Выберите строки в DataFrame на основе значений в столбце в пандах
Как выбрать строки из DataFrame на основе значений в некотором столбце в пандах?
В SQL я бы использовал:
select * from table where colume_name = some_value.
Я попытался просмотреть документацию панд, но не сразу нашел ответ.
22 ответа
Чтобы выбрать строки, чье значение столбца равно скаляру, some_valueиспользовать ==:
df.loc[df['column_name'] == some_value]
Чтобы выбрать строки, чье значение столбца является итеративным, some_valuesиспользовать isin:
df.loc[df['column_name'].isin(some_values)]
Объединить несколько условий с &:
df.loc[(df['column_name'] == some_value) & df['other_column'].isin(some_values)]
Чтобы выбрать строки, чье значение столбца не равно some_valueиспользовать !=:
df.loc[df['column_name'] != some_value]
isin возвращает логическое значение Series, поэтому для выбора строк, значение которых отсутствует some_values, отрицание логического ряда, используя ~:
df.loc[~df['column_name'].isin(some_values)]
Например,
import pandas as pd
import numpy as np
df = pd.DataFrame({'A': 'foo bar foo bar foo bar foo foo'.split(),
'B': 'one one two three two two one three'.split(),
'C': np.arange(8), 'D': np.arange(8) * 2})
print(df)
# A B C D
# 0 foo one 0 0
# 1 bar one 1 2
# 2 foo two 2 4
# 3 bar three 3 6
# 4 foo two 4 8
# 5 bar two 5 10
# 6 foo one 6 12
# 7 foo three 7 14
print(df.loc[df['A'] == 'foo'])
доходность
A B C D
0 foo one 0 0
2 foo two 2 4
4 foo two 4 8
6 foo one 6 12
7 foo three 7 14
Если у вас есть несколько значений, которые вы хотите включить, поместите их в список (или, в более общем случае, любой итеративный) и используйте isin:
print(df.loc[df['B'].isin(['one','three'])])
доходность
A B C D
0 foo one 0 0
1 bar one 1 2
3 bar three 3 6
6 foo one 6 12
7 foo three 7 14
Обратите внимание, однако, что если вы хотите сделать это много раз, более эффективно сначала создать индекс, а затем использовать df.loc:
df = df.set_index(['B'])
print(df.loc['one'])
доходность
A C D
B
one foo 0 0
one bar 1 2
one foo 6 12
или, чтобы включить несколько значений из индекса использования df.index.isin:
df.loc[df.index.isin(['one','two'])]
доходность
A C D
B
one foo 0 0
one bar 1 2
two foo 2 4
two foo 4 8
two bar 5 10
one foo 6 12
Существует несколько основных способов выбора строк в кадре данных Pandas.
- Логическое индексирование
- Позиционная индексация
- Индексирование меток
- API
Для каждого базового типа мы можем упростить ситуацию, ограничившись API-интерфейсом pandas, или мы можем выйти за пределы API, обычно в numpyи ускорить процесс.
Я покажу вам примеры каждого из них и покажу вам, когда следует использовать определенные методы.
Настроить
Первое, что нам нужно, это определить условие, которое будет служить нашим критерием для выбора строк. ОП предлагает column_name == some_value, Мы начнем там и включим некоторые другие общие случаи использования.
Заимствование у @unutbu:
import pandas as pd, numpy as np
df = pd.DataFrame({'A': 'foo bar foo bar foo bar foo foo'.split(),
'B': 'one one two three two two one three'.split(),
'C': np.arange(8), 'D': np.arange(8) * 2})
Предположим, что наш критерий является столбцом 'A' знак равно 'foo'
1.
Булева индексация требует найти значение истинности каждой строки 'A' столбец равен 'foo'затем с помощью этих значений истинности определить, какие строки сохранить. Как правило, мы называем эту серию массивом значений истинности, mask, Мы сделаем это и здесь.
mask = df['A'] == 'foo'
Затем мы можем использовать эту маску для нарезки или индексации кадра данных
df[mask]
A B C D
0 foo one 0 0
2 foo two 2 4
4 foo two 4 8
6 foo one 6 12
7 foo three 7 14
Это один из самых простых способов выполнить эту задачу, и если производительность или интуитивность не являются проблемой, это должен быть выбранный вами метод. Однако, если производительность является проблемой, то вы можете рассмотреть альтернативный способ создания mask,
2.
Позиционная индексация имеет свои варианты использования, но это не один из них. Чтобы определить, где нарезать, нам сначала нужно выполнить тот же логический анализ, который мы сделали выше. Это заставляет нас выполнить еще один шаг для выполнения той же задачи.
mask = df['A'] == 'foo'
pos = np.flatnonzero(mask)
df.iloc[pos]
A B C D
0 foo one 0 0
2 foo two 2 4
4 foo two 4 8
6 foo one 6 12
7 foo three 7 14
3.
