TaskGroup ограничивает объем используемой памяти для большого количества задач
Я пытаюсь создать механизм загрузки фрагментированных файлов, используя современный Swift Concurrency. Существует потоковое средство чтения файлов, которое я использую для чтения файлов по частям размером 1 МБ. Имеет два закрытия
nextChunk: (DataChunk) -> Voidа также
completion: () - Void. Первый вызывается столько раз, сколько данных считано из
InputStreamразмером куска.
Чтобы сделать этот ридер совместимым с Swift Concurrency, я сделал расширение и создал то, что кажется наиболее подходящим для такого случая.
public extension StreamedFileReader {
func read() -> AsyncStream<DataChunk> {
AsyncStream { continuation in
self.read(nextChunk: { chunk in
continuation.yield(chunk)
}, completion: {
continuation.finish()
})
}
}
}
Используя это, я итеративно читаю какой-то файл и делаю сетевые вызовы следующим образом:
func process(_ url: URL) async {
// ...
do {
for await chunk in reader.read() {
let request = // ...
_ = try await service.upload(data: chunk.data, request: request)
}
} catch let error {
reader.cancelReading()
print(error)
}
}
Проблема в том, что не существует какого-либо известного мне механизма ограничения, который не позволял бы выполнять более N сетевых вызовов. Таким образом, когда я пытаюсь загрузить огромный файл (5Gb), потребление памяти резко возрастает. Из-за этого идея потокового чтения файла не имеет смысла, так как проще было бы прочитать весь файл в память (это шутка, но выглядит так).
Напротив, если я использую старый добрый GCD, все работает как шарм:
func process(_ url: URL) {
let semaphore = DispatchSemaphore(value: 5) // limit to no more than 5 requests at a given time
let uploadGroup = DispatchGroup()
let uploadQueue = DispatchQueue.global(qos: .userInitiated)
uploadQueue.async(group: uploadGroup) {
// ...
reader.read(nextChunk: { chunk in
let requset = // ...
uploadGroup.enter()
semaphore.wait()
service.upload(chunk: chunk, request: requset) {
uploadGroup.leave()
semaphore.signal()
}
}, completion: { _ in
print("read completed")
})
}
}
Ну, это не совсем то же самое поведение, поскольку он использует параллельный
DispatchQueueпри последовательном выполнении. Поэтому я провел небольшое исследование и выяснил, что, вероятно,
TaskGroupэто то, что мне нужно в этом случае. Это позволяет запускать асинхронные задачи параллельно и т. д.
Я пробовал так:
func process(_ url: URL) async {
// ...
do {
let totalParts = try await withThrowingTaskGroup(of: Void.self) { [service] group -> Int in
var counter = 1
for await chunk in reader.read() {
let request = // ...
group.addTask {
_ = try await service.upload(data: chunk.data, request: request)
}
counter = chunk.index
}
return counter
}
} catch let error {
reader.cancelReading()
print(error)
}
}
В этом случае потребление памяти даже больше, чем в примере с
AsyncStreamповторение!
Я подозреваю, что должны быть какие-то условия, при которых мне нужно приостановить группу или задачу или что-то и позвонить
group.addTaskтолько когда можно действительно справиться с этими задачами, я собираюсь добавить, но я понятия не имею, как это сделать.
Я нашел этот Q / A и попытался поставить для каждого 5-го фрагмента, но это мне совсем не помогло.
Есть ли какой-либо механизм, аналогичный
DispatchGroup+
DispatchSemaphoreно для современного параллелизма?
