Огромный пробел после заголовка в PDF с помощью Flying Saucer
Я пытаюсь экспортировать HTML-страницу в PDF с помощью Flying Saucer. По какой-то причине страницы имеют большой пробел после разделения заголовка (id = "divTemplateHeaderPage1"). Ссылка jsFiddle на мой HTML-код, который используется рендерером PDF: https://jsfiddle.net/Sparks245/uhxqdta6/.
Ниже приведен код Java, используемый для рендеринга PDF (Test.html - это тот же HTML-код в скрипте) и рендеринга только одной страницы.
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.json.HTTP;
import org.json.JSONException;
import org.json.*;
import org.json.simple.JSONArray;
import org.json.JSONObject;
import org.json.simple.parser.JSONParser;
import org.json.simple.parser.ParseException;
import org.json.simple.parser.*;
import org.xhtmlrenderer.pdf.ITextRenderer;
import com.lowagie.text.DocumentException;
import com.lowagie.text.List;
import com.sun.xml.internal.bind.v2.runtime.unmarshaller.XsiNilLoader.Array;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileOutputStream;
import java.io.FileReader;
import java.io.IOException;
import java.io.OutputStream;
@WebServlet("/PLPDFExport")
public class PLPDFExport extends HttpServlet
{
//Option for Serialization
private static final long serialVersionUID = 1L;
public PLPDFExport()
{
super();
}
//Get method
protected void doGet(HttpServletRequest request,
HttpServletResponse response)
throws ServletException,
IOException
{
}
//Post method
protected void doPost(HttpServletRequest request,
HttpServletResponse response)
throws ServletException,
IOException
{
StringBuffer jb = new StringBuffer();
String line = null;
int Pages;
String[] newArray = null;
try
{
BufferedReader reader = request.getReader();
while ((line = reader.readLine()) != null)
{ jb.append(line);
}
} catch (Exception e) { /*report an error*/ }
try
{
JSONObject obj = new JSONObject(jb.toString());
Pages = obj.getInt("Pages");
newArray = new String[1];
for(int cnt = 1; cnt <= 1; cnt++)
{
StringBuffer buf = new StringBuffer();
String base = "C:/Users/Sparks/Desktop/";
buf.append(readFile(base + "Test.html"));
newArray[0] = buf.toString();
}
}
catch (JSONException e)
{
// crash and burn
throw new IOException("Error parsing JSON request string");
}
//Get the parameters
OutputStream os = null;
try {
final File outputFile = File.createTempFile("FlyingSacuer.PDFRenderToMultiplePages", ".pdf");
os = new FileOutputStream(outputFile);
ITextRenderer renderer = new ITextRenderer();
// we need to create the target PDF
// we'll create one page per input string, but we call layout for the first
renderer.setScaleToFit(true);
renderer.isScaleToFit();
renderer.setDocumentFromString(newArray[0]);
renderer.layout();
try {
renderer.createPDF(os, false);
} catch (DocumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
// each page after the first we add using layout() followed by writeNextDocument()
for (int i = 1; i < newArray.length; i++) {
renderer.setScaleToFit(true);
renderer.isScaleToFit();
renderer.setDocumentFromString(newArray[i]);
renderer.layout();
try {
renderer.writeNextDocument();
} catch (DocumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
// complete the PDF
renderer.finishPDF();
System.out.println("PDF Downloaded to " + outputFile );
System.out.println(newArray[0]);
}
finally {
if (os != null) {
try {
os.close();
} catch (IOException e) { /*ignore*/ }
}
}
//Return
response.setContentType("application/json");
response.setCharacterEncoding("UTF-8");
response.getWriter().write("File Uploaded");
}
String readFile(String fileName) throws IOException {
BufferedReader br = new BufferedReader(new FileReader(fileName));
try {
StringBuilder sb = new StringBuilder();
String line = br.readLine();
while (line != null) {
sb.append(line);
sb.append("\n");
line = br.readLine();
}
return sb.toString();
} finally {
br.close();
}
}
}
Ссылка для экспортированного PDF: https://drive.google.com/file/d/13CmlJK0ZDLolt7C3yLN2k4uJqV3TX-4B/view?usp=sharing
Я попытался добавить свойства css, такие как page-break-inside: избегать делений на заголовки, но это не сработало. Также я попытался добавить абсолютные позиции и верхние поля в разделение тела (id = "divTemplateBodyPage1") чуть ниже заголовка div, но пробел продолжает существовать.
Любые предложения будут полезны.