Индексирование меток может быть очень удобным, но в этом случае мы снова делаем больше работы без пользы
df.set_index('A', append=True, drop=False).xs('foo', level=1)
A B C D
0 foo one 0 0
2 foo two 2 4
4 foo two 4 8
6 foo one 6 12
7 foo three 7 14
4.pd.DataFrame.queryэто очень элегантный / интуитивно понятный способ выполнить эту задачу. Но часто медленнее.Однако, если вы обратите внимание на временные параметры, приведенные ниже, для больших данных запрос очень эффективен. Больше, чем стандартный подход и такой же величины, как мое лучшее предложение.
df.query('A == "foo"')
A B C D
0 foo one 0 0
2 foo two 2 4
4 foo two 4 8
6 foo one 6 12
7 foo three 7 14
Я предпочитаю использоватьBooleanmask
Фактические улучшения могут быть сделаны путем изменения того, как мы создаем нашиBooleanmask,
maskальтернатива 1
Используйте базовыйnumpyмассив и отказаться от накладных расходов на создание другогоpd.Series
mask = df['A'].values == 'foo'
В конце я покажу более полные временные тесты, но просто взглянем на прирост производительности, который мы получаем, используя примерный фрейм данных. Сначала мы посмотрим на разницу в создании mask
%timeit mask = df['A'].values == 'foo'
%timeit mask = df['A'] == 'foo'
5.84 µs ± 195 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
166 µs ± 4.45 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
Оценка mask с numpy массив в ~ 30 раз быстрее Это отчасти связано с numpy оценка часто быстрая. Это также отчасти связано с отсутствием накладных расходов, необходимых для построения индекса и соответствующего pd.Series объект.
Далее мы рассмотрим сроки нарезки с одним mask по сравнению с другими.
mask = df['A'].values == 'foo'
%timeit df[mask]
mask = df['A'] == 'foo'
%timeit df[mask]
219 µs ± 12.3 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
239 µs ± 7.03 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Прирост производительности не так выражен. Посмотрим, выдержит ли это более надежное тестирование.
maskальтернатива 2
Мы могли бы также реконструировать фрейм данных. При восстановлении кадра данных возникает большая проблема: вы должны позаботиться о dtypes при этом!
Вместо df[mask] мы сделаем это
pd.DataFrame(df.values[mask], df.index[mask], df.columns).astype(df.dtypes)
Если датафрейм имеет смешанный тип, как в нашем примере, то когда мы получим df.values результирующий массив имеет dtypeobject и, следовательно, все столбцы нового фрейма данных будут иметь dtypeobject, Таким образом, требуя astype(df.dtypes) и убить любой потенциальный прирост производительности.
%timeit df[m]
%timeit pd.DataFrame(df.values[mask], df.index[mask], df.columns).astype(df.dtypes)
216 µs ± 10.4 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
1.43 ms ± 39.6 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Однако, если фрейм данных не имеет смешанного типа, это очень полезный способ сделать это.
Дано
np.random.seed([3,1415])
d1 = pd.DataFrame(np.random.randint(10, size=(10, 5)), columns=list('ABCDE'))
d1
A B C D E
0 0 2 7 3 8
1 7 0 6 8 6
2 0 2 0 4 9
3 7 3 2 4 3
4 3 6 7 7 4
5 5 3 7 5 9
6 8 7 6 4 7
7 6 2 6 6 5
8 2 8 7 5 8
9 4 7 6 1 5
%%timeit
mask = d1['A'].values == 7
d1[mask]
179 µs ± 8.73 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
Против
%%timeit
mask = d1['A'].values == 7
pd.DataFrame(d1.values[mask], d1.index[mask], d1.columns)
87 µs ± 5.12 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
Мы сократили время пополам.
maskальтернатива 3
@unutbu также показывает нам, как использовать pd.Series.isin для учета каждого элемента df['A'] находясь в наборе значений. Это оценивает то же самое, если наш набор значений является набором одного значения, а именно 'foo', Но это также обобщает включение больших наборов значений, если это необходимо. Оказывается, это все еще довольно быстро, хотя это более общее решение. Единственная реальная потеря заключается в интуитивности для тех, кто не знаком с концепцией.
mask = df['A'].isin(['foo'])
df[mask]
A B C D
0 foo one 0 0
2 foo two 2 4
4 foo two 4 8
6 foo one 6 12
7 foo three 7 14
Однако, как и прежде, мы можем использовать numpy улучшить производительность, жертвуя при этом практически ничем. Мы будем использовать np.in1d
mask = np.in1d(df['A'].values, ['foo'])
df[mask]
A B C D
0 foo one 0 0
2 foo two 2 4
4 foo two 4 8
6 foo one 6 12
7 foo three 7 14
тайминг
Я включу другие концепции, упомянутые в других постах, а также для справки.
Код ниже
Каждый столбец в этой таблице представляет собой фрейм данных различной длины, на котором мы тестируем каждую функцию. Каждый столбец показывает относительное время, с самой быстрой функцией, учитывая базовый индекс 1.0,
res.div(res.min())
10 30 100 300 1000 3000 10000 30000
mask_standard 2.156872 1.850663 2.034149 2.166312 2.164541 3.090372 2.981326 3.131151
mask_standard_loc 1.879035 1.782366 1.988823 2.338112 2.361391 3.036131 2.998112 2.990103
mask_with_values 1.010166 1.000000 1.005113 1.026363 1.028698 1.293741 1.007824 1.016919
mask_with_values_loc 1.196843 1.300228 1.000000 1.000000 1.038989 1.219233 1.037020 1.000000
query 4.997304 4.765554 5.934096 4.500559 2.997924 2.397013 1.680447 1.398190
xs_label 4.124597 4.272363 5.596152 4.295331 4.676591 5.710680 6.032809 8.950255
mask_with_isin 1.674055 1.679935 1.847972 1.724183 1.345111 1.405231 1.253554 1.264760
mask_with_in1d 1.000000 1.083807 1.220493 1.101929 1.000000 1.000000 1.000000 1.144175
Вы заметите, что самые быстрые времена, кажется, делятся между mask_with_values а также mask_with_in1d
res.T.plot(loglog=True)
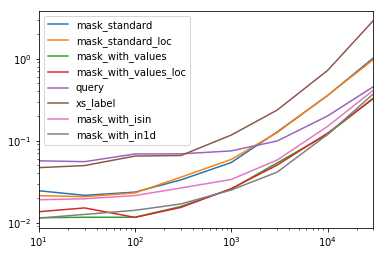
функции
def mask_standard(df):
mask = df['A'] == 'foo'
return df[mask]
def mask_standard_loc(df):
mask = df['A'] == 'foo'
return df.loc[mask]
def mask_with_values(df):
mask = df['A'].values == 'foo'
return df[mask]
def mask_with_values_loc(df):
mask = df['A'].values == 'foo'
return df.loc[mask]
def query(df):
return df.query('A == "foo"')
def xs_label(df):
return df.set_index('A', append=True, drop=False).xs('foo', level=-1)
def mask_with_isin(df):
mask = df['A'].isin(['foo'])
return df[mask]
def mask_with_in1d(df):
mask = np.in1d(df['A'].values, ['foo'])
return df[mask]
тестирование
res = pd.DataFrame(
index=[
'mask_standard', 'mask_standard_loc', 'mask_with_values', 'mask_with_values_loc',
'query', 'xs_label', 'mask_with_isin', 'mask_with_in1d'
],
columns=[10, 30, 100, 300, 1000, 3000, 10000, 30000],
dtype=float
)
for j in res.columns:
d = pd.concat([df] * j, ignore_index=True)
for i in res.index:a
stmt = '{}(d)'.format(i)
setp = 'from __main__ import d, {}'.format(i)
res.at[i, j] = timeit(stmt, setp, number=50)
Специальное время
Глядя на особый случай, когда у нас есть один не объект dtype для всего кадра данных.Код ниже
spec.div(spec.min())
10 30 100 300 1000 3000 10000 30000
mask_with_values 1.009030 1.000000 1.194276 1.000000 1.236892 1.095343 1.000000 1.000000
mask_with_in1d 1.104638 1.094524 1.156930 1.072094 1.000000 1.000000 1.040043 1.027100
reconstruct 1.000000 1.142838 1.000000 1.355440 1.650270 2.222181 2.294913 3.406735
Оказывается, реконструкция не стоит нескольких сотен рядов.
spec.T.plot(loglog=True)
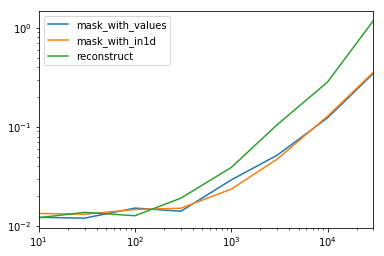
функции
np.random.seed([3,1415])
d1 = pd.DataFrame(np.random.randint(10, size=(10, 5)), columns=list('ABCDE'))
def mask_with_values(df):
mask = df['A'].values == 'foo'
return df[mask]
def mask_with_in1d(df):
mask = np.in1d(df['A'].values, ['foo'])
return df[mask]
def reconstruct(df):
v = df.values
mask = np.in1d(df['A'].values, ['foo'])
return pd.DataFrame(v[mask], df.index[mask], df.columns)
spec = pd.DataFrame(
index=['mask_with_values', 'mask_with_in1d', 'reconstruct'],
columns=[10, 30, 100, 300, 1000, 3000, 10000, 30000],
dtype=float
)
тестирование
for j in spec.columns:
d = pd.concat([df] * j, ignore_index=True)
for i in spec.index:
stmt = '{}(d)'.format(i)
setp = 'from __main__ import d, {}'.format(i)
spec.at[i, j] = timeit(stmt, setp, number=50)
ТЛ; др
Панды, эквивалентные
select * from table where column_name = some_value
является
table[table.column_name == some_value]
Несколько условий:
table[(table.column_name == some_value) | (table.column_name2 == some_value2)]
или же
table.query('column_name == some_value | column_name2 == some_value2')
Пример кода
import pandas as pd
# Create data set
d = {'foo':[100, 111, 222],
'bar':[333, 444, 555]}
df = pd.DataFrame(d)
# Full dataframe:
df
# Shows:
# bar foo
# 0 333 100
# 1 444 111
# 2 555 222
# Output only the row(s) in df where foo is 222:
df[df.foo == 222]
# Shows:
# bar foo
# 2 555 222
В приведенном выше коде это строка df[df.foo == 222] что дает строки на основе значения столбца, 222 в этом случае.
Возможны также несколько условий:
df[(df.foo == 222) | (df.bar == 444)]
# bar foo
# 1 444 111
# 2 555 222
Но в этот момент я бы порекомендовал использовать функцию запроса, так как она менее многословна и дает тот же результат:
df.query('foo == 222 | bar == 444')
Я нахожу синтаксис предыдущих ответов излишним и трудным для запоминания. Панды представили query() метод в v0.13 и я предпочитаю это. По вашему вопросу вы могли бы сделать df.query('col == val')
Воспроизводится с http://pandas.pydata.org/pandas-docs/version/0.17.0/indexing.html
In [167]: n = 10
In [168]: df = pd.DataFrame(np.random.rand(n, 3), columns=list('abc'))
In [169]: df
Out[169]:
a b c
0 0.687704 0.582314 0.281645
1 0.250846 0.610021 0.420121
2 0.624328 0.401816 0.932146
3 0.011763 0.022921 0.244186
4 0.590198 0.325680 0.890392
5 0.598892 0.296424 0.007312
6 0.634625 0.803069 0.123872
7 0.924168 0.325076 0.303746
8 0.116822 0.364564 0.454607
9 0.986142 0.751953 0.561512
# pure python
In [170]: df[(df.a < df.b) & (df.b < df.c)]
Out[170]:
a b c
3 0.011763 0.022921 0.244186
8 0.116822 0.364564 0.454607
# query
In [171]: df.query('(a < b) & (b < c)')
Out[171]:
a b c
3 0.011763 0.022921 0.244186
8 0.116822 0.364564 0.454607
Вы также можете получить доступ к переменным в среде, добавив @,
exclude = ('red', 'orange')
df.query('color not in @exclude')
Больше гибкости при использовании .query с участием pandas >= 0.25.0:
Обновленный ответ за август 2019 г.
поскольку pandas >= 0.25.0 мы можем использовать queryдля фильтрации фреймов данных с помощью методов pandas и даже имен столбцов, в которых есть пробелы. Обычно пробелы в именах столбцов выдают ошибку, но теперь мы можем решить эту проблему с помощью обратной кавычки (`), см. GitHub:
# Example dataframe
df = pd.DataFrame({'Sender email':['ex@example.com', "reply@shop.com", "buy@shop.com"]})
Sender email
0 ex@example.com
1 reply@shop.com
2 buy@shop.com
С помощью .query с методом str.endswith:
df.query('`Sender email`.str.endswith("@shop.com")')
Выход
Sender email
1 reply@shop.com
2 buy@shop.com
Также мы можем использовать локальные переменные, добавив к ним префикс @ в нашем запросе:
domain = 'shop.com'
df.query('`Sender email`.str.endswith(@domain)')
Выход
Sender email
1 reply@shop.com
2 buy@shop.com
Для выбора только определенных столбцов из нескольких столбцов для данного значения в пандах:
select col_name1, col_name2 from table where column_name = some_value.
