
package image2pdf;
import org.icepdf.core.exceptions.PDFException;
import org.icepdf.core.exceptions.PDFSecurityException;
import org.icepdf.core.pobjects.Document;
import org.icepdf.core.pobjects.Page;
import org.icepdf.core.util.GraphicsRenderingHints;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.awt.image.RenderedImage;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.IOException;
public class pdf2image {
public static void main(String[] args) {
Document document = new Document();
try {
document.setFile("C:\\Users\\Dell\\Desktop\\test.pdf");
} catch (PDFException ex) {
System.out.println("Error parsing PDF document " + ex);
} catch (PDFSecurityException ex) {
System.out.println("Error encryption not supported " + ex);
} catch (FileNotFoundException ex) {
System.out.println("Error file not found " + ex);
} catch (IOException ex) {
System.out.println("Error IOException " + ex);
}
// save page captures to file.
float scale = 1.0f;
float rotation = 0f;
// Paint each pages content to an image and
// write the image to file
for (int i = 0; i < document.getNumberOfPages(); i++) {
try {
BufferedImage image = (BufferedImage) document.getPageImage(
i, GraphicsRenderingHints.PRINT, Page.BOUNDARY_CROPBOX, rotation, scale);
RenderedImage rendImage = image;
try {
System.out.println(" capturing page " + i);
File file = new File("C:\\Users\\Dell\\Desktop\\test_imageCapture1_" + i + ".png");
ImageIO.write(rendImage, "png", file);
} catch (IOException e) {
e.printStackTrace();
}
image.flush();
}catch(Exception e){
e.printStackTrace();
}
}
// clean up resources
document.dispose();
}
}
Я также попытался ImageMagick и pdftoppm, как pdftoppm и icepdf имеет высокое разрешение, чем ImageMagick.
Пожалуйста, примите к сведению, прежде чем голосовать, это решение предназначено для Gimp, использующего графический интерфейс, а не для ImageMagick, использующего командную строку, но оно отлично работало для меня как альтернативы, и поэтому я счел необходимым поделиться здесь.
Следуйте этим простым шагам, чтобы извлечь изображения в любом формате из документов PDF
- Скачать программу управления изображениями GIMP
- Откройте программу после установки
- Откройте PDF-документ, который вы хотите извлечь изображения
- Выберите только те страницы документа PDF, из которых вы хотите извлечь изображения. N/B: если вам нужны только обложки, выберите только первую страницу.
- Нажмите "Открыть" после выбора страниц, с которых вы хотите извлечь изображения.
- Нажмите на меню Файл, когда GIMP, когда открываются страницы
- Выберите Экспорт как в меню Файл
- Выберите предпочитаемый тип файла по расширению (скажем, png) под всплывающим диалоговым окном.
- Нажмите **Export*, чтобы экспортировать изображение в нужное место.
- Затем вы можете проверить файловый менеджер на предмет экспортированного изображения.
Вот и все.
надеюсь, это поможет
Многие ответы здесь сосредоточены на использовании magick (или его зависимости GhostScript), как указано в вопросе OP, а некоторые предлагают Gimp в качестве альтернативы, не объясняя, почему некоторые настройки могут лучше всего работать в разных случаях.
Взяв «образец» OP, требованием является четкое обрезанное изображение как можно меньшего размера, но сохраняющее хорошую читаемость. и здесь результат составляет 96 dpi в 58 КБ (очень небольшое увеличение по сравнению с исходным вектором 54 КБ), но сохраняет хорошее изображение даже при увеличении. сравните это с 72 dpi (226 КБ) в принятом изображении ответа выше.
