Вложенный ввод json Pinot
У меня есть эта схема json
{
"name":"Pete"
"age":24,
"subjects":[
{
"name":"maths"
"grade":"A"
},
{
"name":"maths"
"grade":"B"
}
]
}
и я хочу поместить это в таблицу пино, чтобы выполнить запрос, например
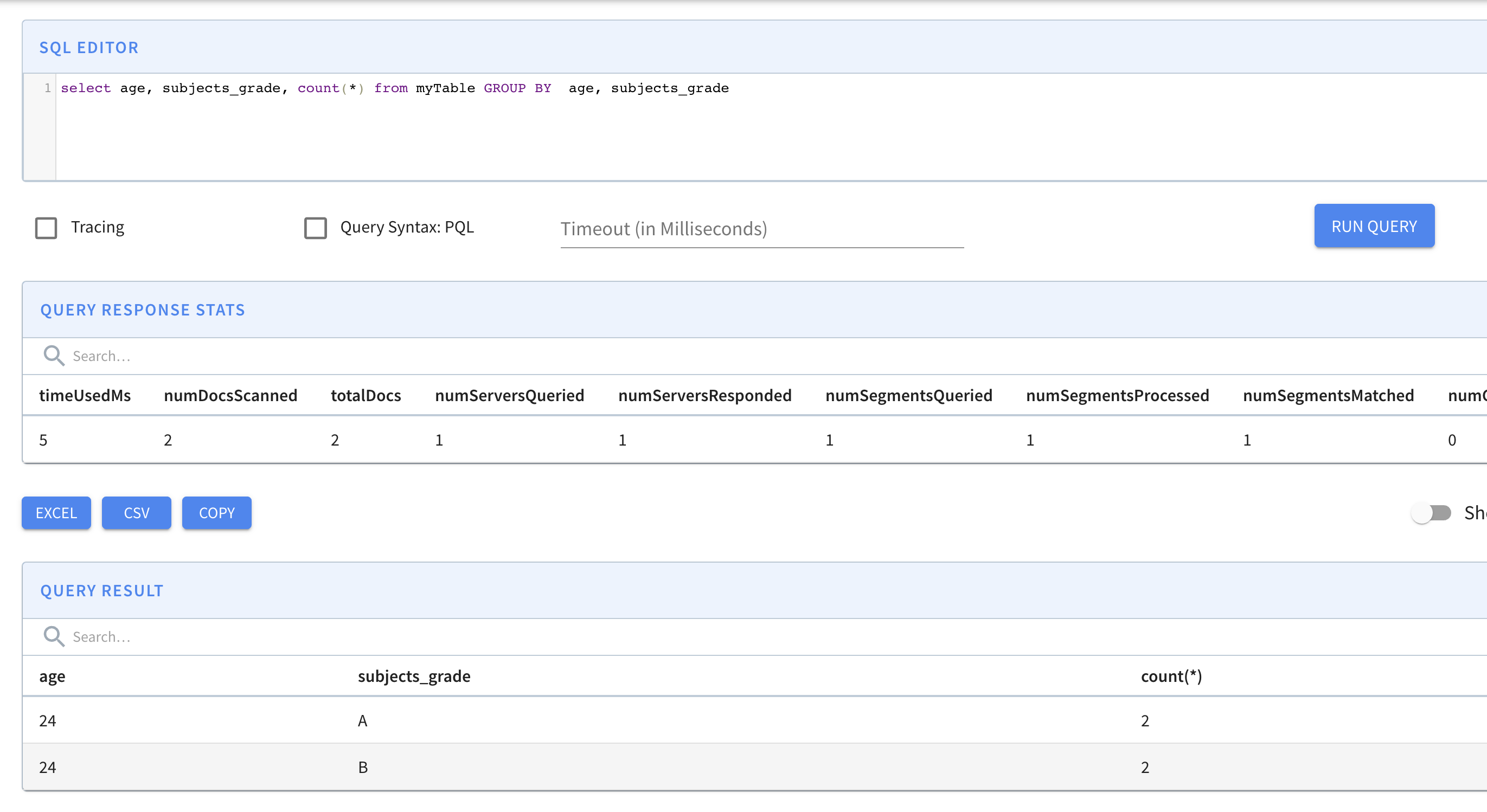
select age,subjects_grade,count(*) from table group by age,subjects_grade
Есть ли способ сделать это в пино?
