После выполнения git reset --soft HEAD^, как мне удалить файлы, которые не нужны моему репозиторию?
мне пришлось бежать
git reset --soft HEAD^
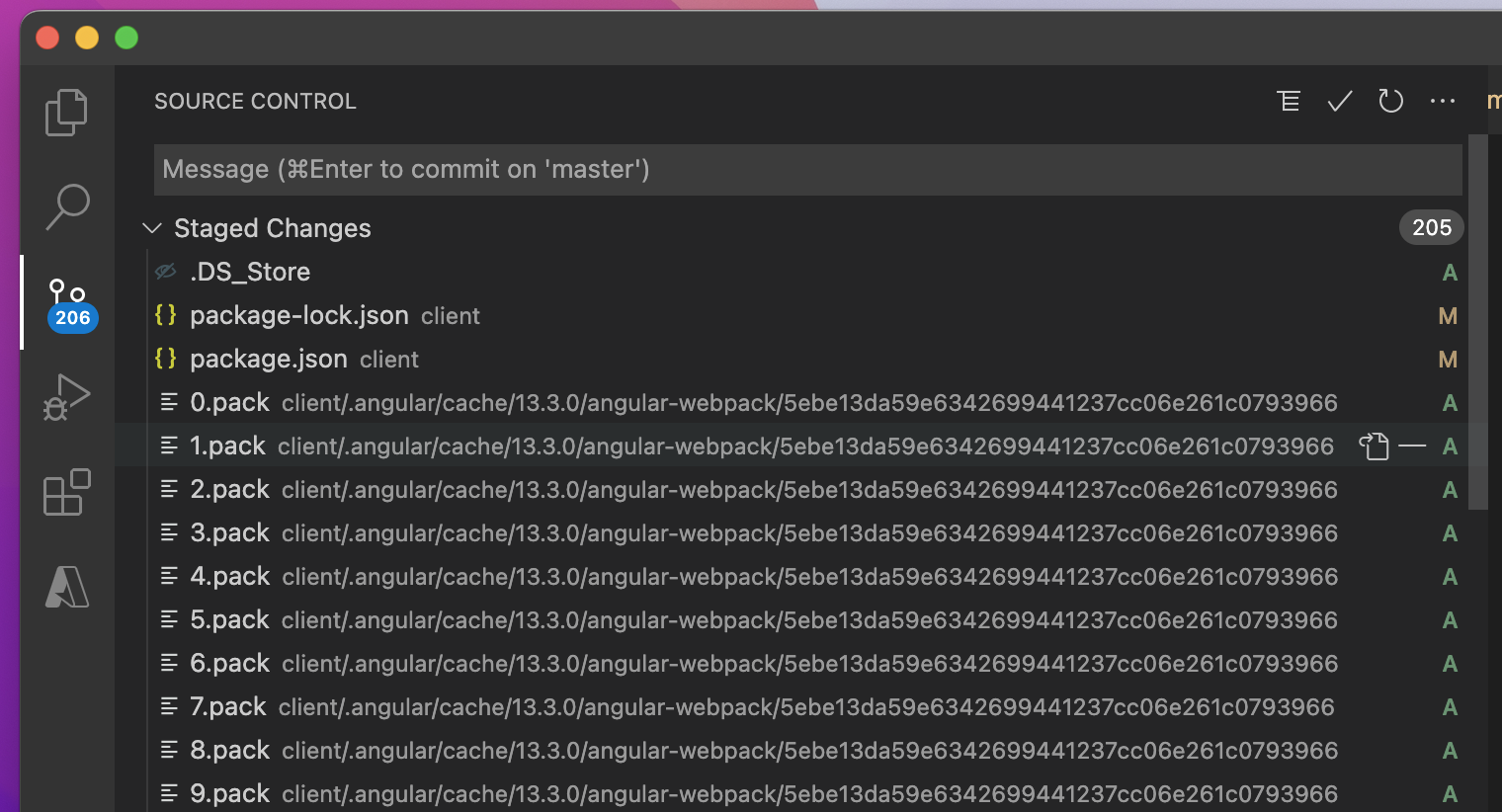
отменить фиксацию с большими файлами (такая же проблема ). Теперь я снова вижу свои файлы в VS Code Source Control Explorer(см. ниже)
Проблема - я хочу удалить эти файлы из добавления в мое репо при фиксации и последующем нажатии, поэтому я добавил
/.угловой/кэш
в мой файл .gitignore, но это не удалило файлы из окна системы управления версиями.