Опции:
df.loc[df['column_name'] == some_value][[col_name1, col_name2]]
или же
df.query['column_name' == 'some_value'][[col_name1, col_name2]]
В более новых версиях Pandas, вдохновленных документацией ( Просмотр данных):
df[df["colume_name"] == some_value] #Scalar, True/False..
df[df["colume_name"] == "some_value"] #String
Объедините несколько условий, заключив предложение в круглые скобки,
(), и комбинируя их с
& и
|(и / или). Как это:
df[(df["colume_name"] == "some_value1") & (pd[pd["colume_name"] == "some_value2"])]
Другие фильтры
pandas.notna(df["colume_name"]) == True # Not NaN
df['colume_name'].str.contains("text") # Search for "text"
df['colume_name'].str.lower().str.contains("text") # Search for "text", after converting to lowercase
Более быстрых результатов можно достичь, используя numpy.where.
Например, с настройкой unubtu -
In [76]: df.iloc[np.where(df.A.values=='foo')]
Out[76]:
A B C D
0 foo one 0 0
2 foo two 2 4
4 foo two 4 8
6 foo one 6 12
7 foo three 7 14
Сроки сравнения:
In [68]: %timeit df.iloc[np.where(df.A.values=='foo')] # fastest
1000 loops, best of 3: 380 µs per loop
In [69]: %timeit df.loc[df['A'] == 'foo']
1000 loops, best of 3: 745 µs per loop
In [71]: %timeit df.loc[df['A'].isin(['foo'])]
1000 loops, best of 3: 562 µs per loop
In [72]: %timeit df[df.A=='foo']
1000 loops, best of 3: 796 µs per loop
In [74]: %timeit df.query('(A=="foo")') # slowest
1000 loops, best of 3: 1.71 ms per loop
Вот простой пример
from pandas import DataFrame
# Create data set
d = {'Revenue':[100,111,222],
'Cost':[333,444,555]}
df = DataFrame(d)
# mask = Return True when the value in column "Revenue" is equal to 111
mask = df['Revenue'] == 111
print mask
# Result:
# 0 False
# 1 True
# 2 False
# Name: Revenue, dtype: bool
# Select * FROM df WHERE Revenue = 111
df[mask]
# Result:
# Cost Revenue
# 1 444 111
Чтобы добавить к этому знаменитому вопросу (хотя и слишком поздно): Вы также можете сделать df.groupby('column_name').get_group('column_desired_value').reset_index() создать новый фрейм данных с указанным столбцом, имеющим определенное значение. Например
import pandas as pd
df = pd.DataFrame({'A': 'foo bar foo bar foo bar foo foo'.split(),
'B': 'one one two three two two one three'.split()})
print("Original dataframe:")
print(df)
b_is_two_dataframe = pd.DataFrame(df.groupby('B').get_group('two').reset_index()).drop('index', axis = 1)
#NOTE: the final drop is to remove the extra index column returned by groupby object
print('Sub dataframe where B is two:')
print(b_is_two_dataframe)
Выполнить это дает:
Original dataframe:
A B
0 foo one
1 bar one
2 foo two
3 bar three
4 foo two
5 bar two
6 foo one
7 foo three
Sub dataframe where B is two:
A B
0 foo two
1 foo two
2 bar two
1. Используйте f-строки внутри вызовов
Если имя столбца, используемое для фильтрации вашего фрейма данных, исходит из локальной переменной, могут быть полезны f-строки. Например,
col = 'A'
df.query(f"{col} == 'foo'")
На самом деле f-строки можно использовать и для переменной запроса (кроме datetime):
col = 'A'
my_var = 'foo'
df.query(f"{col} == '{my_var}'") # if my_var is a string
my_num = 1
df.query(f"{col} == {my_num}") # if my_var is a number
my_date = '2022-12-10'
df.query(f"{col} == @my_date") # must use @ for datetime though
2. Установите для ускорения звонков
В документации pandas рекомендуется установить numexpr для ускорения числовых вычислений при использовании . Использоватьpip install numexpr(илиconda,sudoи т. д. в зависимости от вашей среды), чтобы установить его.
Для больших фреймов данных (где производительность действительно имеет значение) сnumexprдвигатель работает намного быстрее, чем . В частности, он лучше работает в следующих случаях.