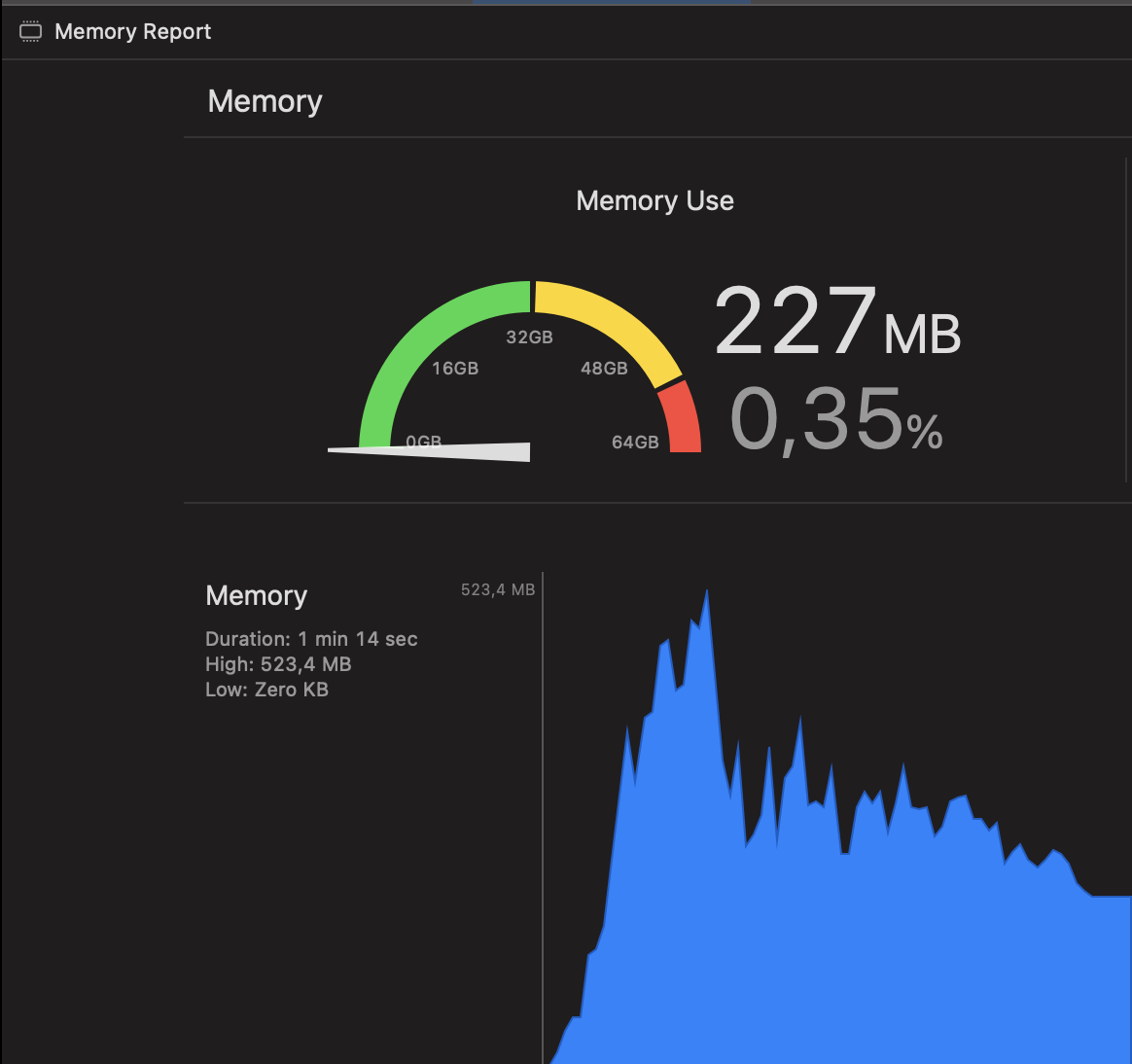
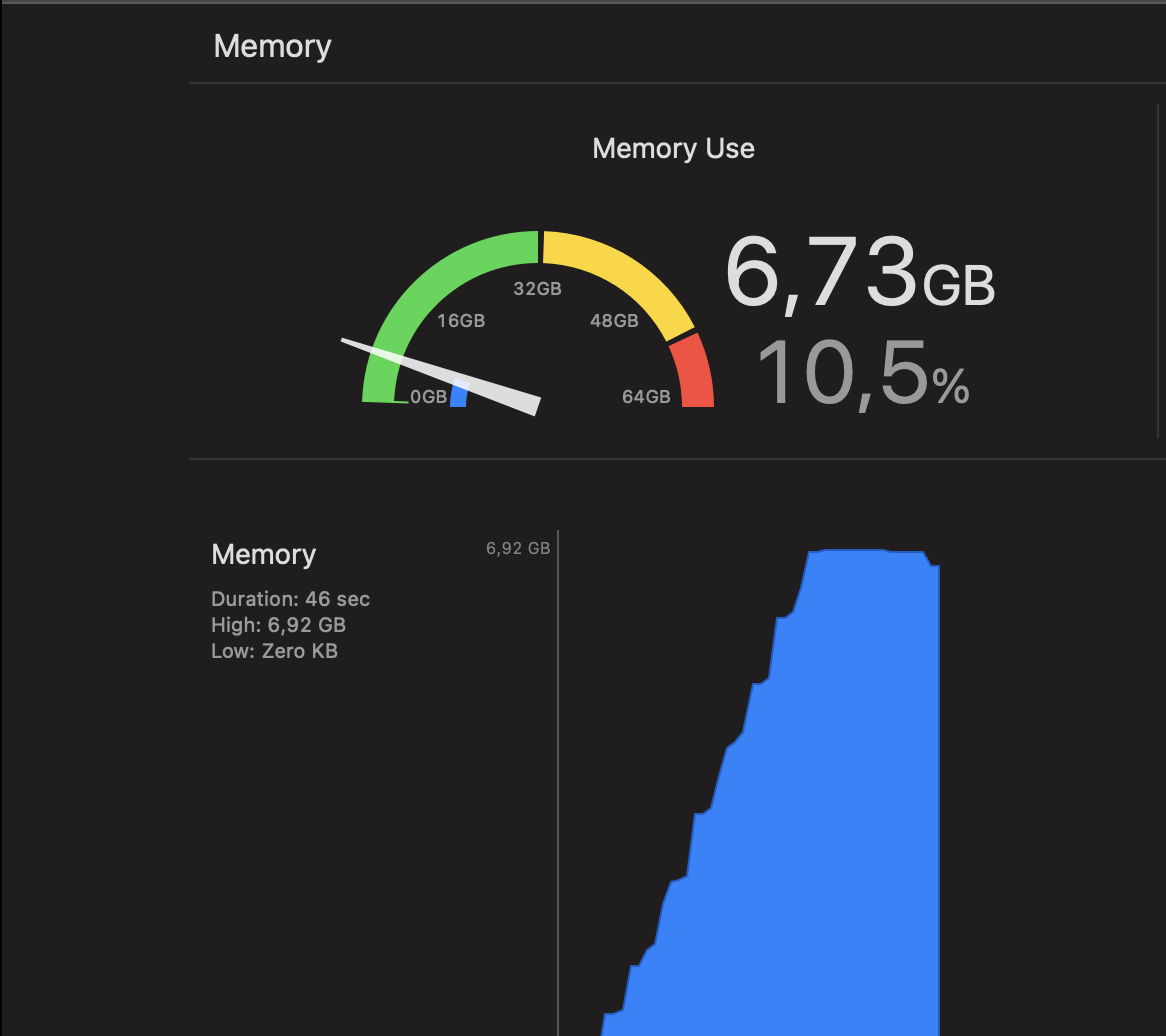
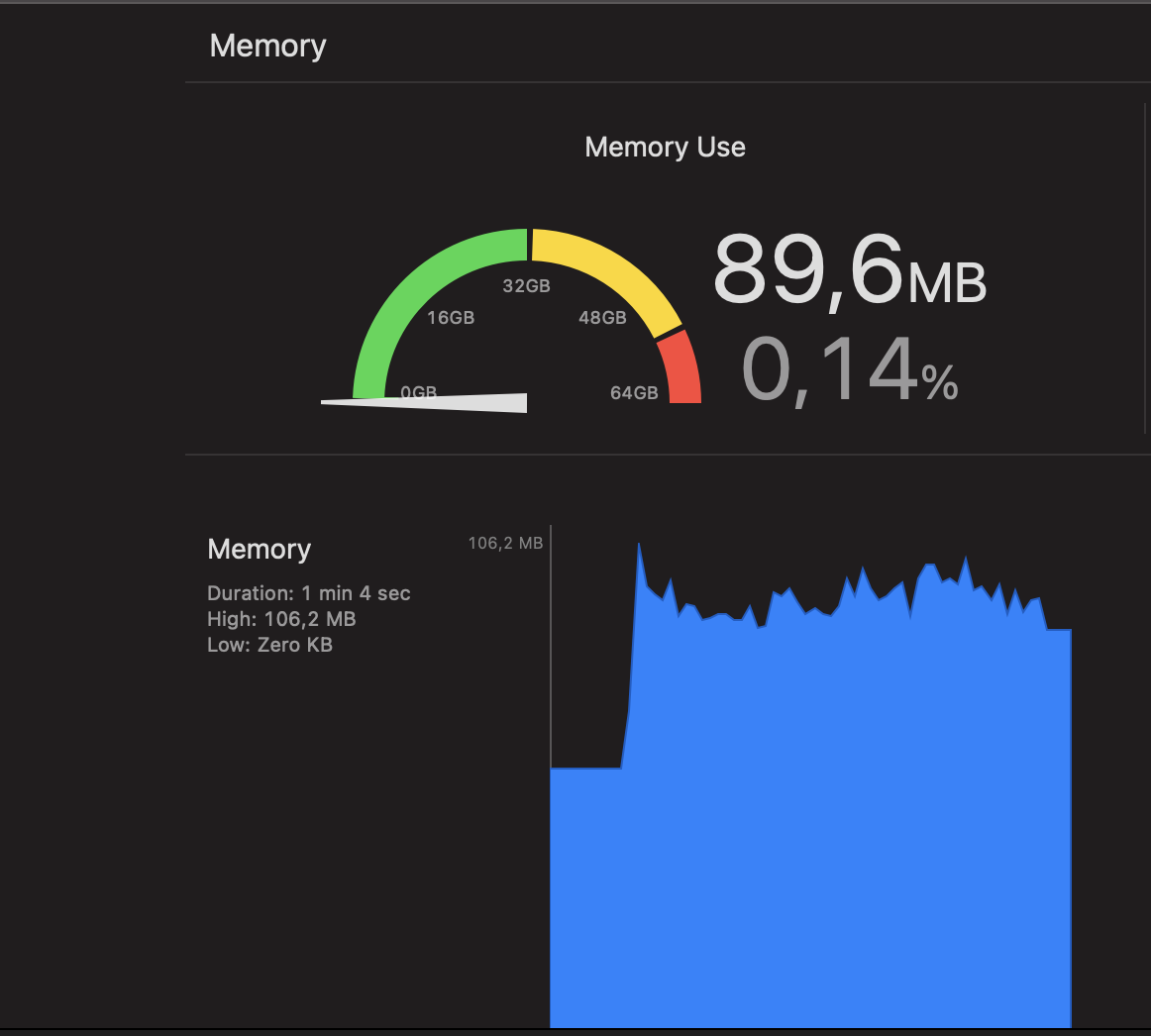
ОБНОВЛЕНИЕ: Чтобы лучше продемонстрировать разницу между всеми тремя способами, вот скриншоты отчета о памяти.
Итерация AsyncStream
AsyncStream + TaskGroup (используя
try await group.next()на каждый 5-й кусок)
GCD DispatchQueue + DispatchGroup + DispatchSemaphore
2 ответа
Основная проблема заключается в использовании . Вы читаете данные и выдаете фрагменты быстрее, чем они могут быть загружены.
Рассмотрим этот MCVE, где я имитирую поток из 100 фрагментов по 1 МБ каждый:
import os.log
private let log = OSLog(subsystem: "Test", category: .pointsOfInterest)