Вопрос . Нужно ли мне делать что-то еще, чтобы удалить эти файлы из системы управления версиями? бывший. отключить каждый файл по отдельности
Контроль версий в VS Code:
2 ответа
TL;DR Резюме
Как предположил в комментарии chepner , вы, наверное, действительно хотели сброс, а не сброс. Однако, как добавил j6t , вы можете исправить эту ошибку, используя
Вы по-прежнему захотите создать или обновить свой, чтобы случайно не добавить
Если бы вы использовали (или значение по умолчанию ), вам , возможно, пришлось бы добавить некоторые другие файлы помимо , но вы могли бы сначала обновить файл, а затем использовать стандартную «добавить все» (), чтобы добавить все, кроме текущего неотслеживаемого-и -игнорируемые файлы. Это, как правило, легче сделать правильно , поэтому это рекомендуемый метод. Но добавляешь все, потом не добавляешь(
Необходимая предыстория (длинная)
Git — это все о коммитах . Git — это не файлы , хотя Git фиксирует файлы, а Git — не ветки , хотя имена веток Git помогают вам (и Git) находить коммиты. Таким образом, вам нужно знать, что такое коммит Git и что он делает для вас, и как создается новый коммит. Итак, давайте сначала слегка коснемся коммитов.
Коммит Git - это...
Репозиторий Git по своей сути состоит из двух баз данных. В одной базе данных хранятся коммиты и другие вспомогательные объекты , а в отдельной базе данных хранятся имена — имена ветвей, имена тегов и другие имена, которые помогают Git находить коммиты. Важна именно база коммитов и других объектов: можно использовать репозиторий, в котором база имен совершенно пуста (просто это делать крайне неудобно и неприятно), но нельзя использовать репозиторий, в котором база данных объектов пуста.
Не обращая внимания на поддержку здесь, мы просто поговорим об объектах фиксации, так как это те, с которыми вы взаимодействуете. Все объекты, включая коммиты, пронумерованы , но их номера — это большие уродливые случайные вещи, такие как
f01e51a7cfd75131b7266131b1f7540ce0a8e5c1. Хэш - идентификаторы коммитов всегда полностью уникальны. Итак, если у вас есть этот коммит (тот, который начинается с
Система нумерации требует, чтобы после сохранения ничего не менялось. Таким образом, большая база данных всех объектов, которую вы найдете в репозитории Git, полностью доступна только для чтения; все, что вы когда-либо делаете, это добавляете к этому.1
Помимо нумерации, каждый коммит:
Содержит полный снимок каждого файла в сжатом виде и (что важно для внутренней работы Git и для ваших потребностей в дисковом пространстве) без дублирования . То есть, когда вы делаете новую фиксацию, если у вас есть миллион файлов, но вы изменили только три из них, новая фиксация не дублирует все 1 миллион файлов: она повторно использует все, кроме новых трех.
Эти моментальные снимки похожи на архивы tar или WinZip в том смысле, что вы можете просто заставить Git извлечь из них все файлы в любое время. Но это не обычные файлы: это особые вещи, сжатые и дедублированные только Git, которые только Git может прочитать, и ничто — даже сам Git — не может перезаписать. Вот почему их безопасно использовать для нескольких коммитов.
Содержит некоторые метаданные, такие как имя и адрес электронной почты человека, совершившего фиксацию. Ваше сообщение журнала также попадает сюда, когда вы делаете коммит. Что важно для внутренней работы Git, Git добавляет к этим метаданным список хэш-идентификаторов предыдущих коммитов , которые Git называет родительскими для этого коммита.
