R - Подход, чтобы найти выбросы / артефакты в кривой кровяного давления
Ребята, у вас есть идея, как подойти к проблеме обнаружения артефактов / выбросов на кривой кровяного давления? Моя цель - написать программу, которая определяет начало и конец каждого артефакта. Вот несколько примеров различных артефактов: зеленая область - это правильная кривая кровяного давления, а красная - это артефакт, который необходимо обнаружить:



И это пример всей кривой кровяного давления: 
Моя первая идея состояла в том, чтобы вычислить среднее значение для всей кривой и множества средних значений на коротких интервалах кривой, а затем выяснить, где оно отличается. Но кровяное давление меняется настолько сильно, что я не думаю, что это может сработать, потому что он найдет слишком много несуществующих "артефактов".
Спасибо за ваш вклад!
РЕДАКТИРОВАТЬ: Вот некоторые данные для двух примеров артефактов:
2 ответа
Без каких-либо данных есть только возможность указать вам различные методы.
Во-первых (не зная ваших данных, что всегда является огромным недостатком), я бы указал вам на модели переключения Маркова, которые можно проанализировать с помощью HiddenMarkov -package или HMM -package. (К сожалению RHmm -пакет, описанный в первой ссылке, больше не поддерживается)
Вы можете найти, что стоит посмотреть на обнаружение выбросов в Twitter.
Кроме того, есть много блогов, которые изучают обнаружение точек изменения или изменения режима. Я считаю этот пост R-bloggers очень полезным для начала. Это относится к CPM -пакет, который обозначает "Обнаружение последовательных и пакетных изменений с использованием параметрических и непараметрических методов", BCP -пакет ("Байесовский анализ проблем точек изменения") и ECP -package ("Непараметрический множественный анализ точек изменения многомерных данных"). Возможно, вы захотите взглянуть на первые два, так как у вас нет многомерных данных.
Это поможет вам начать?
Я мог бы предоставить графический ответ, который не использует какой-либо статистический алгоритм. Из ваших данных я замечаю, что "ненормальные" последовательности, по-видимому, представляют собой постоянные части или, наоборот, очень большие вариации. Работа над производной и установка ограничений на эту производную могут работать. Вот обходной путь:
require(forecast)
test=c(df2$BP)
test=ma(test, order=50)
test=test[complete.cases(test)]
which <- ma(0+abs(diff(test))>1, order=10)>0.1
abnormal=test; abnormal[!which]<-NA
plot(x=1:NROW(test), y=test, type='l')
lines(x=1:NROW(test), y=abnormal, col='red')
Что он делает: сначала "сглаживает" данные с помощью скользящего среднего, чтобы предотвратить обнаружение микроверсий. Затем он применяет функцию "diff" (производная) и проверяет, не превышает ли она значение 1 (это значение необходимо настраивать вручную в зависимости от амплитуды успокоения). Затем, чтобы получить целый "блок" ненормальной последовательности без крошечных пробелов, мы снова применяем сглаживание к булевому значению и проверяем его выше 0,1, чтобы лучше понять границы зоны. В конце концов, я выделил выделенные участки красным цветом.
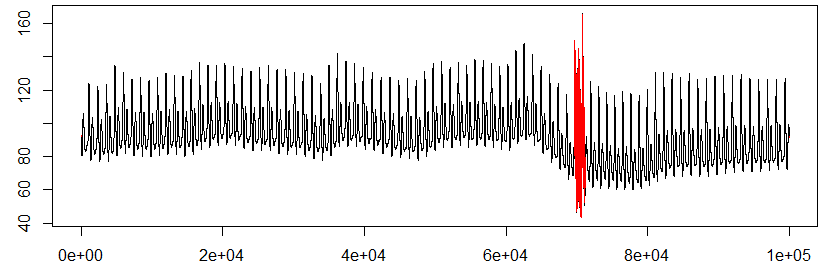
Это работает для одного типа аномалий. Для другого типа вы можете установить низкий порог для производной, наоборот, и поиграть с параметрами настройки сглаживания.