Как использовать Apache Sedona на таблицах Databricks Delta Live?
Я пытаюсь запустить некоторые геопространственные преобразования в Delta Live Table, используя Apache Sedona. Я попытался определить минимальный пример конвейера, демонстрирующий проблему, с которой я столкнулся.
В первой ячейке моего ноутбука я устанавливаю пакет apache-sedona Python:
%pip install apache-sedona
затем я использую только SedonaRegistrator.registerAll (чтобы включить геопространственную обработку в SQL) и возвращаю пустой кадр данных (этот код все равно не достигается):
import dlt
from pyspark.sql import SparkSession
from sedona.register import SedonaRegistrator
@dlt.table(comment="Test temporary table", temporary=True)
def my_temp_table():
SedonaRegistrator.registerAll(spark)
return spark.createDataFrame(data=[], schema=StructType([]))
Я создал конвейер DLT, оставив все по умолчанию, кроме конфигурации spark:
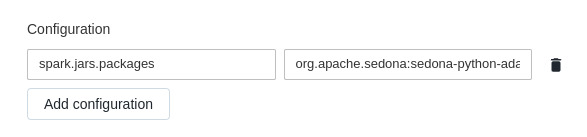
Вот неразрезанное значение:
org.apache.sedona:sedona-python-adapter-3.0_2.12:1.2.0-incubating,org.datasyslab:geotools-wrapper:1.1.0-25.2.
Это требуется в соответствии с этой документацией .
Когда я запускаю Pipeline, я получаю следующую ошибку:
py4j.Py4JException: An exception was raised by the Python Proxy. Return Message: Traceback (most recent call last):
File "/databricks/spark/python/lib/py4j-0.10.9.1-src.zip/py4j/java_gateway.py", line 2442, in _call_proxy
return_value = getattr(self.pool[obj_id], method)(*params)
File "/databricks/spark/python/dlt/helpers.py", line 22, in call
res = self.func()
File "<command--1>", line 8, in my_temp_table
File "/local_disk0/.ephemeral_nfs/envs/pythonEnv-0ecd1771-412a-4887-9fc3-44233ebe4058/lib/python3.8/site-packages/sedona/register/geo_registrator.py", line 43, in registerAll
cls.register(spark)
File "/local_disk0/.ephemeral_nfs/envs/pythonEnv-0ecd1771-412a-4887-9fc3-44233ebe4058/lib/python3.8/site-packages/sedona/register/geo_registrator.py", line 48, in register
return spark._jvm.SedonaSQLRegistrator.registerAll(spark._jsparkSession)
TypeError: 'JavaPackage' object is not callable
Я могу воспроизвести эту ошибку, запустив spark на своем компьютере и избегая установки пакетов, указанных в
spark.jars.packagesвыше.
Я предполагаю, что этот DLT Pipeline неправильно настроен для установки Apache Sedona. Мне не удалось найти никакой документации, описывающей, как установить Sedona или другие пакеты в конвейер DLT.
Что я также пробовал до сих пор, но безуспешно:
- использование сценария инициализации -> не поддерживается в DLT
- использование библиотеки jar -> не поддерживается в DLT
- использование библиотеки maven -> не поддерживается в DLT
Кто-нибудь знает, как/если это возможно сделать?
1 ответ
К сожалению, установка сторонних библиотек Java пока не поддерживается для Live Tables Delta, поэтому прямо сейчас вы не можете использовать Sedona с DLT .
Но если вас интересуют геопространственные возможности Databricks, вы можете взглянуть на недавно выпущенный проект Mosaic (блог с анонсом ), который поддерживает многие «стандартные» геопространственные функции, но сильно оптимизирован для Databricks, а также работает с Delta Live Tables. . Вот пример конвейера DLT, взятого из краткого руководства , в котором используются такие функции, как
st_contains, так далее.: