Объединение условий из двух столбцов mysql
Я хотел бы объединить условия из 2 разных столбцов для моего запроса. Это мой оригинальный запрос. Вы можете проверить это в sqlfiddle.com.
-- creating database first for test data
create table attendance(Id int, DateTime datetime, Door char(20));
INSERT INTO attendance VALUES
( 1, '2016-01-01 08:00:00', 'In'),
( 2, '2016-01-01 09:00:00', 'Out'),
( 3, '2016-01-01 09:15:00', 'In'),
( 4, '2016-01-01 09:30:00', 'In'),
( 5, '2016-01-01 10:00:00', 'Out'),
( 6, '2016-01-01 15:00:00', 'In');
SELECT * FROM attendance;
SELECT
@id:=@id+1 Id,
MAX(IF(Door = 'In', DateTime, NULL)) `Check In`,
MAX(IF(Door = 'Out', DateTime, NULL)) `Check Out`
FROM
(SELECT
*,
CASE
WHEN
(Door != 'Out' AND @last_door = 'Out')
THEN @group_num:=@group_num+1
ELSE @group_num END door_group,
@last_door:=Door
FROM attendance
JOIN (SELECT @group_num:=1,@last_door := NULL) a
) t JOIN (SELECT @id:=0) b
GROUP BY t.door_group
HAVING SUM(Door = 'In') > 0 AND SUM(Door = 'Out') > 0;
//output
+------+---------------------+---------------------+
| Id | Check In | Check Out |
+------+---------------------+---------------------+
| 1 | 2016-01-01 08:00:00 | 2016-01-01 09:00:00 |
| 2 | 2016-01-01 09:30:00 | 2016-01-01 10:00:00 |
+------+---------------------+---------------------+
Из запроса выше, я хотел бы добавить еще один столбец.
-- creating database first for test data
create table attendance(Id int, DateTime datetime, Door char(20), Active_door char(20));
INSERT INTO attendance VALUES
( 1, '2016-01-01 08:00:00', 'In', ''),
( 2, '2016-01-01 09:00:00', 'Out', ''),
( 3, '2016-01-01 09:15:00', 'In', ''),
( 4, '2016-01-01 09:30:00', 'In', ''),
( 5, '2016-01-01 09:35:00', '', 'On'),
( 6, '2016-01-01 10:00:00', 'Out', ''),
( 7, '2016-01-01 16:00:00', '', 'Off');
Это изменения, которые я внес в свой запрос, но он не работает.
SELECT * FROM attendance;
SELECT
@id:=@id+1 Id,
MAX(IF(Door = 'In' OR Active_door = "On", DateTime, NULL)) `Check In`,
MAX(IF(Door = 'Out' OR Active_door = "Off", DateTime, NULL)) `Check Out`
FROM
(SELECT
*,
CASE
WHEN
((Door != 'Out' OR Active_door != "Off") AND (@last_door = 'Out' OR @last_door = 'Off'))
THEN @group_num:=@group_num+1
ELSE @group_num END door_group,
@last_door:=Door
FROM attendance
JOIN (SELECT @group_num:=1,@last_door := NULL) a
) t JOIN (SELECT @id:=0) b
GROUP BY t.door_group
HAVING SUM(Door = 'In') > 0 OR SUM(Active_door = 'On') > 0 AND SUM(Door = 'Out') > 0 OR SUM(Active_door = 'Off') > 0;
//output
+------+---------------------+---------------------+
| Id | Check In | Check Out |
+------+---------------------+---------------------+
| 1 | 2016-01-01 08:00:00 | 2016-01-01 09:00:00 |
| 2 | 2016-01-01 09:35:00 | 2016-01-01 10:00:00 |
| 3 | NULL | 2016-01-01 16:00:00 |
+------+---------------------+---------------------+
//my desire output
+------+---------------------+---------------------+
| Id | Check In | Check Out |
+------+---------------------+---------------------+
| 1 | 2016-01-01 08:00:00 | 2016-01-01 09:00:00 |
| 2 | 2016-01-01 09:35:00 | 2016-01-01 16:00:00 |
+------+---------------------+---------------------+
Пожалуйста, помогите мне, ребята, как я могу получить желаемый результат. Я хотел бы получить последний и последний из обеих колонок. Заранее спасибо.
1 ответ
Это стремится обеспечить простоту сопровождения решения без выполнения окончательного запроса за один раз, что почти удвоило бы его размер (на мой взгляд). Это связано с тем, что результаты должны совпадать и отображаться в одной строке с соответствующими событиями In и Out. В конце я использую несколько рабочих столов. Это реализовано в хранимой процедуре.
Хранимая процедура использует несколько переменных, которые вводятся с cross join, Думайте о перекрестном соединении как о механизме инициализации переменных. Я уверен, что переменные поддерживаются безопасно, в духе этого документа, на который часто ссылаются в переменных запросах. Важными частями справочника являются безопасная обработка переменных в строке, заставляющая их устанавливаться до того, как их используют другие столбцы. Это достигается за счет greatest() а также least() функции, которые имеют более высокий приоритет, чем переменные, устанавливаемые без использования этих функций. Обратите внимание, что coalesce() часто используется для той же цели. Если их использование кажется странным, например, взятие наибольшего числа, о котором известно, что оно больше 0 или 0, то это намеренно. Умышленно устанавливайте порядок приоритетов устанавливаемых переменных.
Столбцы в запросе названы такими вещами, как dummy2 и т. д. - это столбцы, выходные данные которых не использовались, но они использовались для установки переменных внутри, скажем, greatest() или другой. Это было упомянуто выше. Вывод типа 7777 был заполнителем в 3-м слоте, так как для if() это было использовано. Так что игнорируйте все это.
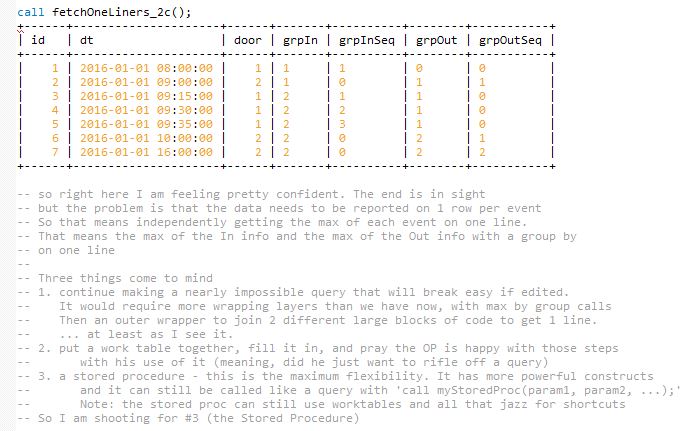
Я включил несколько скриншотов кода, который прогрессировал слой за слоем, чтобы помочь вам визуализировать вывод. И как эти итерации развития медленно переходят в следующую фазу, чтобы расширить предыдущую.
Я уверен, что мои коллеги могли бы улучшить это в одном запросе. Я мог бы закончить это таким образом. Но я считаю, что это привело бы к запутанному беспорядку, который сломался бы при прикосновении.
