Путаница в хешировании, используемая LSH
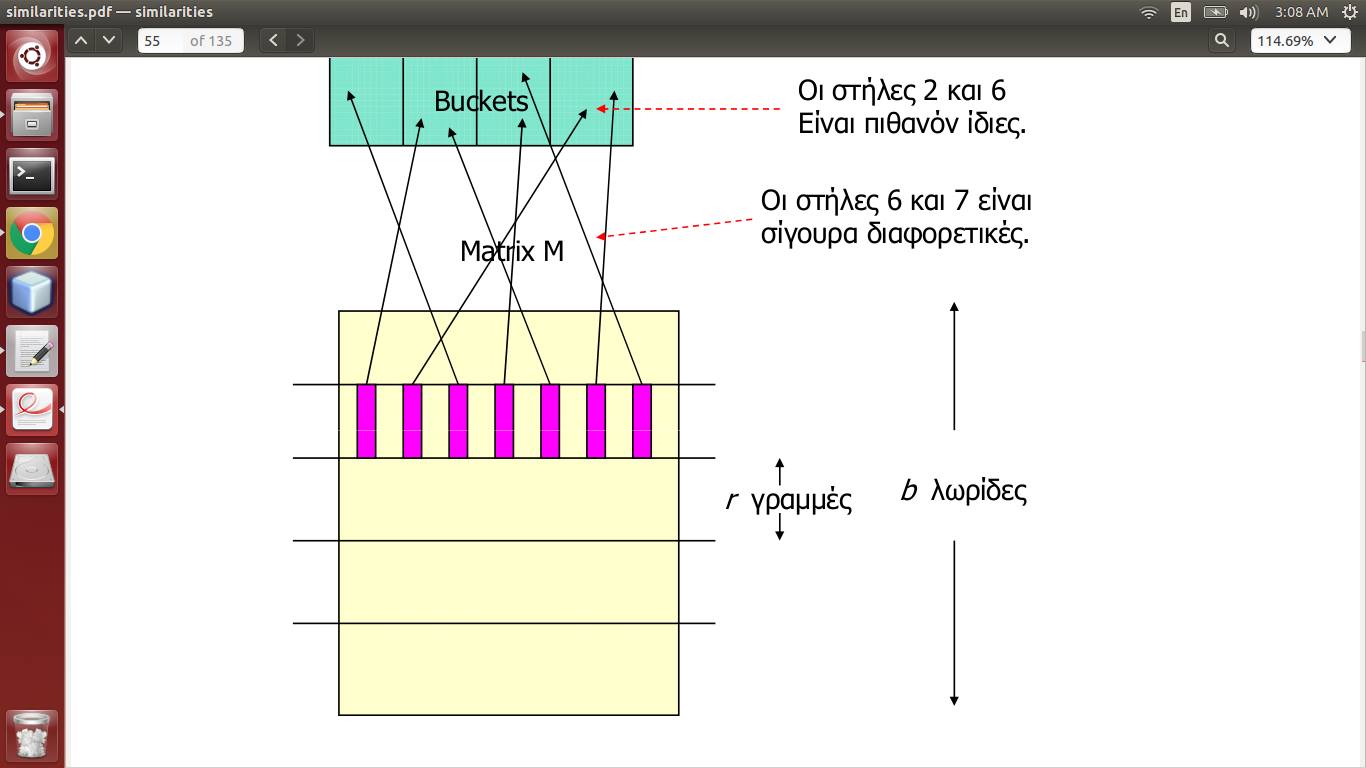
матрица M является матрицей подписей, которая создается с помощью Minhashing реальных данных, имеет документы в виде столбцов и слова в виде строк. Таким образом, столбец представляет документ.
Теперь написано, что каждая полоса (b в количестве, r в длину) имеет хэшированные столбцы, поэтому столбец попадает в область памяти. Если два столбца попадают в один и тот же интервал для>= 1 полос, то они потенциально похожи.
Так что это означает, что я должен создать b Hashtables и найти b независимые хеш-функции? Или достаточно одного, и каждая полоса отправляет свои столбцы в одни и те же наборы блоков (но разве это не отменяет полосы)?
Достаточно ли словаря для хеш-таблицы в этом случае*?
1 ответ
Я думаю, что я понял это, отправляя для будущих читателей.
Я собираюсь использовать один словарь, так как на слайдах упоминается, что можно использовать одну хэш-функцию для каждой полосы ( словари делают это).
Каждое ведро будет ключом для нашего словаря.
При вставке документ (т. Е. Столбец, который принадлежит полосе) будет передан хеш-функцией (которую мы создадим), и результатом должен быть ключ. Таким образом, наш словарь будет заполнен.