struct Chunk {
let index: Int
let data: Data
}
actor FileMock {
let maxChunks = 100
let chunkSize = 1_000_000
var index = 0
func nextChunk() -> Chunk? {
guard index < maxChunks else { print("done"); return nil }
defer { index += 1 }
return Chunk(index: index, data: Data(repeating: UInt8(index & 0xff), count: chunkSize))
}
func chunks() -> AsyncStream<Chunk> {
AsyncStream { continuation in
index = 0
while let chunk = nextChunk() {
os_signpost(.event, log: log, name: "chunk")
continuation.yield(chunk)
}
continuation.finish()
}
}
}
А также
func uploadAll() async throws {
try await withThrowingTaskGroup(of: Void.self) { group in
let chunks = await FileMock().chunks()
var index = 0
for await chunk in chunks {
index += 1
if index > 5 {
try await group.next()
}
group.addTask { [self] in
try await upload(chunk)
}
}
try await group.waitForAll()
}
}
func upload(_ chunk: Chunk) async throws {
let id = OSSignpostID(log: log)
os_signpost(.begin, log: log, name: #function, signpostID: id, "%d start", chunk.index)
try await Task.sleep(nanoseconds: 1 * NSEC_PER_SEC)
os_signpost(.end, log: log, name: #function, signpostID: id, "end")
}
Когда я это делаю, я вижу всплеск памяти до 150 МБ, так как быстро выдает все фрагменты заранее:

Обратите внимание, что все указатели, показывающие время создания объектов, сгруппированы в начале процесса.
Обратите внимание, документация предупреждает нас, что последовательность может предположительно генерировать значения быстрее, чем они могут быть использованы:
Произвольный источник элементов может создавать элементы быстрее, чем они потребляются вызывающей программой, выполняющей итерацию по ним. Из-за этого определяет поведение буферизации, позволяя потоку буферизовать определенное количество самых старых или самых новых элементов. По умолчанию лимит буфера
Int.max, что означает, что значение не ограничено.
К сожалению, различные варианты буферизации,
.bufferingOldestа также
.bufferingNewest, будет отбрасывать значения только при заполнении буфера. В некоторых
AsyncStreams, это может быть жизнеспособным решением (например, если вы отслеживаете местоположение пользователя, вам может быть важно только самое последнее местоположение), но при загрузке фрагментов файла вы, очевидно, не можете отбрасывать фрагменты, когда буфер исчерпан.
Итак, вместо того, чтобы просто обернуть чтение файла пользовательским , который не будет читать следующий фрагмент, пока он действительно не понадобится, что значительно снижает пиковое использование памяти, например:
struct FileMock: AsyncSequence {
typealias Element = Chunk
struct AsyncIterator : AsyncIteratorProtocol {
let chunkSize = 1_000_000
let maxChunks = 100
var current = 0
mutating func next() async -> Chunk? {
os_signpost(.event, log: log, name: "chunk")
guard current < maxChunks else { return nil }
defer { current += 1 }
return Chunk(index: current, data: Data(repeating: UInt8(current & 0xff), count: chunkSize))
}
}
func makeAsyncIterator() -> AsyncIterator {
return AsyncIterator()
}
}
А также
func uploadAll() async throws {
try await withThrowingTaskGroup(of: Void.self) { group in
var index = 0
for await chunk in FileMock() {
index += 1
if index > 5 {
try await group.next()
}
group.addTask { [self] in
try await upload(chunk)
}
}
try await group.waitForAll()
}
}
И это позволяет избежать загрузки всех 100 МБ памяти сразу. Обратите внимание, что вертикальная шкала памяти отличается, но вы можете видеть, что пиковое использование на 100 МБ меньше, чем на приведенном выше графике, а