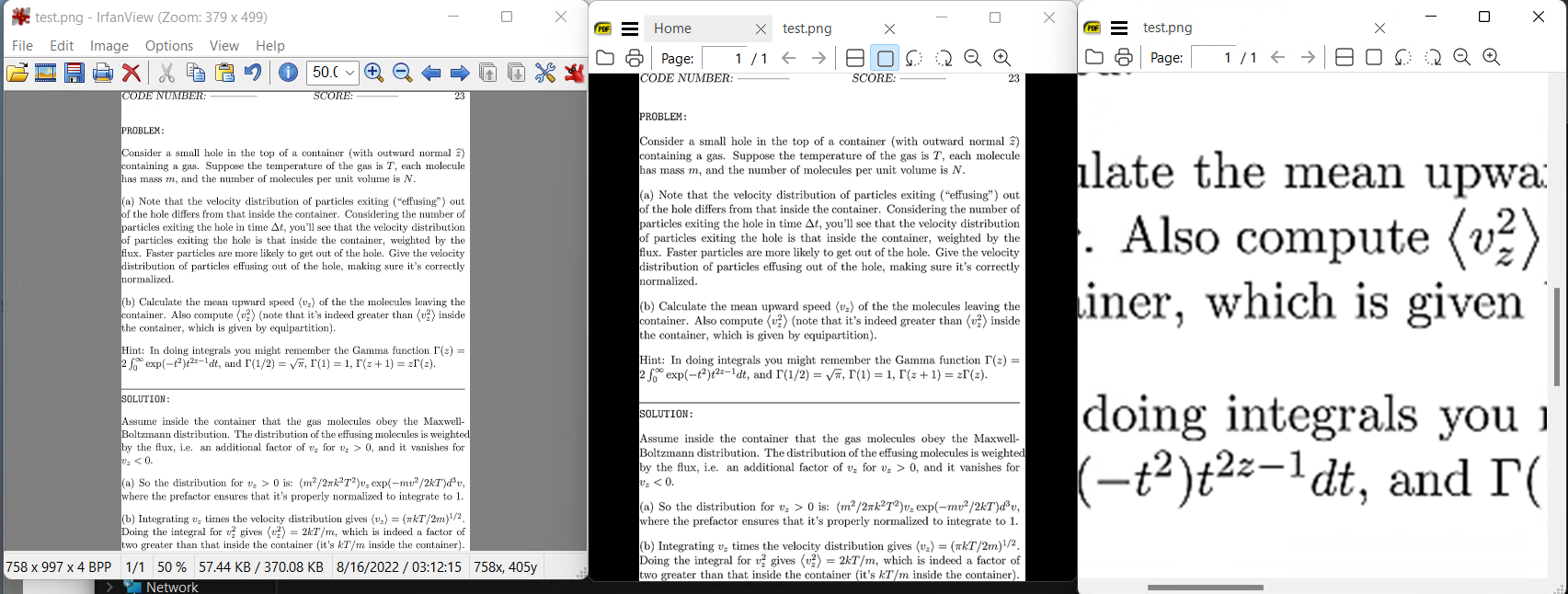
Ключевым моментом является то, что любой процессор изображений может быть настроен на пакетный запуск из командной строки с использованием профиля в качестве входных данных, поэтому здесь IrfanView (с GS или без него) настроен на автоматическую обрезку страниц (страниц) PDF и вывод с разрешением по умолчанию 96 dpi. в PNG, используя только 4 цвета BitPerPixel для 16 оттенков серого.
Размер можно еще уменьшить, снизив разрешение до 72, но 96 — оптимальная настройка для отображения на экране в формате PNG.
Прикрепленный файл PNG выглядит очень размытым. В случае, если вам нужно использовать дополнительную постобработку для каждого изображения, созданного вами в качестве предварительного просмотра PDF, вы снизите производительность своего решения.
2JPEG может конвертировать PDF-файл, который вы прикрепили, в хороший JPG-файл и обрезать пустые поля одним вызовом:
2jpeg.exe -src "C:\In\*.*" -dst "C:\Out" -oper Crop method:autocrop
Следующий скрипт на python будет работать на любом Mac (Snow Leopard и выше). Его можно использовать в командной строке с последовательными файлами PDF в качестве аргументов, или вы можете вставить действие Run Shell Script в Automator и создать сервис (Quick Action in Mojave).
Вы можете установить разрешение выходного изображения в скрипте.
Скрипт и Quick Action можно скачать с github.
