Python - список словарей, записываемый в CSV как строку, а не список - позже не может анализироваться в пандах
for k,v in groupDict_sanitized.items():
if discovered_hosts_groupid in v:
csvdata = (k,v)
print(k,v)
print(type(v))
#Example from print output
#20099 ['5']
#<class 'list'>
#20100 ['5']
#<class 'list'>
#20105 ['5']
#<class 'list'>
#20114 ['5']
#<class 'list'>
write_discovered_hosts_raw_csv.writerows([csvdata])
if offboarded_groupid in v:
#v = list(v)
csvdata = (k,v)
print(k,v)
print(type(v))
#Example from print output:
#19621 ['192', '359']
#<class 'list'>
#19636 ['19', '23', '56', '192']
#<class 'list'>
#19657 ['19', '21', '64', '192', '408']
#<class 'list'>
#19667 ['192']
write_offboarded_hosts_raw_csv.writerows([csvdata])
Вывод Discovered_host CSV, показанный на фотографии, не имеет «» вокруг списка (хотя только одна запись списка) является class . При записи csvdata - отображается в виде списка без кавычек:

CSV отображается в файле offboarded_hosts, кавычки в строке для нескольких записей, но не для отдельных элементов списка:
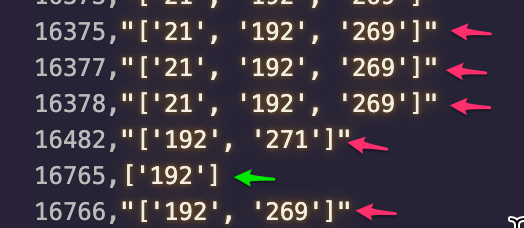
Проблема здесь в том, что при повторном чтении этого позже в другом коде он отображается как пустой фрейм данных из-за записи «[список]», где CSV без кавычек читается как правильный фрейм данных.
Есть ли правило, которое мне не хватает в списке CSV, чтобы поместить его как список без кавычек, но сохранить желаемый формат?
1 ответ
Предложение: можно ли оценить каждую строку, и если ее длина <2, вы строите из нее список?