Ⓢуказатели, показывающие, когда данные считываются в память, теперь распределяются по всему графу, а не по всем в начале:
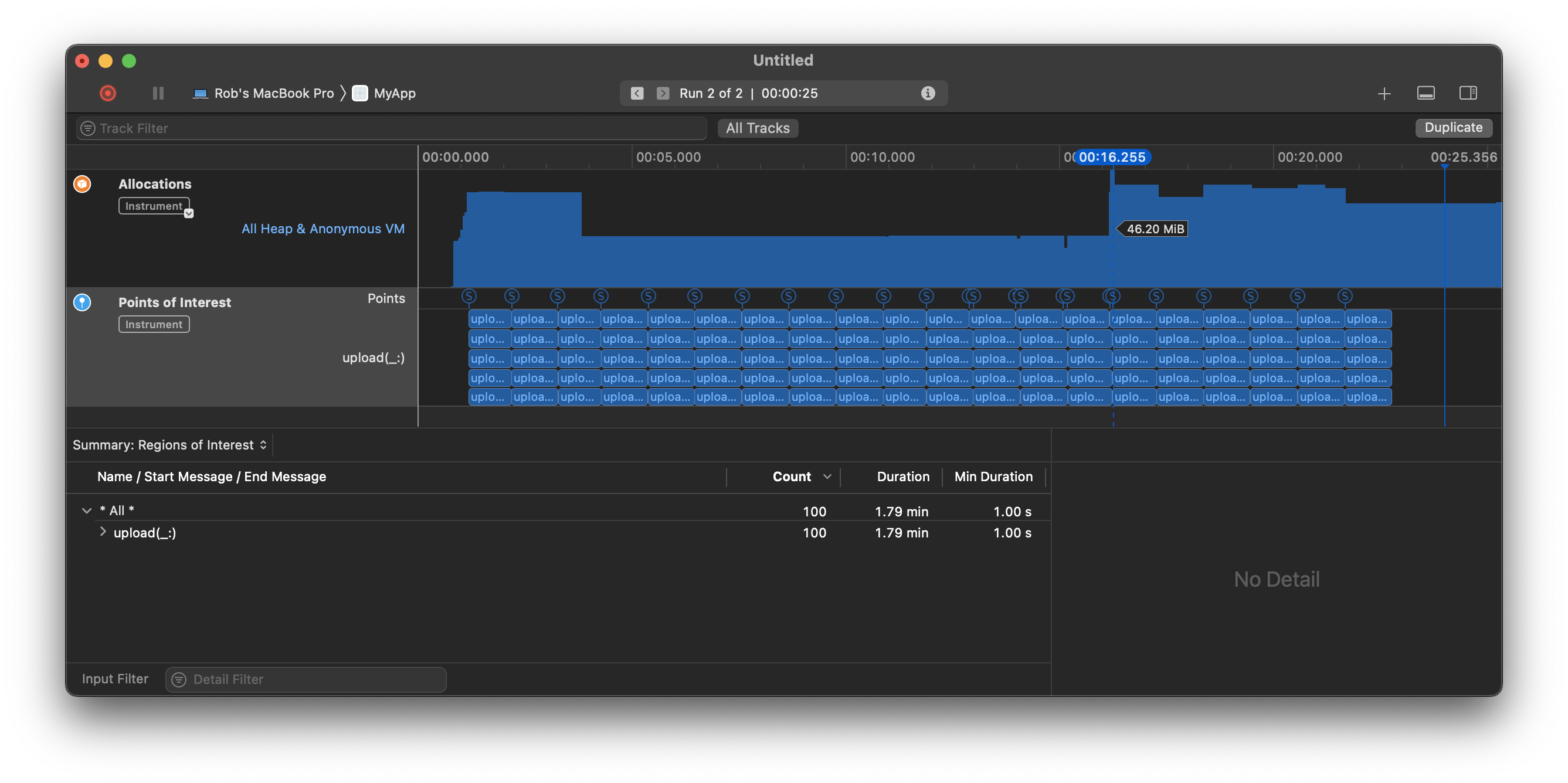
Теперь, очевидно, я только издеваюсь над чтением большого файла с
Chunk/objects и имитировать загрузку с помощью
Task.sleep, но, надеюсь, иллюстрирует основную идею.
Итог, не используйте
AsyncStreamчтобы прочитать файл, а скорее рассмотреть пользовательский
AsyncSequenceили другой шаблон, который считывает файл по мере необходимости.
Несколько других наблюдений:
Вы сказали: «Пытались поставить try await group.next() для каждого 5-го чанка». Может быть, вы можете показать нам, что вы пытались. Но обратите внимание, что в этом ответе сказано не «каждый 5-й фрагмент», а «каждый фрагмент после 5-го». Мы не можем комментировать то, что вы пробовали, если вы не покажете нам, что вы на самом деле пробовали (или не предоставите MCVE). И, как показано выше, использование инструмента Instruments «Points of Interest» может показать реальный параллелизм.
Кстати, при загрузке большого ресурса рассмотрите возможность загрузки на основе файла, а не
Data. Загрузки на основе файлов гораздо более эффективны с точки зрения использования памяти. Независимо от размера актива, память, используемая во время файлового актива, будет измеряться в килобайтах. Вы даже можете полностью отключить фрагментацию, и загрузка на основе файлов будет использовать очень мало памяти независимо от размера файла.URLSessionзагрузка файлов требует минимального объема памяти. Это одна из причин, по которой мы делаем загрузку на основе файлов.Другая причина загрузки на основе файлов заключается в том, что, особенно для iOS, загрузку на основе файлов можно сочетать с фоновым сеансом. В фоновом сеансе пользователь может даже выйти из приложения, чтобы заняться чем-то другим, а загрузка будет продолжаться в фоновом режиме. В этот момент вы можете переоценить, нужно ли вам вообще выполнять разбиение на фрагменты.
Я хотел иметь возможность помещать асинхронные задачи в очередь, что-то вроде NSOperationQueue. Я хочу ограничить максимальное количество одновременных операций, а также установить приоритеты, чтобы задачи с высоким приоритетом вытаскивались из очереди раньше, чем задачи с низким приоритетом.