1 ответ
У Pinot есть два способа обработки записей JSON:
1. Выравнивание записи во время загрузки . В этом случае мы рассматриваем каждое вложенное поле как отдельное поле, поэтому необходимо:
- Определите эти поля в схеме таблицы
- Определите функции преобразования для выравнивания вложенных полей в конфигурации таблицы.
Пожалуйста, посмотрите, как колонка
subjects_nameа также
subjects_gradeопределяется ниже. Так как это массив, то оба поля являются многозначными столбцами в Pinot.
2. Непосредственно загружайте записи JSON
В этом случае мы рассматриваем каждое вложенное поле как одно поле, поэтому необходимо:
- Определите поле JSON в схеме таблицы как строку со значением maxLength.
- Поместите это поле в noDictionaryColumns и jsonIndexColumns в конфигурации таблицы .
- Определение функций преобразования
jsonFormatчтобы упорядочить поле JSON в конфигурации таблицы
Пожалуйста, посмотрите, как колонка
subjects_strопределяется ниже.
Ниже приведен пример схемы/конфигурации/запроса таблицы:
Пример схемы Пино:
{
"metricFieldSpecs": [],
"dimensionFieldSpecs": [
{
"dataType": "STRING",
"name": "name"
},
{
"dataType": "LONG",
"name": "age"
},
{
"dataType": "STRING",
"name": "subjects_str"
},
{
"dataType": "STRING",
"name": "subjects_name",
"singleValueField": false
},
{
"dataType": "STRING",
"name": "subjects_grade",
"singleValueField": false
}
],
"dateTimeFieldSpecs": [],
"schemaName": "myTable"
}
Пример конфигурации таблицы:
{
"tableName": "myTable",
"tableType": "OFFLINE",
"segmentsConfig": {
"segmentPushType": "APPEND",
"segmentAssignmentStrategy": "BalanceNumSegmentAssignmentStrategy",