1 ответ
Пожалуйста, посмотрите на метаданные вашего PDF:
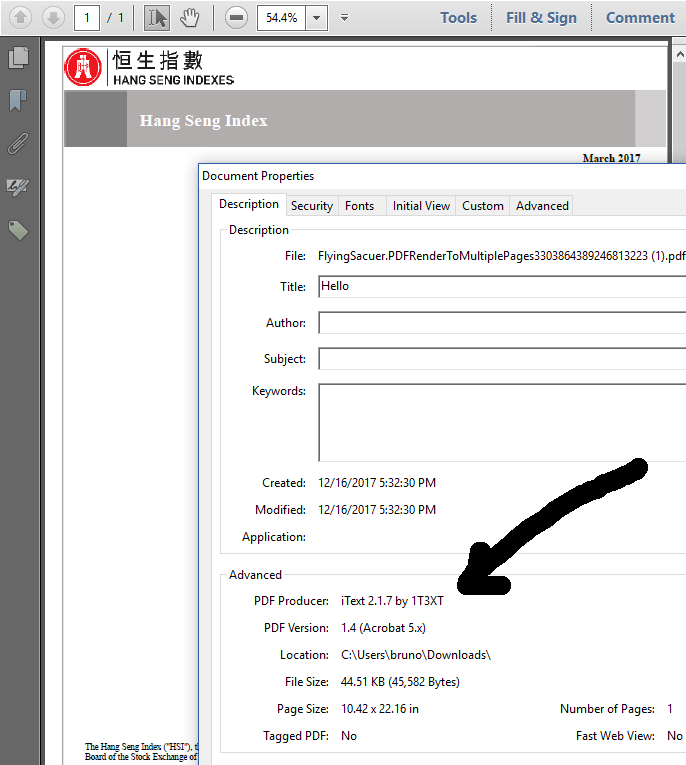
Вы используете старый сторонний инструмент, который не одобрен iText Group, и который использует iText 2.1.7, версию iText, выпущенную в 2009 году, которая больше не должна использоваться.
Вероятно, было бы неплохо пожаловаться и написать "Мой код не работает" около 7 лет назад, но если бы вы использовали самую последнюю версию iText, результат преобразования вашего HTML в PDF выглядел бы так:
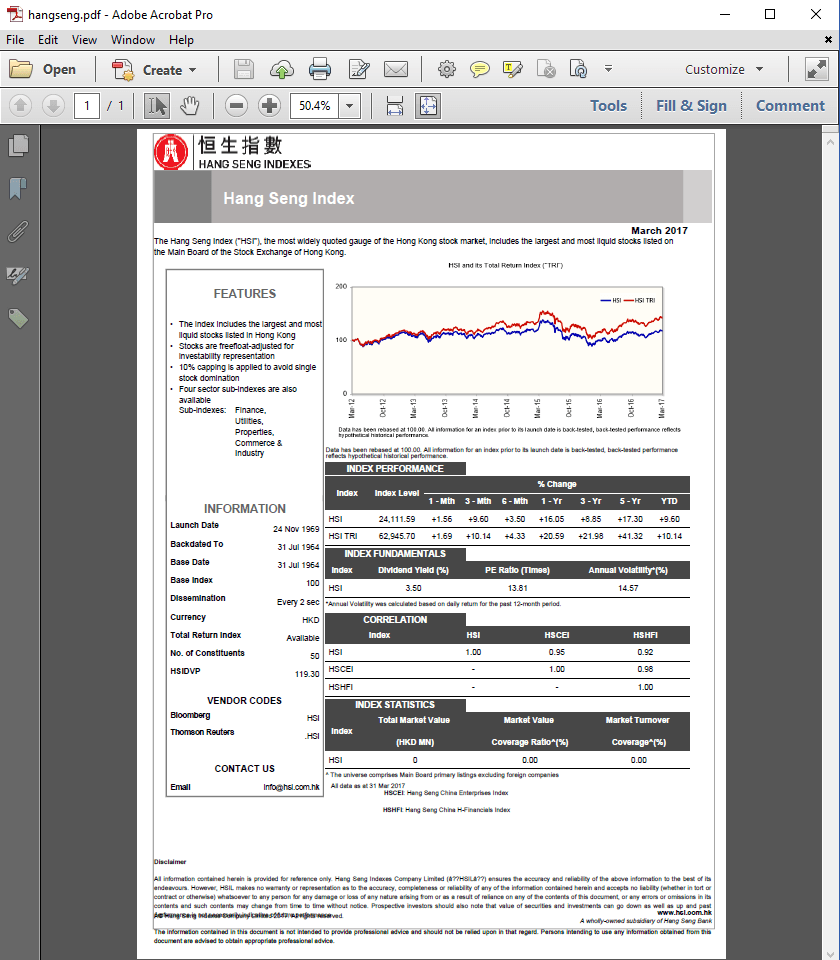
Мне нужна была только одна строка кода, чтобы получить этот результат:
HtmlConverter.convertToPdf(new File(src), new File(dest));
В этой строке src путь к исходному HTML и dest путь к полученному PDF.
Мне нужно было только применить одно небольшое изменение к вашему HTML. Я меняю @page свойства как это:
@page {
size: 27cm 38cm;
margin: 0.2cm;
}
Если бы я не изменил эту часть CSS, размер страницы был бы А4, и в этом случае не весь контент соответствовал бы странице. Я также добавил небольшое поле, потому что мне не нравился тот факт, что граница придерживалась близко к сторонам страницы.
Мораль: не используйте старые версии библиотек! Загрузите последнюю версию iText и дополнение к pdfHTML. Вам нужно ядро iText 7 и дополнение pdfHTML. Вы также можете прочитать учебник HTML в PDF.