Большинство коммитов имеют только одного родителя. То есть в большинстве коммитов указан один идентификатор предыдущего коммита. Это приводит к простой обратной цепочке. Предположим, это хэш-идентификатор вашего последнего коммита. Мы нарисуем это со стрелкой, выходящей из него, указывающей, что она указывает на его родительский коммит (путем сохранения хэш-идентификатора родителя):
<-H
Для краткости мы назовем хэш-идентификатор родительского коммита и нарисуем в коммите:
<-G <-H
Конечно, это тоже коммит, поэтому у него есть список родителей; это типичный коммит, поэтому у него есть только один родитель, который мы назовем , и нарисуем:
... <-F <-G <-H
Так вот как показывает вам история. История — это не что иное, как коммиты.Коммиты — это история;
На данный момент есть только одна неприятная маленькая проблема, а именно: чтобы использовать это, нам нужно запомнить хотя бы один хэш-идентификатор коммита Git. Как мы собираемся найти commit ? Как мы узнаем, что это последний коммит? Вот тут и появляются названия ветвей.
1 Git время от времени будет засовывать сюда «мусор», а позже сам очистит его. Поэтому называть его только добавлением технически немного неправильно. Но если у вас нет действительно огромных файлов (петабайты за раз) или у вас смехотворно маленькие квоты на хранение, вам обычно не нужно об этом беспокоиться.
Названия веток помогают найти коммиты
Нарисуем нашу маленькую диаграмму, на этот раз не заморачиваясь со стрелками (от лени):
...--G--H
Нам нужен способ быстро найти случайно выглядящий хэш ID. Git будет хранить этот хэш-идентификатор в имени ветки , например или
...--G--H <-- main
То есть имя ветки будет содержать необработанный хэш-идентификатор коммита. Нам не нужно запоминать это самим: мы заставим Git сделать эту работу, заставив Git сохранить хэш-идентификатор под именем .
Если мы создадим еще одно новое имя ветки:
...--G--H <-- develop, main
то прямо сейчас оба имени указывают на один и тот же коммит . Но это скоро изменится, так что теперь нам нужно знать, какое из этих имен мы на самом деле используем для поиска коммита. Допустим, мы используем
...--G--H <-- develop (HEAD), main
Новые коммиты, часть 1: что происходит с именами веток
Не объясняя (пока) как Git делает снимок для нового коммита, скажем, теперь мы делаем новый коммит, который получает новый, совершенно уникальный, большой уродливый случайный хэш-идентификатор, который мы просто назовем так что нам не нужно догадываться.
Commit будет хранить один снимок всех файлов, а также некоторые метаданные. В метаданные для , Git добавит наше имя и адрес электронной почты, наше сообщение в журнале, текущую дату и время, и, чтобы история работала, Git установит (единственный) родитель нового коммита как существующий коммит.
Git знает, что нужно использовать этот хэш-идентификатор, потому что имя, к которому
I
/
...--G--H
Теперь Git делает свой хитрый трюк.Имя указывало раньше и до сих пор указывает. Но Git, выделив новый хэш-идентификатор для нового коммита, указывает текущее имя на now:
I <-- develop (HEAD)
/
...--G--H <-- main
Так что теперь, если мы используем имя, мы получаем фиксацию, а если мы используем имя, мы возвращаемся к фиксации. Если мы сделаем еще один новый коммит, у нас будет
Обратите внимание, что , по мнению Git , коммиты вверх и вниз находятся в обеих ветвях .
Новые коммиты, часть 2: Откуда берется снимок?
Мы отметили выше, в начале этого, что все коммиты Git являются постоянными (ну, в основном 2 ) и доступны только для чтения (полностью). Более того, ничто не может писать в файлы в коммите, и только сам Git может даже читать эти файлы. Так как же мы вообще должны выполнять какую-либо работу?
Тот факт, что снимок в коммите подобен архиву, дает нам первую часть ответа. Чтобы проверить фиксацию (с
Эти файлы входят в то, что Git называет вашим рабочим деревом или рабочим деревом . Это буквально место, где вы делаете свою работу. Вы не работаете с файлами, которые находятся в Git. Вы работаете с файлами, которых нет в Git, вместо этого они извлекаются в вашу рабочую область. Почти все системы контроля версий (VCS) работают таким образом по той простой причине, что сохраненные файлы, преобразованные в VCS , имеют некоторый внутренний формат.