Логические операторы и/или операторы сравнения в столбцах строк
Если столбец строк сравнивается с некоторыми другими строками и должны быть выбраны совпадающие строки, даже для одной операции сравнения выполняется быстрее, чем . Например, для фрейма данных с 80 тыс. строк это на 30% быстрее 1 , а для фрейма данных с 800 тыс. строк — на 60% быстрее.2
df[df.A == 'foo']
df.query("A == 'foo'") # <--- performs 30%-60% faster
Этот разрыв увеличивается по мере увеличения количества операций (если 4 сравнения соединены в цепочкуdf.query()в 2-2,3 раза быстрее, чемdf[mask]) 1,2 и/или увеличивается длина кадра данных. 2
Несколько операций над числовыми столбцами
Если необходимо вычислить несколько арифметических, логических операций или операций сравнения, чтобы создать логическую маску для фильтрацииdf, работает быстрее. Например, для кадра с 80 тыс. строк это на 20% быстрее 1 , а для кадра с 800 тыс. строк — в 2 раза быстрее.2
df[(df.B % 5) **2 < 0.1]
df.query("(B % 5) **2 < 0.1") # <--- performs 20%-100% faster.
Этот разрыв в производительности увеличивается по мере увеличения количества операций и/или увеличения длины кадра данных. 2
На следующем графике показано, как методы работают по мере увеличения длины кадра данных.3
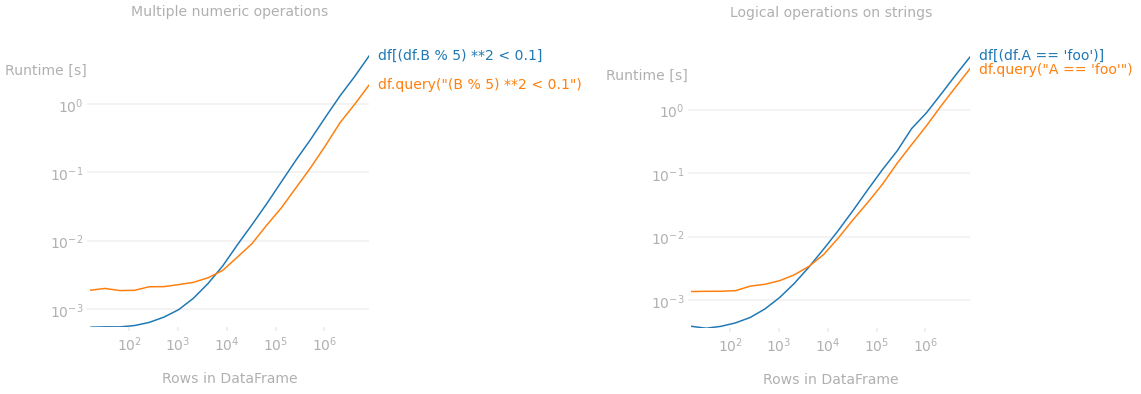
3. Вызовите методы pandas внутриquery()
Numexpr в настоящее время поддерживает только логические (&,|,~), сравнение (==,>,<,>=,<=,!=) и основные арифметические операторы (+,-,*,/,**,%).
Например, он не поддерживает целочисленное деление (//). Однако вызов эквивалентного метода pandas (floordiv()) работает.
df.query('B.floordiv(2) <= 3') # or
df.query('B.floordiv(2).le(3)')
# for pandas < 1.4, need `.values`
df.query('B.floordiv(2).values <= 3')
1 Тестовый код с использованием фрейма с 80 тыс. строк
import numpy as np
df = pd.DataFrame({'A': 'foo bar foo baz foo bar foo foo'.split()*10000,
'B': np.random.rand(80000)})
%timeit df[df.A == 'foo']
# 8.5 ms ± 104.5 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%timeit df.query("A == 'foo'")
# 6.36 ms ± 95.7 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%timeit df[((df.A == 'foo') & (df.A != 'bar')) | ((df.A != 'baz') & (df.A != 'buz'))]
# 29 ms ± 554 µs per loop (mean ± std. dev. of 10 runs, 100 loops each)
%timeit df.query("A == 'foo' & A != 'bar' | A != 'baz' & A != 'buz'")
# 16 ms ± 339 µs per loop (mean ± std. dev. of 10 runs, 100 loops each)
%timeit df[(df.B % 5) **2 < 0.1]
# 5.35 ms ± 37.6 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%timeit df.query("(B % 5) **2 < 0.1")
# 4.37 ms ± 46.3 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
2 Сравнительный код с использованием фрейма с 800 тыс. строк
df = pd.DataFrame({'A': 'foo bar foo baz foo bar foo foo'.split()*100000,
'B': np.random.rand(800000)})
%timeit df[df.A == 'foo']
# 87.9 ms ± 873 µs per loop (mean ± std. dev. of 10 runs, 100 loops each)
%timeit df.query("A == 'foo'")
# 54.4 ms ± 726 µs per loop (mean ± std. dev. of 10 runs, 100 loops each)
%timeit df[((df.A == 'foo') & (df.A != 'bar')) | ((df.A != 'baz') & (df.A != 'buz'))]
# 310 ms ± 3.4 ms per loop (mean ± std. dev. of 10 runs, 100 loops each)
%timeit df.query("A == 'foo' & A != 'bar' | A != 'baz' & A != 'buz'")
# 132 ms ± 2.43 ms per loop (mean ± std. dev. of 10 runs, 100 loops each)
%timeit df[(df.B % 5) **2 < 0.1]
# 54 ms ± 488 µs per loop (mean ± std. dev. of 10 runs, 100 loops each)
%timeit df.query("(B % 5) **2 < 0.1")
# 26.3 ms ± 320 µs per loop (mean ± std. dev. of 10 runs, 100 loops each)
3 : код, используемый для создания графиков производительности двух методов для строк и чисел.
