COBOL . CSV файл IO в таблицу не работает
Я пытаюсь выучить кобол, так как слышал об этом и думал, что было бы интересно взглянуть на него. Я наткнулся на MicroFocus Cobol, не совсем уверенный, относится ли это к этому посту, и, поскольку я люблю писать в visual studio, у меня было достаточно стимулов, чтобы попытаться выучить его.
Я много читал об этом и пытался следовать документации и примерам. До сих пор у меня работали пользовательский ввод и вывод на консоль, поэтому я решил попробовать файл IO. Все прошло хорошо, когда я просто читал "запись" за раз, я понимаю, что "запись" может быть неправильным жаргоном. Хотя я программирую какое-то время, я - абсолютный новичок с коболом.
У меня есть программа на С ++, которую я написал ранее, которая просто берет файл.csv и анализирует его, а затем сортирует данные по любому столбцу, который хочет пользователь. Я подумал, что это не будет трудно сделать то же самое в Cobol. Ну, видимо, я ошибся в этом отношении.
У меня есть файл, отредактированный в Windows с помощью Notepad ++, называемый test.csv, который содержит:
4001942600,140,4
4001942700,141,3
4001944000,142,2
Эти данные взяты из переписи населения США, в которой заголовки столбцов озаглавлены: GEOID, SUMLEV, STATE. Я удалил строку заголовка, так как я не мог понять, как прочитать ее в то время, а затем прочитать другие данные. Anywho...
В Visual Studio 2015, в Windows 7 Pro 64 Bit, с использованием Micro Focus и пошаговой отладкой я вижу запись, содержащую первую строку данных. Unstring прекрасно работает для этого запуска, но в следующий раз, когда программа "зацикливается", я могу выполнить отладку, просмотреть запись и увидеть, что она содержит новые данные, однако отображение часов при раскрытии элементов наблюдения выглядит следующим образом:
REC-COUNTER 002 PIC 9(3)
+ IN-RECORD {Length = 42} : "40019427004001942700 000 " GROUP
- GEOID {Length = 3} PIC 9(10)
GEOID(1) 4001942700 PIC 9(10)
GEOID(2) 4001942700 PIC 9(10)
GEOID(3) <Illegal data in numeric field> PIC 9(10)
- SUMLEV {Length = 3} PIC 9(3)
SUMLEV(1) <Illegal data in numeric field> PIC 9(3)
SUMLEV(2) 000 PIC 9(3)
SUMLEV(3) <Illegal data in numeric field> PIC 9(3)
- STATE {Length = 3} PIC X
STATE(1) PIC X
STATE(2) PIC X
STATE(3) PIC X
Поэтому я не уверен, почему непосредственно перед операцией Unstring во второй раз я могу видеть правильные данные, но после того, как unstring произойдет, неправильные данные будут сохранены в "таблице". Также интересно то, что если я продолжу в третий раз, то правильные данные будут сохранены в "таблице".
identification division.
program-id.endat.
environment division.
input-output section.
file-control.
select in-file assign to "C:/Users/Shittin Kitten/Google Drive/Embry-Riddle/Spring 2017/CS332/group_project/cobol1/cobol1/test.csv"
organization is line sequential.
data division.
file section.
fd in-file.
01 in-record.
05 record-table.
10 geoid occurs 3 times pic 9(10).
10 sumlev occurs 3 times pic 9(3).
10 state occurs 3 times pic X(1).
working-storage section.
01 switches.
05 eof-switch pic X value "N".
* declaring a local variable for counting
01 rec-counter pic 9(3).
* Defining constants for new line and carraige return. \n \r DNE in cobol!
78 NL value X"0A".
78 CR value X"0D".
78 TAB value X"09".
******** Start of Program ******
000-main.
open input in-file.
perform
perform 200-process-records
until eof-switch = "Y".
close in-file;
stop run.
*********** End of Program ************
******** Start of Paragraph 2 *********
200-process-records.
read in-file into in-record
at end move "Y" to eof-switch
not at end compute rec-counter = rec-counter + 1;
end-read.
Unstring in-record delimited by "," into
geoid in record-table(rec-counter),
sumlev in record-table(rec-counter),
state in record-table(rec-counter).
display "GEOID " & TAB &">> " & TAB & geoid of record-table(rec-counter).
display "SUMLEV >> " & TAB & sumlev of record-table(rec-counter).
display "STATE " & TAB &">> " & TAB & state of record-table(rec-counter) & NL.
************* End of Paragraph 2 **************
Я очень озадачен тем, почему я могу видеть данные после операции чтения, но они не сохраняются в таблице. Я попытался изменить объявления таблицы на рис. 9(некоторой длины), и результат изменился, но я не могу точно определить, что я не получаю по этому поводу.
2 ответа
Я думаю, что есть несколько вещей, которые вы еще не поняли, и которые вам нужно.
в DATA DIVISIONЕсть несколько разделов, каждый из которых имеет определенное назначение.
FILE SECTION где вы определяете структуры данных, которые представляют данные в файлах (ввод, вывод или ввод-вывод). Каждый файл имеет FDи подчиняться FD будет одна или несколько структур уровня 01, которые могут быть чрезвычайно простыми или сложными.
Некоторое точное поведение зависит от конкретной реализации для компилятора, но вы должны относиться к этому таким образом, для вашего собственного "минимального удивления" и для тех же, кто должен впоследствии вносить изменения в ваши программы: для входного файла не делайте t изменить данные после READ, если только вы не собираетесь обновить запись (например, если вы используете READ с ключом). Вы можете рассматривать "область ввода" как "окно" в вашем файле данных. Далее ПРОЧИТАЙТЕ, и окно будет указано на другую позицию. В качестве альтернативы, вы можете рассматривать это как "прибывает следующая запись, стирающая то, что было раньше". Вы поместили "результат" вашего UNSTRING в область записи. Результат наверняка исчезнет при следующем чтении. У вас есть возможность (если окно верно для вашего компилятора, и в зависимости от механизма, который оно использует для ввода-вывода), также уничтожение "следующих" данных.
Ваш результат должен быть в РАБОЧЕМ ХРАНИЛИЩЕ, где он не будет нарушен при чтении новых записей.
ЧИТАЙТЕ имя файла INTO data-description - неявное ПЕРЕМЕЩЕНИЕ данных из области записи в описание данных. Если, как вы указали, data-description является областью записи, результатом будет "undefined". Если вам нужны только данные в области записи, достаточно просто прочитать READ-имя файла.
У вас есть похожая проблема с вашим оригинальным UNSTRING. У вас есть исходное и целевое поля, ссылающиеся на одно и то же хранилище. "Не определено", а не результат, который вы хотите. Именно поэтому ненужное UNSTRING "сработало".
У вас есть избыточный встроенный PERFORM. Вы обрабатываете "что-то" после конца файла. Вы делаете вещи более запутанными, используя ненужную "пунктуацию" в ПРОЦЕДУРЕ РАЗДЕЛА (которую вы, очевидно, пропустили, чтобы вставить). Попробуйте использовать ADD вместо COMPUTE. Посмотрите на использование FILE STATUS и 88-уровневых имен условий.
Вам не нужна "новая линия" для DISPLAYпотому что вы получаете один бесплатно, если вы не используете NO ADVANCING,
Вам не нужно "объединять" в DISPLAY, потому что вы получаете это также бесплатно.
DISPLAY и его двоюродный брат, ACCEPT, являются глаголами (только встроенные функции являются функциями в COBOL (кроме случаев, когда ваш компилятор поддерживает пользовательские функции)), которые больше всего варьируются от компилятора к компилятору. Если ваш компилятор поддерживает SCREEN SECTION в DATA DIVISION вы можете форматировать и обрабатывать пользовательский ввод в "экранах". Если бы вы использовали IBM Enterprise COBOL, у вас был бы очень простой DISPLAY/ACCEPT.
Вы "объявляете локальную переменную". Вы? В каком смысле? Локально для программы.
Вы можете получить довольно много советов, взглянув на вопросы COBOL за последние несколько лет.
Ну, я понял это. Во время пошаговой отладки снова и наведения мыши на record-table Я заметил 26 пробелов, присутствующих после последнего поля данных. Ранее, сегодня вечером, я попытался изменить эти данные на лету, потому что обычно визуальная студия это позволяет. Я попытался внести изменение, но не подтвердил, что оно потребовалось, как правило, мне не нужно, но, видимо, это не так. Теперь я должен был знать лучше, так как значок отображается слева от record-table отображает маленький закрытый замок на замок.
Обычно я программирую на C, C++ и C#, поэтому, когда я вижу небольшую блокировку клавиш, это обычно связано с областью видимости и видимостью. Не зная КОБОЛ достаточно хорошо, я упустил из виду эту маленькую деталь.
Теперь я решил unstring in-record delimited by spaces into temp-string. незадолго до
Unstring temp-string delimited by "," into
geoid in record-table(rec-counter),
sumlev in record-table(rec-counter),
state in record-table(rec-counter).
Результатом этого были правильно отформатированные данные, по крайней мере, насколько я понимаю, сохраненные в таблице и распечатанные на экране консоли.
