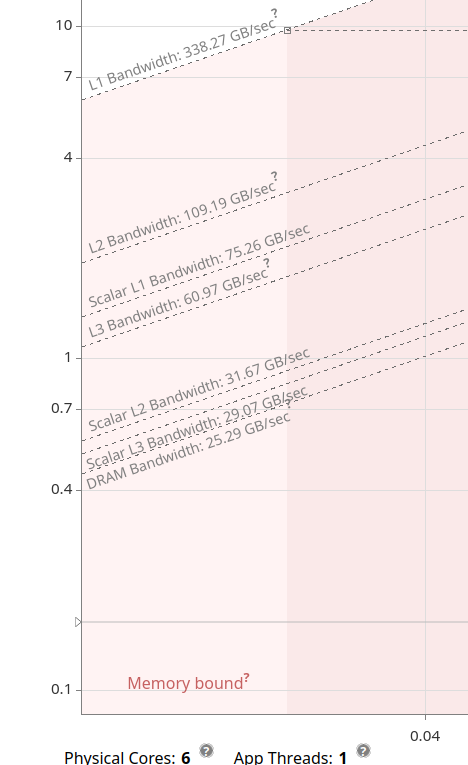
Информация о пропускной способности Intel Advisor
При использовании представления анализа крыши Intel Advisor нам предоставляется информация о пропускной способности данных для различных путей данных системы, т. е. кэшей DRAM, L3, L2 и L1. Программа утверждает, что она измеряет пропускную способность на предоставленном оборудовании, т.е. это не теоретические оценки или информация из ОС.
Вопрос
Почему пропускная способность DRAM составляет 25 ГБ/с для одного потока?
Код (для компилятора Intel)
Чтобы увидеть, сколько данных компьютер может поднять в кратчайшие сроки, используя все доступные вычислительные ресурсы, можно концептуализировать первую попытку:
// test-parameters
const auto size = std::size_t{50 * 1024 * 1024} / sizeof(double);
const auto experiment_count = std::size_t{500};
//+/////////////////
// access a data-point 'on a whim'
//+/////////////////
// warm-up
for (auto counter = std::size_t{}; counter < experiment_count / 2; ++counter)
{
// garbage data allocation and memory page loading
double* data = nullptr;
posix_memalign(reinterpret_cast<void**>(&data), sysconf(_SC_PAGESIZE), size * sizeof(double));
if (data == nullptr)
{
std::cerr << "Fatal error! Unable to allocate memory." << std::endl;
std::abort();
}
//#pragma omp parallel for simd safelen(8) schedule(static)
for (auto index = std::size_t{}; index < size; ++index)
{
data[index] = -1.0;
}
// clear cache
double* cache_clearer = nullptr;
posix_memalign(reinterpret_cast<void**>(&cache_clearer), sysconf(_SC_PAGESIZE), size * sizeof(double));
if (cache_clearer == nullptr)
{
std::cerr << "Fatal error! Unable to allocate memory." << std::endl;
std::abort();
}
//#pragma omp parallel for simd safelen(8) schedule(static)
#pragma optimize("", off)
for (auto index = std::size_t{}; index < size; ++index)
{
cache_clearer[index] = -1.0;
}
#pragma optimize("", on)
//#pragma omp parallel for simd safelen(8) schedule(static)
#pragma omp simd safelen(8)
for (auto index = std::size_t{}; index < size; ++index)
{
data[index] = 10.0;
}
// deallocate resources
free(data);
free(cache_clearer);
}
// timed run
auto min_duration = std::numeric_limits<double>::max();
for (auto counter = std::size_t{}; counter < experiment_count; ++counter)
{
// garbage data allocation and memory page loading
double* data = nullptr;
posix_memalign(reinterpret_cast<void**>(&data), sysconf(_SC_PAGESIZE), size * sizeof(double));
if (data == nullptr)
{
std::cerr << "Fatal error! Unable to allocate memory." << std::endl;
std::abort();
}
//#pragma omp parallel for simd safelen(8) schedule(static)
for (auto index = std::size_t{}; index < size; ++index)
{
data[index] = -1.0;
}
// clear cache
double* cache_clearer = nullptr;
posix_memalign(reinterpret_cast<void**>(&cache_clearer), sysconf(_SC_PAGESIZE), size * sizeof(double));
if (cache_clearer == nullptr)
{
std::cerr << "Fatal error! Unable to allocate memory." << std::endl;
std::abort();
}
//#pragma omp parallel for simd safelen(8) schedule(static)
#pragma optimize("", off)
for (auto index = std::size_t{}; index < size; ++index)
{
cache_clearer[index] = -1.0;
}
#pragma optimize("", on)
const auto dur1 = omp_get_wtime() * 1E+6;
//#pragma omp parallel for simd safelen(8) schedule(static)
#pragma omp simd safelen(8)
for (auto index = std::size_t{}; index < size; ++index)
{
data[index] = 10.0;
}
const auto dur2 = omp_get_wtime() * 1E+6;
const auto run_duration = dur2 - dur1;
if (run_duration < min_duration)
{
min_duration = run_duration;
}
// deallocate resources
free(data);
free(cache_clearer);
}
Примечания к коду:
- Предполагается, что это «наивный» подход, также предназначенный только для Linux. Должен по-прежнему служить приблизительным показателем производительности модели,
- использование флагов компилятора
-O3 -ffast-math -march=native, - размер должен быть больше кэша самого низкого уровня системы (здесь 50 МБ),
- новые выделения на каждой итерации должны аннулировать все строки кеша из предыдущей (чтобы исключить попадания в кеш),
- записывается минимальная задержка, чтобы противодействовать эффектам планирования ОС: потоки на короткое время отключаются от ядер и т. д.,
- выполняется прогревочный прогон, чтобы противодействовать эффектам динамического масштабирования частоты (функция ядра, альтернативно может быть отключена с помощью
userspaceгубернатор).
Результаты кода
На моей машине, используя инструкции AVX2 (максимально доступные векторные инструкции), я реализую макс. пропускная способность 5,6 ГБ/с.
РЕДАКТИРОВАТЬ
Следуя комментарию @Peter Cordes, я адаптировал свой код, чтобы обеспечить размещение страницы памяти. Теперь мой измеренный BW составляет 90 ГБ/с. Есть объяснение, почему он такой высокий?