Как виртуальные потоки сопоставляются с фактическим потоком
Как написано, виртуальные потоки в конечном итоге отображаются на фактические потоки. Допустим, создано 1 миллион виртуальных потоков. Я предполагаю, что в 8-ядерном процессоре будет 8 потоков ядра. Итак, мои вопросы
- как 1 миллион виртуальных потоков отображается на 8 потоков ядра? Какой алгоритм стоит за этим?
- Почему блокировка в виртуальных потоках обходится дешево? Как я понял, это потому, что он не блокирует поток ядра (ядра). Но поток ядра использует переключение контекста, так почему это все еще дешево?
- Подходит ли виртуальный поток для случаев использования, когда код должен вызывать собственный метод (public native String getSystemTime();)
1 ответ
Отображение виртуальных потоков и потоков ядра выполняется моделью потоков. Доступны 3 вида моделей резьбы
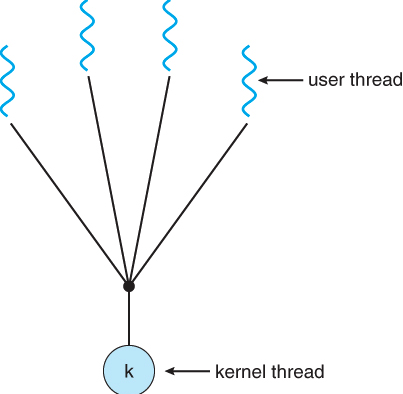
- много к одному
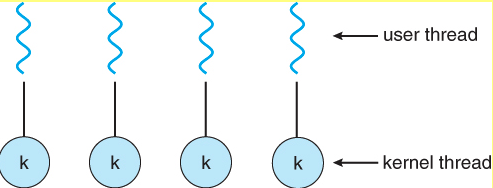
- один к одному
- Многие ко многим
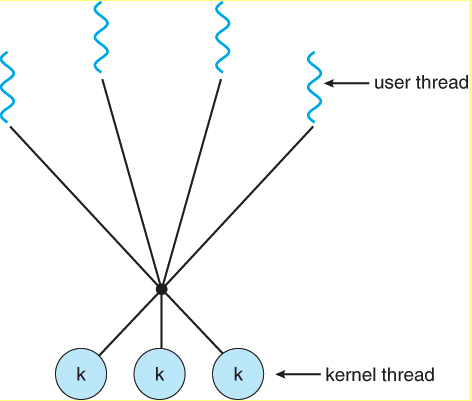
По сути, библиотека потоков поддерживает сопоставление пользовательских/виртуальных потоков с потоками ядра.
- Блокировать пользовательский поток легко, потому что все, что нужно сделать потокам ядра, — это сохранить состояние пользовательского потока внутри потока ядра или самого процесса и выбрать другой пользовательский поток. С другой стороны, если потоку ядра необходимо переключение контекста, необходимо удалить и сохранить в памяти большой набор регистров. Этот процесс является дорогостоящим.
Кроме того, создание потока ядра требует создания полного блока управления потоком, чтобы ядро могло управлять этими потоками. Этот процесс снова идет медленно.
- Вы всегда работаете на уровне пользовательского потока. Таким образом, любой вызов, который вы делаете, должен быть в самом пользовательском потоке.