Если бы Git был похож на большинство других систем управления версиями, мы бы остановились здесь, с двумя копиями каждого файла из текущего коммита: одна навсегда хранится внутри коммита, а другая пригодна для использования. Вы будете работать с пригодными для использования файлами, а затем использовать действие «сделать новую фиксацию», и Git сделает новую фиксацию из обновленных файлов.
Гит не такой.Вместо этого у Git есть еще один трюк в рукаве. 3 Вместо того, чтобы хранить две копии каждого файла — зафиксированную и рабочую — Git хранит три копии каждого файла. Вернее, три «копии»: между зафиксированной копией и рабочей копией Git хранит дополнительную «копию», хранящуюся в сжатом и дедуплицированном формате , но не доступном только для чтения. Поскольку эта копия не дублируется, она изначально используется совместно с зафиксированной копией. Однако дедупликация невидима, поэтому нам не нужно об этом беспокоиться: мы можем просто думать о ней как о третьей копии.
Другими словами, вместо того, чтобы просто:
HEAD commit working tree
----------- ------------
Makefile Makefile
README.txt README.txt
main.py main.py
у нас есть третья копия каждого файла, которую Git называет — в стиле Git — тремя разными именами: индекс , промежуточная область или (редко в наши дни) кеш . Все три имени относятся к одному и тому же, и я буду использовать здесь указатель имен , но область подготовки ближе к тому, как вы в основном ее используете, поэтому не стесняйтесь использовать это имя в своей голове:
HEAD commit index working tree
----------- ---------- ------------
Makefile Makefile Makefile
README.txt README.txt README.txt
main.py main.py main.py
Когда вы меняете копию рабочего дерева , с копией индекса ничего не происходит . Вы должны регулярно бегать; команда означает , что копия индекса соответствует копии рабочего дерева . Git со временем прочитает копию рабочего дерева, сожмет ее в формат Git, проверит на наличие дубликатов , а затем:
- если это дубликат: выбросьте индексную копию (если она есть: если это новое имя файла, здесь нет индексной копии) и поместите дубликат;
- если это не дубликат: выбросить индексную копию (если она есть) и поместить в сжатом виде
и теперь в любом случае копия индекса именованного файла соответствует копии рабочего дерева (и предварительно дедуплицирована).
Это означает, что копия индекса всегда готова к следующему коммиту. Таким образом, то, что находится в промежуточной области, войдет в следующую фиксацию . По сути, это предлагаемая следующая фиксация . Вы редактируете файлы в своем рабочем дереве только для того, чтобы отредактировать их, а затем используете для обновления предложенного следующего коммита .
2 Коммит, который вы не можете найти , в конце концов исчезнет по-настоящему. Мы увидим это через некоторое время, когда поговорим подробнее о .
3 Что за рубашку или что там вообще носит Гит?
Новые коммиты: сводка
Поскольку индекс всегда содержит предлагаемую следующую фиксацию , все, что нужно сделать, это:
- собрать все необходимые метаданные, включая текущий идентификатор хэша коммита;
- прямо сейчас запишите все, что находится в индексе Git, в качестве нового снимка: он предварительно дедуплицирован и готов к работе;
- сохранить новый коммит, получив новый уникальный хэш-идентификатор; а также
- обновите имя текущей ветки , чтобы новая фиксация была последней фиксацией в этой ветке.