from perfplot import plot
constructor = lambda n: pd.DataFrame({'A': 'foo bar foo baz foo bar foo foo'.split()*n, 'B': np.random.rand(8*n)})
plot(
setup=constructor,
kernels=[lambda df: df[(df.B%5)**2<0.1], lambda df: df.query("(B%5)**2<0.1")],
labels= ['df[(df.B % 5) **2 < 0.1]', 'df.query("(B % 5) **2 < 0.1")'],
n_range=[2**k for k in range(4, 24)],
xlabel='Rows in DataFrame',
title='Multiple mathematical operations on numbers',
equality_check=pd.DataFrame.equals);
plot(
setup=constructor,
kernels=[lambda df: df[df.A == 'foo'], lambda df: df.query("A == 'foo'")],
labels= ["df[df.A == 'foo']", """df.query("A == 'foo'")"""],
n_range=[2**k for k in range(4, 24)],
xlabel='Rows in DataFrame',
title='Comparison operation on strings',
equality_check=pd.DataFrame.equals);
Вы также можете использовать.apply:
df.apply(lambda row: row[df['B'].isin(['one','three'])])
Это на самом деле работает по строкам (то есть применяет функцию к каждой строке).
Выход
A B C D
0 foo one 0 0
1 bar one 1 2
3 bar three 3 6
6 foo one 6 12
7 foo three 7 14
Результаты такие же, как при использовании @unutbu
df[[df['B'].isin(['one','three'])]]
Я только что попытался отредактировать это, но я не вошел в систему, поэтому я не уверен, куда делось мое редактирование. Я пытался включить множественный выбор. Поэтому я думаю, что лучший ответ:
Для одного значения наиболее простым (понятным для человека), вероятно, является:
df.loc[df['column_name'] == some_value]
Для списков значений вы также можете использовать:
df.loc[df['column_name'].isin(some_values)]
Например,
import pandas as pd
import numpy as np
df = pd.DataFrame({'A': 'foo bar foo bar foo bar foo foo'.split(),
'B': 'one one two three two two one three'.split(),
'C': np.arange(8), 'D': np.arange(8) * 2})
print(df)
# A B C D
# 0 foo one 0 0
# 1 bar one 1 2
# 2 foo two 2 4
# 3 bar three 3 6
# 4 foo two 4 8
# 5 bar two 5 10
# 6 foo one 6 12
# 7 foo three 7 14
print(df.loc[df['A'] == 'foo'])
доходность
A B C D
0 foo one 0 0
2 foo two 2 4
4 foo two 4 8
6 foo one 6 12
7 foo three 7 14
Если у вас есть несколько критериев, по которым вы хотите выбрать, вы можете поместить их в список и использовать "isin":
print(df.loc[df['B'].isin(['one','three'])])
доходность
A B C D
0 foo one 0 0
1 bar one 1 2
3 bar three 3 6
6 foo one 6 12
7 foo three 7 14
Однако обратите внимание, что если вы хотите сделать это много раз, более эффективно сначала сделать индекс A, а затем использовать df.loc:
df = df.set_index(['A'])
print(df.loc['foo'])
доходность
A B C D
foo one 0 0
foo two 2 4
foo two 4 8
foo one 6 12
foo three 7 14
Если вы хотите повторно запрашивать свой фрейм данных и для вас важна скорость, лучше всего преобразовать ваш фрейм данных в словарь, и тогда, сделав это, вы сможете сделать запрос в тысячи раз быстрее.
my_df = df.set_index(column_name)
my_dict = my_df.to_dict('index')
После создания словаря my_dict вы можете пройти через:
if some_value in my_dict.keys():
my_result = my_dict[some_value]
Если у вас есть повторяющиеся значения в column_name, вы не можете создать словарь. но вы можете использовать:
my_result = my_df.loc[some_value]
Операторы SQL в DataFrames для выбора строк с использованием DuckDB
С помощью duckdb мы можем запрашивать кадры данных pandas с помощью операторов SQL высокопроизводительным способом .