"schemaName": "myTable",
"replication": "1"
},
"tenants": {},
"tableIndexConfig": {
"loadMode": "MMAP",
"invertedIndexColumns": [],
"noDictionaryColumns": [
"subjects_str"
],
"jsonIndexColumns": [
"subjects_str"
]
},
"metadata": {
"customConfigs": {}
},
"ingestionConfig": {
"batchIngestionConfig": {
"segmentIngestionType": "APPEND",
"segmentIngestionFrequency": "DAILY",
"batchConfigMaps": [],
"segmentNameSpec": {},
"pushSpec": {}
},
"transformConfigs": [
{
"columnName": "subjects_str",
"transformFunction": "jsonFormat(subjects)"
},
{
"columnName": "subjects_name",
"transformFunction": "jsonPathArray(subjects, '$.[*].name')"
},
{
"columnName": "subjects_grade",
"transformFunction": "jsonPathArray(subjects, '$.[*].grade')"
}
]
}
}
Пример запроса:
select age, subjects_grade, count(*) from myTable GROUP BY age, subjects_grade
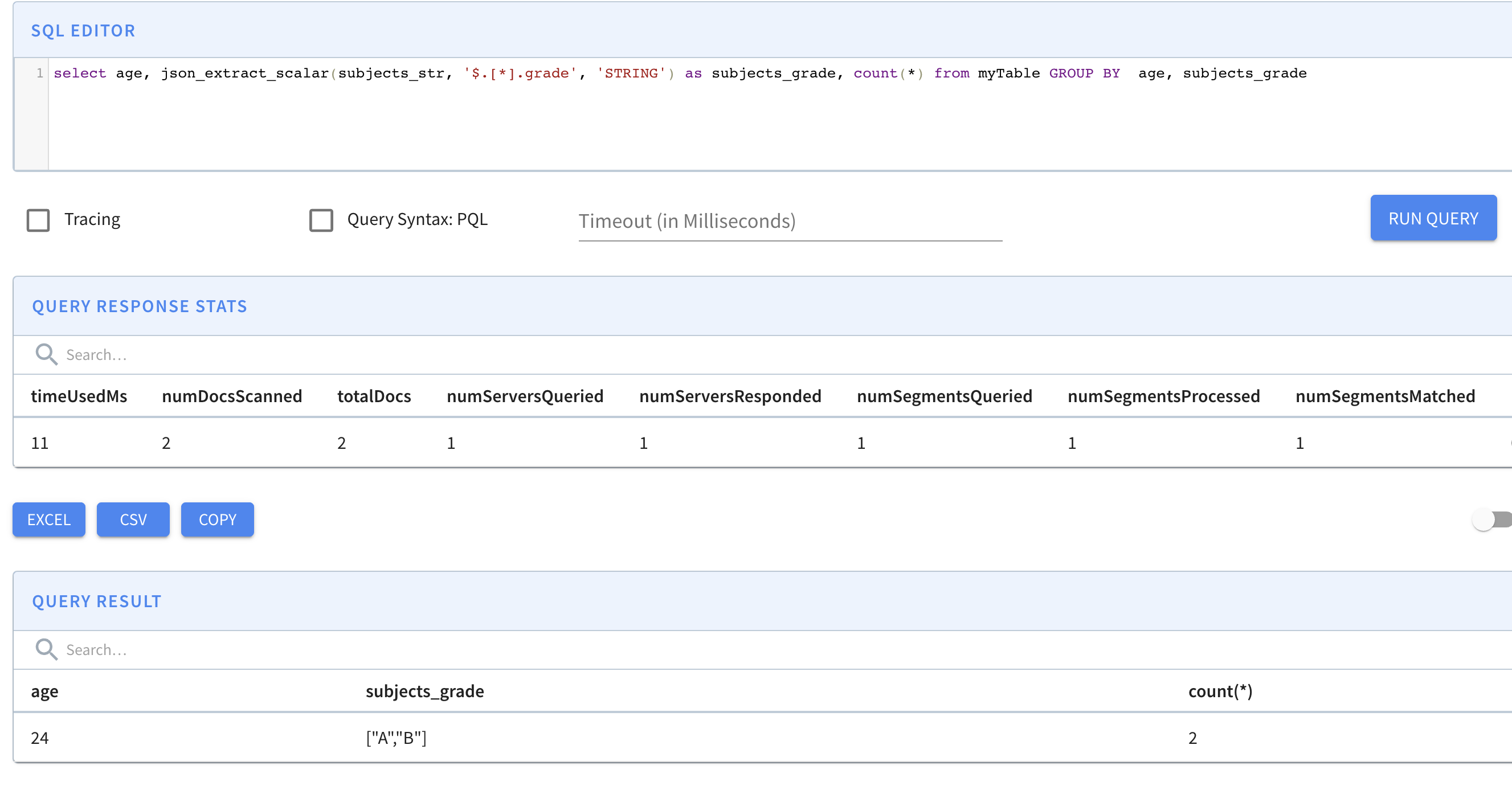
select age, json_extract_scalar(subjects_str, '$.[*].grade', 'STRING') as subjects_grade, count(*) from myTable GROUP BY age, subjects_grade
Сравнивая оба способа, мы рекомендуем решение 1 для выравнивания вложенных полей, когда плотность полей высока (например, каждый документ имеет имя поля и класс , тогда стоит извлечь их в новые столбцы), это обеспечивает лучшую производительность запросов и лучшее хранилище. эффективность.
Решение 2 проще в конфигурации и подходит для разреженных полей (например, только несколько документов имеют определенные поля). Для доступа к вложенному полю требуется использовать функцию json_extract_scalar .
Также обратите внимание на поведение Pinot GROUP BY в столбцах с несколькими значениями.
Больше ссылок: