Невозможно обработать количество образцов слов как задание Spark
У меня есть spark-master и spark-worker, работающие в среде SAP Kyma (другой вариант Kubernetes), а также Jupyter Lab с достаточным выделением ЦП и ОЗУ.
Я могу получить доступ к пользовательскому интерфейсу Spark Master и увидеть, что рабочие также зарегистрированы (снимок экрана ниже).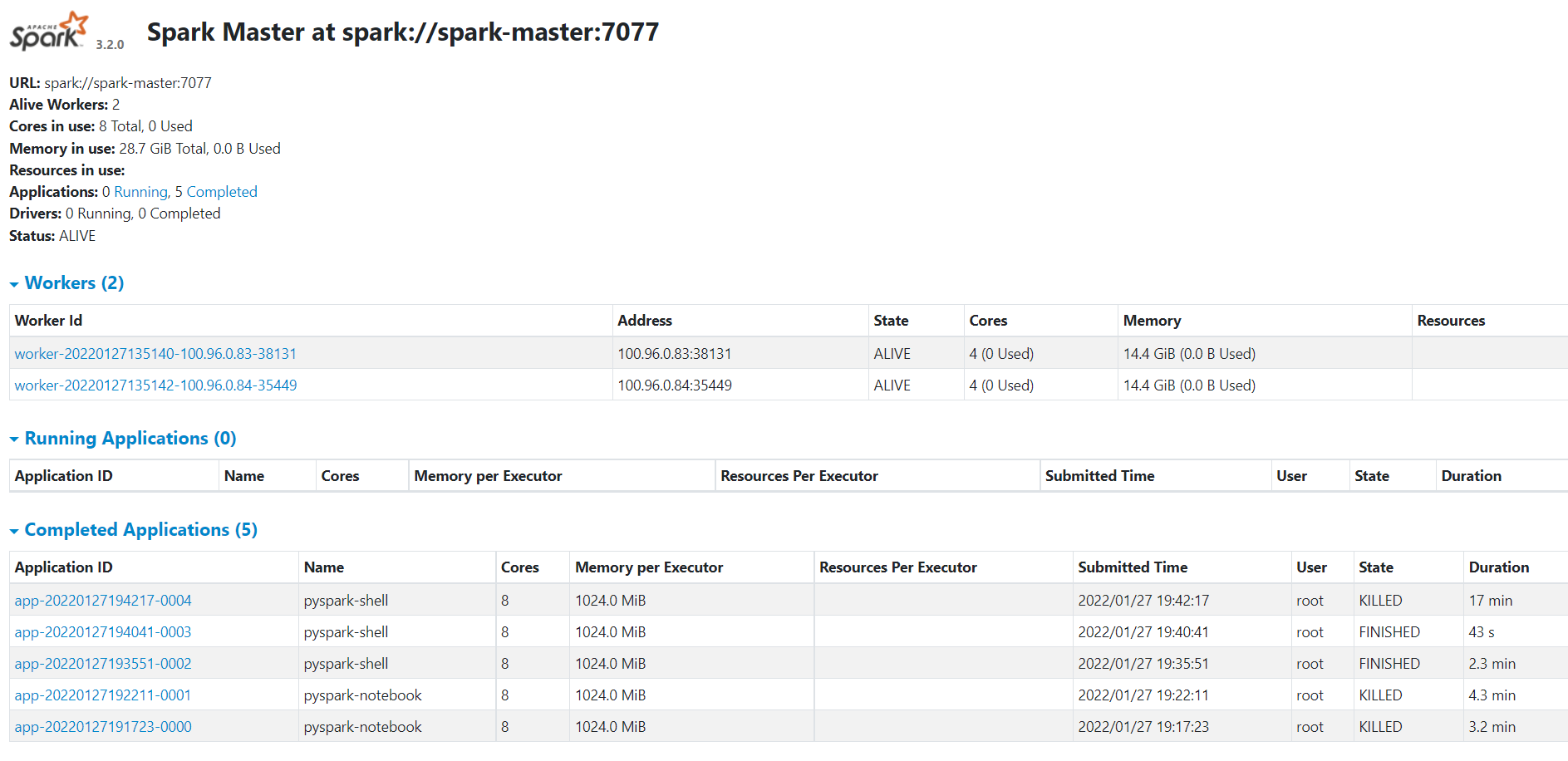
Я использую Python3 для отправки задания (фрагмент ниже)
import pyspark
conf = pyspark.SparkConf()
conf.setMaster('spark://spark-master:7077')
sc = pyspark.SparkContext(conf=conf)
sc
и может видеть контекст искры как вывод
sc. После этого я готовлю данные для отправки мастеру искры (фрагмент ниже)

words = 'the quick brown fox jumps over the lazy dog the quick brown fox jumps over the lazy dog'
seq = words.split()
data = sc.parallelize(seq)
counts = data.map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b).collect()
dict(counts)
sc.stop()
но он начинает регистрировать предупреждающие сообщения на ноутбуке (фрагмент ниже) и продолжается до тех пор, пока я не убью процесс из пользовательского интерфейса spark-master.
22/01/27 19:42:39 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
22/01/27 19:42:54 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
Я новичок в Kyma (Kubernetes) и Spark. Любая помощь приветствуется.
Спасибо
1 ответ
Для тех, кто натыкается на тот же вопрос.
Проверьте свой сертификат инфраструктуры. Оказалось, что Kubernetes выдает неправильный внутренний сертификат, который не распознается модулями.
После того, как мы исправили сертификат, все заработало.