Поскольку вопрос заключается в том, как выбрать строки из DataFrame на основе значений столбца? , а пример в вопросе - SQL-запрос, этот ответ выглядит логичным в данной теме.
Пример:
In [1]: import duckdb
In [2]: import pandas as pd
In [3]: con = duckdb.connect()
In [4]: df = pd.DataFrame({"A": range(11), "B": range(11, 22)})
In [5]: df
Out[5]:
A B
0 0 11
1 1 12
2 2 13
3 3 14
4 4 15
5 5 16
6 6 17
7 7 18
8 8 19
9 9 20
10 10 21
In [6]: results = con.execute("SELECT * FROM df where A > 2").df()
In [7]: results
Out[7]:
A B
0 3 14
1 4 15
2 5 16
3 6 17
4 7 18
5 8 19
6 9 20
7 10 21
Вы можете использоватьloc(квадратные скобки) с функцией:
# Series
s = pd.Series([1, 2, 3, 4])
s.loc[lambda x: x > 1]
# s[lambda x: x > 1]
Выход:
1 2
2 3
3 4
dtype: int64
или
# DataFrame
df = pd.DataFrame({'A': [1, 2, 3], 'B': [10, 20, 30]})
df[lambda x: (x['A'] != 1) & (x['B'] != 30)]
Выход:
A B
1 2 20
df = pd.DataFrame({'A': 'foo bar foo bar foo bar foo foo'.split(),
'B': 'one one two three two two one three'.split(),
'C': np.arange(8), 'D': np.arange(8) * 2})
df[df['A']=='foo']
OUTPUT:
A B C D
0 foo one 0 0
2 foo two 2 4
4 foo two 4 8
6 foo one 6 12
7 foo three 7 14
Если вы находите строки в столбце по целому числу, то
df.loc[df['column_name'] == 2017]
Если вы находите значение на основе строки
df.loc[df['column_name'] == 'string']
Если основано на обоих
df.loc[(df['column_name'] == 'string') & (df['column_name'] == 2017)]
Если вы пришли сюда, пытаясь выбрать строки из фрейма данных, включая те, чье значение столбца НЕ является ни одним из списка значений, вот как перевернуть ответ unutbu для списка значений выше:
df.loc[~df['column_name'].isin(some_values)]
(Конечно, чтобы не включать одно значение, вы просто используете обычный оператор not equals, !=.)
Пример:
import pandas as pd
df = pd.DataFrame({'A': 'foo bar foo bar foo bar foo foo'.split(),
'B': 'one one two three two two one three'.split()})
print(df)
дает нам
A B
0 foo one
1 bar one
2 foo two
3 bar three
4 foo two
5 bar two
6 foo one
7 foo three
Подмножество только тех строк, которые не one или же three в столбце B:
df.loc[~df['B'].isin(['one', 'three'])]
доходность
A B
2 foo two
4 foo two
5 bar two
Вот варианты использования встроенных функций pandas, похожих наisin.
df = pd.DataFrame({'cost': [250, 150, 100], 'revenue': [100, 250, 300]},index=['A', 'B', 'C'])
cost revenue
A 250 100
B 150 250
C 100 300
Сравните DataFrames на предмет равенства поэлементно
df[df["cost"].eq(250)]
cost revenue
A 250 100
Сравните DataFrames на предмет большего, чем неравенство или равенство поэлементно.
df[df["cost"].ge(100)]
cost revenue
A 250 100
B 150 250
C 100 300
Сравните DataFrames строго меньше, чем неравенство поэлементно.
df[df["cost"].lt(200)]
cost revenue
B 150 250
C 100 300
Отличные ответы. Только когда размер фрейма данных приближается к миллиону строк, многие методы, как правило, требуют времени при использовании.
df[df['col']==val]. Я хотел, чтобы все возможные значения «another_column» соответствовали определенным значениям в «some_column» (в данном случае в словаре). Это сработало и быстро.
s=datetime.datetime.now()
my_dict={}
for i, my_key in enumerate(df['some_column'].values):
if i%100==0:
print(i) # to see the progress
if my_key not in my_dict.keys():
my_dict[my_key]={}
my_dict[my_key]['values']=[df.iloc[i]['another_column']]
else:
my_dict[my_key]['values'].append(df.iloc[i]['another_column'])
e=datetime.datetime.now()
print('operation took '+str(e-s)+' seconds')```