Давайте воспользуемся нашим тестовым репозиторием, который на данный момент выглядит так:
I--J <-- develop (HEAD)
/
...--G--H <-- main
и наблюдайте за действием, когда мы или делаем новое имя ветки , переключаемся на это новое имя, а затем делаем новую фиксацию:
удаляет (из индекса и рабочего дерева) файлы текущего коммита (файлы из
извлечь
оставляет нам это:
I--J develop / ...--G--H <-- main (HEAD)
создает новое имя ветки, указывающее на ;
переключается на него: это потребует удаления файлов и установки файлов из , но Git видит, что это бессмысленно, и пропускает это;
оставляет нам это:
I--J develop / ...--G--H <-- feature (HEAD), main
Теперь мы модифицируем некоторые файлы в рабочем дереве. Пока ничего не происходит с индексом Git, но затем мы запускаем эти файлы, и теперь версии в индексе
Если мы хотим, мы можем создавать новые файлы с нуля и добавлять их. Или мы можем полностью удалить файл полностью, с помощью
Теперь бежим. Git упаковывает все, что находится в индексе прямо сейчас , и делает новую фиксацию, которая обновляет имя текущей ветки , т. е., поэтому мы получаем:
I--J develop / ...--G--H <-- main \ K <-- feature (HEAD)
Обратите внимание, как просто добавляется к рисунку. Нет существующих изменений фиксации. Если в коммите есть какие-то файлы, которые мы удалили при создании, это просто означает, что в коммите этих файлов нет. Они все еще там в фиксации
Имея в виду все вышесказанное, теперь мы можем понять, что делает — или, по крайней мере, что
Предположим, мы сделали еще один коммит:
I--J develop
/
...--G--H <-- main
\
K--L <-- feature (HEAD)
и мы внезапно понимаем, что фиксация по какой-то причине была ужасной: неправильный снимок, плохое сообщение фиксации, что угодно. У нас есть несколько вариантов, но самый простой — использовать . Эта команда является ложью: она не изменяет commit , она просто создает новую фиксацию, у которой commit является родительской:
I--J develop
/
...--G--H <-- main
\
K--L' <-- feature (HEAD)
\
L
Коммит все еще существует . Мы просто больше не можем его найти, потому что используем имена , а не хэш-идентификаторы. Имя теперь находит "исправленный" коммит
Команда работает, позволяя нам переместить имя текущей ветки . Мы можем выбрать любую фиксацию и сделать так, чтобы имя указывало на эту фиксацию. Например, мы можем выбрать commit
I--J develop
/
...--G--H <-- main
\
K <-- feature (HEAD)
\
L
Коммит все еще существует , но имя
Если мы используем , Git перемещает имя ветки, а затем останавливается: индекс и рабочее дерево все еще из коммита.
Если мы используем
Если мы используем
Таким образом, этот вид может делать до трех вещей:
- переместить ветку;
- сбросить индекс; а также
- сброс рабочего дерева тоже.
Флаги сообщают ему, когда остановиться:
Если мы хотим, мы можем
- переместить ветку: найти текущий коммит, на который сейчас указывает ветка, и переместить ветку так, чтобы она указывала на текущий коммит;
- сбросить индекс; а также
- сбросить рабочее дерево.
Поскольку фиксация, которую мы выбрали на шаге 1, — это фиксация, на которую уже указывает имя , часть «переместить ветку» не выполнялась. На самом деле имя никуда не сдвинулось. Мы использовали это для шагов 2 и 3. Он по-прежнему выполнял шаг 1, просто он ничего не добился , выполнив шаг 1.
Мы можем использовать
4 Этот синтаксис — суффикс
Почему значение по умолчанию (т. е. смешанное) — это то, что вы хотели
С использованием:
git reset HEAD^
у вас будет:
- переместил название ветки на один шаг назад и
- сбросить индекс Git, чтобы он содержал файлы из выбранного коммита; но
- не сбрасывать рабочее дерево (поскольку
Теперь вы можете добавить в индекс каждый из файлов, которые вы хотите создать или обновить, а не файлы, которые вы не хотите обновлять в индексе. Другими словами, теперь вы можете делать то же самое, что и обычно, с Git.
Используя
Приложение 1: почему
неправильно
Git всегда делает новые коммиты из файлов, находящихся в индексе Git. Таким образом, одной из задач команды является сообщение вам о файлах в вашем рабочем дереве , которые не соответствуют копиям в индексе Git.
То есть предположим, что вы изменили содержимое трех файлов, которое было в них ранее. Затем вы побежали на одном из них. Давайте перечислим, что находится в каждой из трех «активных» копий каждого файла, добавив номер версии. Вы начали с:
HEAD commit index working tree
----------- ---------- ------------
Makefile(1) Makefile(1) Makefile(1)
README.txt(1) README.txt(1) README.txt(1)
main.py(1) main.py(1) main.py(1)
После изменения всех трех файлов в рабочем дереве у вас есть:
HEAD commit index working tree
----------- ---------- ------------
Makefile(1) Makefile(1) Makefile(2)
README.txt(1) README.txt(1) README.txt(2)
main.py(1) main.py(1) main.py(2)
Теперь вы бежите
HEAD commit index working tree
----------- ---------- ------------
Makefile(1) Makefile(1) Makefile(2)
README.txt(1) README.txt(1) README.txt(2)
main.py(1) main.py(2) main.py(2)
Одна из задач — сравнивать копии индекса и рабочего дерева и жаловаться, если они не совпадают . Результатом является жалоба на то, что вы забыли эти два файла.
Индексная копия каждого файла имеет два специальных флага, которые вы можете установить:
- "предполагать неизменным"
- "пропустить рабочее дерево"
Эти два флага имеют разные цели , но оба они в настоящее время реализованы одинаково: они оба позволяют не беспокоиться о файлах, когда они не совпадают.
Бег
Приложение 2: о файлах
Перечисление файлов в a не влияет на то, находятся ли файлы в индексе Git. Файл, который сейчас находится в индексе Git , независимо от того, почему он там находится, делает этот файл отслеживаемым . Команда Git будет (при отсутствии предположения-без изменений или пропуска-рабочего дерева) жаловаться на файлы, которые находятся в индексе Git и вашем рабочем дереве и не совпадают. Неважно, перечислены ли эти файлы в a или нет: файлы отслеживаются, поэтому они будут в следующем коммите, поэтому Git будет жаловаться, если они не совпадают.
Что действительно делает список файлов , так это подавляет другую жалобу . Предположим, у вас есть какой-то файл в вашем рабочем дереве прямо сейчас. (Возможно, вы сделали это, вставив что-то, что хотели запомнить, в файл с намерением удалить его, как только позаботитесь о том, что это такое.) Далее предположим, что этого файла нет в индексе Git — он победил. не будет в вашем следующем коммите — и его не должно быть в вашем индексном коммите или любом другом коммите. Однако его присутствие в вашем рабочем дереве заставит жаловаться, что
Неотслеживаемый файл — это, по определению, любой файл, существующий в вашем рабочем дереве, но не в индексе Git. (Любой файл, который находится в индексе Git, является отслеживаемым файлом.) И жалуется на них, и вы не можете установить для них какие-либо флаги входа в индекс, потому что они специально не находятся в индексе Git . Так что должен быть способ перестать жаловаться — и это первая часть того, что делает запись.
Перечисление имени файла или шаблона в теллсе
Все это означает, что это неправильное имя файла. Так должно быть
Резюме: что вы узнали
- Git хранит коммиты . В них хранятся файлы и метаданные.
- Git находит коммиты по хеш-идентификатору, но люди этого не делают, поэтому Git сохраняет хэш-идентификаторы в именах: имя ветки содержит один хэш-идентификатор.
- Git находит коммиты, просматривая коммиты, которые указывают на более ранние коммиты. Это история, а также то, как работают ветки: имя ветки указывает на тот коммит, который мы хотим назвать последним коммитом.
- Git создает новые коммиты из всего, что находится в индексе Git, также известном как промежуточная область .
- Файлы, над которыми вы работаете, в вашем рабочем дереве не находятся в Git.
- Вы можете захотеть, чтобы некоторые файлы в вашем рабочем дереве никогда не попадали в коммит . Чтобы это произошло, не добавляйте их. Чтобы сделать это проще , используйте
- Команда перемещает имя текущей ветки, а затем, при необходимости, сбрасывает индекс и рабочее дерево.
- Перемещение имени ветки может привести к тому, что коммит станет недоступным для поиска (если вы не запомнили его хэш-идентификатор).
Последняя часть - это то, что делает
Одного добавления ваших файлов в .gitignore недостаточно.
Вы должны сделать это:
git update-index --assume-unchanged <file_path>
и добавьте свои файлы в
.gitignore
Если вы хотите сделать это с каталогом, откройте этот каталог в своей оболочке (используя cd):
и выполните это:
git update-index --assume-unchanged $(git ls-files | tr '\n' ' ')