#!/usr/bin/python
# coding: utf-8
import os, sys
import Quartz as Quartz
from LaunchServices import (kUTTypeJPEG, kUTTypeTIFF, kUTTypePNG, kCFAllocatorDefault)
resolution = 300.0 #dpi
scale = resolution/72.0
cs = Quartz.CGColorSpaceCreateWithName(Quartz.kCGColorSpaceSRGB)
whiteColor = Quartz.CGColorCreate(cs, (1, 1, 1, 1))
# Options: kCGImageAlphaNoneSkipLast (no trans), kCGImageAlphaPremultipliedLast
transparency = Quartz.kCGImageAlphaNoneSkipLast
#Save image to file
def writeImage (image, url, type, options):
destination = Quartz.CGImageDestinationCreateWithURL(url, type, 1, None)
Quartz.CGImageDestinationAddImage(destination, image, options)
Quartz.CGImageDestinationFinalize(destination)
return
def getFilename(filepath):
i=0
newName = filepath
while os.path.exists(newName):
i += 1
newName = filepath + " %02d"%i
return newName
if __name__ == '__main__':
for filename in sys.argv[1:]:
pdf = Quartz.CGPDFDocumentCreateWithProvider(Quartz.CGDataProviderCreateWithFilename(filename))
numPages = Quartz.CGPDFDocumentGetNumberOfPages(pdf)
shortName = os.path.splitext(filename)[0]
prefix = os.path.splitext(os.path.basename(filename))[0]
folderName = getFilename(shortName)
try:
os.mkdir(folderName)
except:
print "Can't create directory '%s'"%(folderName)
sys.exit()
# For each page, create a file
for i in range (1, numPages+1):
page = Quartz.CGPDFDocumentGetPage(pdf, i)
if page:
#Get mediabox
mediaBox = Quartz.CGPDFPageGetBoxRect(page, Quartz.kCGPDFMediaBox)
x = Quartz.CGRectGetWidth(mediaBox)
y = Quartz.CGRectGetHeight(mediaBox)
x *= scale
y *= scale
r = Quartz.CGRectMake(0,0,x, y)
# Create a Bitmap Context, draw a white background and add the PDF
writeContext = Quartz.CGBitmapContextCreate(None, int(x), int(y), 8, 0, cs, transparency)
Quartz.CGContextSaveGState (writeContext)
Quartz.CGContextScaleCTM(writeContext, scale,scale)
Quartz.CGContextSetFillColorWithColor(writeContext, whiteColor)
Quartz.CGContextFillRect(writeContext, r)
Quartz.CGContextDrawPDFPage(writeContext, page)
Quartz.CGContextRestoreGState(writeContext)
# Convert to an "Image"
image = Quartz.CGBitmapContextCreateImage(writeContext)
# Create unique filename per page
outFile = folderName +"/" + prefix + " %03d.png"%i
url = Quartz.CFURLCreateFromFileSystemRepresentation(kCFAllocatorDefault, outFile, len(outFile), False)
# kUTTypeJPEG, kUTTypeTIFF, kUTTypePNG
type = kUTTypePNG
# See the full range of image properties on Apple's developer pages.
options = {
Quartz.kCGImagePropertyDPIHeight: resolution,
Quartz.kCGImagePropertyDPIWidth: resolution
}
writeImage (image, url, type, options)
del page
Вы можете сделать это в LibreOffice Draw (который обычно предустановлен в Ubuntu):
- Откройте файл PDF в LibreOffice Draw.
- Прокрутите до нужной страницы.
- Убедитесь, что элементы текста / изображения размещены правильно. Если нет, вы можете настроить / отредактировать их на странице.
- Верхнее меню: Файл> Экспорт...
- Выберите нужный формат изображения в нижнем правом меню. Я рекомендую PNG.
- Назовите свой файл и нажмите "Сохранить".
- Появится окно настроек, в котором вы сможете настроить разрешение и размер.
- Нажмите ОК, и все готово.
это работает для создания одного файла из нескольких файлов PDF и изображений:
php exec('convert -density 300 -trim "/path/to/input_filename_1.png" "/path/to/input_filename_2.pdf" "/path/to/input_filename_3.png" -quality 100 "/path/to/output_filename_0.pdf"');
КУДА:
-плотность 300 = dpi
-trim = кое-что о прозрачности - кажется, что края выглядят гладкими
-качество 100 = качество по сравнению со сжатием (100 % качество)
-flatten... для нескольких страниц не используйте "flatten"
Используйте эту командную строку:
convert -geometry 3600x3600 -density 300x300 -quality 100 TEAM\ 4.pdf team4.png
Это должно правильно конвертировать файл, как вы просили.
Это на самом деле довольно легко сделать с помощью Preview на Mac. Все, что вам нужно сделать, это открыть файл в режиме предварительного просмотра и сохранить как (или экспортировать) файл в формате png или jpeg, но убедитесь, что вы используете не менее 300 точек на дюйм в нижней части окна, чтобы получить изображение высокого качества.
Конвертируйте PDF в изображение с высоким разрешением в Laravel с помощью Imagick.
$pdf_path = Storage::disk('public')->path($product_asset->pdf_path);
$directory_create = Storage::disk('public')->path('products/'.$product-
>id.'/pdf_images');
if (!file_exists($directory_create)) {
mkdir($directory_create, 0777, true);
}
$output_images = $directory_create.'/';
$im = new Imagick();
$im->setResolution(250, 250);
$im->readImage($pdf_path);
$im->setImageFormat('jpg');
$im->setImageCompression(Imagick::COMPRESSION_JPEG);
$im->setImageCompressionQuality(100);
$im->setCompressionQuality(100);
$im->clear();
$im->destroy();