Инженер Apple из лаборатории WWDC отметил, что вы можете использовать withCheckedContinuation, чтобы приостановить задачу. Это обеспечивает продолжение, которое вы затем можете вызвать, чтобы перезапустить задачу позже.
Это ключ для моего Раннера.
Вы создаете бегуна с
static let analysis = Runner(maxTasks: 2)
затем добавьте к нему задачу с помощью
try await Runner.analysis.queue(priority: Runner.Priority.high) {
[weak self] in
//Do work here
try await doSomethingExpensive()
}
Бегун заключается в следующем...
import Foundation
protocol HasPriority {
var priority:Double {get}
}
actor Runner {
//MARK: Initialisers
/// Create runner with max tasks
/// - Parameter maxTasks: count
init(maxTasks: Int) {
self.maxTasks = maxTasks
}
//MARK: Static/Class constants
//MARK: Structures (enums / errors / notifications / etc)
/// Concrete implementation of HasPriority
enum Priority:HasPriority {
case high //100
case medium //50
case low //0
case custom(Double)
//Note - date variants are not compatible other cases, oldestFirst is not compatible with newestFirst
case oldestFirst(Date)
case newestFirst(Date)
var priority: Double {
switch self {
case .high:
return 100
case .medium:
return 50
case .low:
return 0
case .custom(let value):
return value
case .oldestFirst(let date):
return -date.timeIntervalSince1970
case .newestFirst(let date):
return date.timeIntervalSince1970
}
}
}
/// Tickets hold priority and continuation information.
/// These are only modified or read by the actor after initial creation, so we don't have to worry about concurrency
/// They're the operation holder
private class Ticket:Identifiable {
internal init(priority: Double,runner:Runner) {
self.priority = priority
self.runner = runner
}
let id = UUID()
let priority:Double
private var runner:Runner
var continuation:CheckedContinuation<Void, Never>?
var running:Bool = false
func didFinish() async {
await runner.didFinish(self)
}
func run() {
running = true
continuation!.resume()
}
}
//MARK: Published vars
//MARK: Vars
private let maxTasks:Int
//MARK: Coding Keys
//MARK: Class Methods
//MARK: Instance Methods
/// Current running count
private var runningCount:Int {
return tickets.filter({ $0.running }).count
}
/// called to progress the ticket queue
private func progress() {
while(runningCount < maxTasks) {
let notRunning = tickets.filter { !$0.running }
let topPriority = notRunning.max { t1, t2 in
t1.priority < t2.priority
}
guard let topPriority else {
print("Queue emptied")
return
}
//there may be multiple elements with max priority. If so, we want to run the first
guard let next = notRunning.first(where: { $0.priority == topPriority.priority }) else {
fatalError("this should not be possible")
}
next.run()
}
}
/// Must be called when a ticket finishes to remove it from the queue
/// - Parameter ticket: ticket
private func didFinish(_ ticket:Ticket) {
//print("did finish ticket with priority: \(ticket.priority)")
tickets.removeAll { $0.id == ticket.id }
progress()
}
private var tickets:[Ticket] = []
nonisolated
/// Used in the continuation to add a ticket
/// - Parameter ticket: ticket
private func add(_ ticket:Ticket) {
Task {
await append(ticket)
}
}
/// Actor isolated function to add ticket
/// - Parameter ticket: ticket
private func append(_ ticket:Ticket) {
precondition(ticket.continuation != nil)
tickets.append(ticket)
progress()
}
nonisolated
/// Queue an async task. The task is suspended (so no thread is required), then run according to priority in the queue
/// If priorities are equal, then tasks are run in order of submission
/// - Parameters:
/// - priority: Use Runner.Priority or create your own enum which conforms to HasPriority
/// - work: the async work to do
/// - Returns: the task return value
func queue<Success>(priority:HasPriority, work:@escaping (() async throws -> Success) ) async throws -> Success {
let ticket:Ticket = Ticket(priority: priority.priority, runner: self)
defer {
Task {
await didFinish(ticket)
}
}
await withCheckedContinuation({ continuation in
ticket.continuation = continuation
self.add(ticket)
return ()
})
//If task has been cancelled while in the queue - we'll find out when we pull it off the queue and run it
try Task.checkCancellation()
return try await work()
}
}