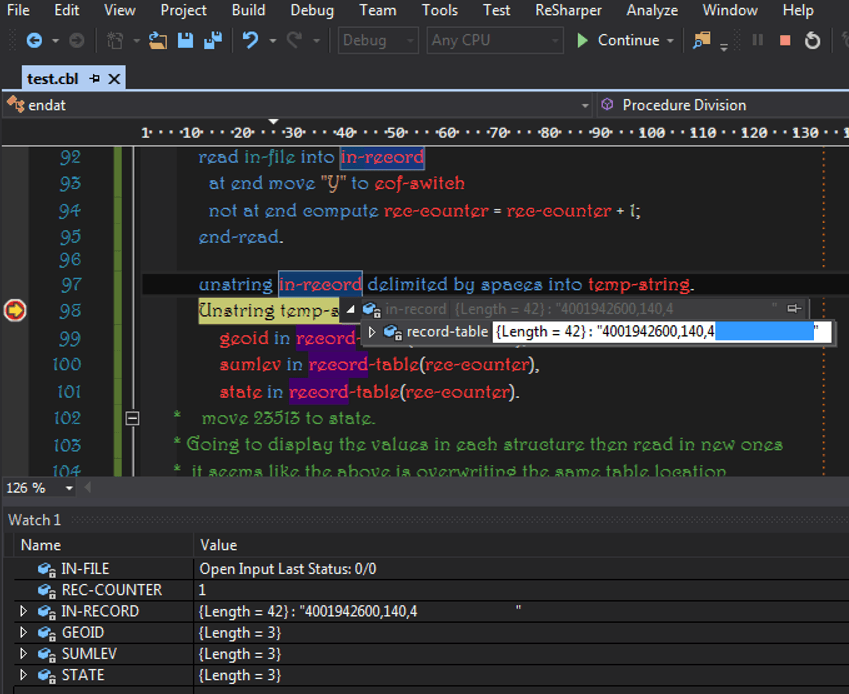
Теперь я прочитал, что unstring "функция" может использовать несколько "операторов", например, поэтому я могу попытаться объединить эти два unstring операции в одну.
Ура!
**** Обновить ****
Я прочитал ответ мистера Вуджера ниже. Если бы я мог попросить немного больше помощи с этим. Я также прочитал этот пост, который похож на этот уровень, но выше моего уровня. COBOL читать / хранить в таблице
Это в значительной степени то, что я пытаюсь сделать, но я не понимаю некоторые вещи, которые мистер Вуджер пытается объяснить. Ниже код немного уточнен с некоторыми вопросами, которые у меня есть в качестве комментариев. Мне бы очень хотелось помочь с этим или, может быть, я мог бы иметь разговор в автономном режиме, что было бы тоже хорошо.
`identification division.
* I do not know what 'endat' is
program-id.endat.
environment division.
input-output section.
file-control.
* assign a file path to in-file
select in-file assign to "C:/Users/Shittin Kitten/Google Drive/Embry-Riddle/Spring 2017/CS332/group_project/cobol1/cobol1/test.csv"
* Is line sequential what I need here? I think it is
organization is line sequential.
* Is the data devision similar to typedef in C?
data division.
* Does the file sectino belong to data division?
file section.
* Am I doing this correctly? Should this be below?
fd in-file.
* I believe I am defining a structure at this point
01 in-record.
05 record-table.
10 geoid occurs 3 times pic A(10).
10 sumlev occurs 3 times pic A(3).
10 state occurs 3 times pic A(1).
* To me the working-storage section is similar to ADA declarative section
* is this a correct analogy?
working-storage section.
* Is this where in-record should go? Is in-record a representative name?
01 eof-switch pic X value "N".
01 rec-counter pic 9(1).
* I don't know if I need these
78 NL value X"0A".
78 TAB value X"09".
01 sort-col pic 9(1).
********************************* Start of Program ****************************
*Now the procedure division, this is alot like ada to me
procedure division.
* Open the file
perform 100-initialize.
* Read data
perform 200-process-records
* loop until eof
until eof-switch = "Y".
* ask user to sort by a column
display "Would which column would you like to bubble sort? " & TAB.
* get user input
accept sort-col.
* close file
perform 300-terminate.
* End program
stop run.
********************************* End of Program ****************************
******************************** Start of Paragraph 1 ************************
100-initialize.
open input in-file.
* Performing a read, what is the difference in this read and the next one
* paragraph 200? Why do I do this here instead of just opening the file?
read in-file
at end
move "Y" to eof-switch
not at end
* Should I do this addition here? Also why a semicolon?
add 1 to rec-counter;
end-read.
* Should I not be unstringing here?
Unstring in-record delimited by "," into geoid of record-table,
sumlev of record-table, state of record-table.
******************************** End of Paragraph 1 ************************
********************************* Start of Paragraph 2 **********************
200-process-records.
read in-file into in-record
at end move "Y" to eof-switch
not at end add 1 to rec-counter;
end-read.
* Should in-record be something else? I think so but don't know how to
* declare and use it
Unstring in-record delimited by "," into
geoid in record-table(rec-counter),
sumlev in record-table(rec-counter),
state in record-table(rec-counter).
* These lines seem to give the printed format that I want
display "GEOID " & TAB &">> " & TAB & geoid of record-table(rec-counter).
display "SUMLEV >> " & TAB & sumlev of record-table(rec-counter).
display "STATE " & TAB &">> " & TAB & state of record-table(rec-counter) & NL.
********************************* End of Paragraph 2 ************************
********************************* Start of Paragraph 3 ************************
300-terminate.
display "number of records >>>> " rec-counter;
close in-file;
**************************** End of Paragraph 3 *****************************
`