Схема:
create table attendance2(Id int, DateTime datetime, Door char(20), Active_door char(20));
INSERT INTO attendance2 VALUES
( 1, '2016-01-01 08:00:00', 'In', ''),
( 2, '2016-01-01 09:00:00', 'Out', ''),
( 3, '2016-01-01 09:15:00', 'In', ''),
( 4, '2016-01-01 09:30:00', 'In', ''),
( 5, '2016-01-01 09:35:00', '', 'On'),
( 6, '2016-01-01 10:00:00', 'Out', ''),
( 7, '2016-01-01 16:00:00', '', 'Off');
drop table if exists oneLinersDetail;
create table oneLinersDetail
( -- architect this depending on multi-user concurrency
id int not null,
dt datetime not null,
door int not null,
grpIn int not null,
grpInSeq int not null,
grpOut int not null,
grpOutSeq int not null
);
drop table if exists oneLinersSummary;
create table oneLinersSummary
( -- architect this depending on multi-user concurrency
id int not null,
grpInSeq int null,
grpOutSeq int null,
checkIn datetime null, -- we are hoping in the end it is not null
checkOut datetime null -- ditto
);
Хранимая процедура:
DROP PROCEDURE IF EXISTS fetchOneLiners;
DELIMITER $$
CREATE PROCEDURE fetchOneLiners()
BEGIN
truncate table oneLinersDetail; -- architect this depending on multi-user concurrency
insert oneLinersDetail(id,dt,door,grpIn,grpInSeq,grpOut,grpOutSeq)
select id,dt,door,grpIn,grpInSeq,grpOut,grpOutSeq
from
( select id,dt,door,
if(@lastEvt!=door and door=1,
greatest(@grpIn:=@grpIn+1,0),
7777) as dummy2, -- this output column we don't care about (we care about the variable being set)
if(@lastEvt!=door and door=2,
greatest(@grpOut:=@grpOut+1,0),
7777) as dummy3, -- this output column we don't care about (we care about the variable being set)
if (@lastEvt!=door,greatest(@flip:=1,0),least(@flip:=0,1)) as flip,
if (door=1 and @flip=1,least(@grpOutSeq:=0,1),7777) as dummy4,
if (door=1 and @flip=1,greatest(@grpInSeq:=1,0),7777) as dummy5,
if (door=1 and @flip!=1,greatest(@grpInSeq:=@grpInSeq+1,0),7777) as dummy6,
if (door=2 and @flip=1,least(@grpInSeq:=0,1),7777) as dummy7,
if (door=2 and @flip=1,greatest(@grpOutSeq:=1,0),7777) as dummy8,
if (door=2 and @flip!=1,greatest(@grpOutSeq:=@grpOutSeq+1,0),7777) as dummy9,
@grpIn as grpIn,
@grpInSeq as grpInSeq,
@grpOut as grpOut,
@grpOutSeq as grpOutSeq,
@lastEvt:=door as lastEvt
from
( select id,`datetime` as dt,
CASE
WHEN Door='in' or Active_door='on' THEN 1
ELSE 2
END as door
from attendance2
order by id
) xD1 -- derived table #1
cross join (select @grpIn:=0,@grpInSeq:=0,@grpOut:=0,@grpOutSeq:=0,@lastEvt:=-1,@flip:=0) xParams
order by id
) xD2 -- derived table #2
order by id;
-- select * from oneLinersDetail;
truncate table oneLinersSummary; -- architect this depending on multi-user concurrency
insert oneLinersSummary (id,grpInSeq,grpOutSeq,checkIn,checkOut)
select distinct grpIn,null,null,null,null
from oneLinersDetail
order by grpIn;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join
( select grpIn,max(grpInSeq) m
from oneLinersDetail
where door=1
group by grpIn
) d1
on d1.grpIn=ols.id
set ols.grpInSeq=d1.m;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join
( select grpOut,max(grpOutSeq) m
from oneLinersDetail
where door=2
group by grpOut
) d1
on d1.grpOut=ols.id
set ols.grpOutSeq=d1.m;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join oneLinersDetail old
on old.door=1 and old.grpIn=ols.id and old.grpInSeq=ols.grpInSeq
set ols.checkIn=old.dt;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join oneLinersDetail old
on old.door=2 and old.grpOut=ols.id and old.grpOutSeq=ols.grpOutSeq
set ols.checkOut=old.dt;
-- select * from oneLinersSummary;
-- dump out the results
select id,checkIn,checkOut
from oneLinersSummary
order by id;
-- rows are left in those two tables (oneLinersDetail,oneLinersSummary)
END$$
DELIMITER ;
Тестовое задание:
call fetchOneLiners();
+----+---------------------+---------------------+
| id | checkIn | checkOut |
+----+---------------------+---------------------+
| 1 | 2016-01-01 08:00:00 | 2016-01-01 09:00:00 |
| 2 | 2016-01-01 09:35:00 | 2016-01-01 16:00:00 |
+----+---------------------+---------------------+
Это конец ответа. Ниже приведена информация для разработчика о шагах, которые привели к завершению хранимой процедуры.
Версии развития, доведенные до конца. Надеемся, что это помогает в визуализации, а не просто сбрасывает запутанный кусок кода среднего размера.
Шаг А

Шаг Б

Шаг B вывод

Шаг С

Шаг C вывод