Вопрос о токенах, используемых в слоях внимания декодера Transformer во время логического вывода
Я смотрел на формы, используемые во время декодирования (как блоки самовнимания, так и enc-dec-Внимание), и понял, что есть разница в способе работы декодера во время обучения и во время вывода на и оригинального документа Attention.
Inference, он использует все предыдущие токены, сгенерированные до этого временного шага (скажем, th), как показано на диаграмме ниже и объяснено по основе этой ссылкиэтой ссылке.
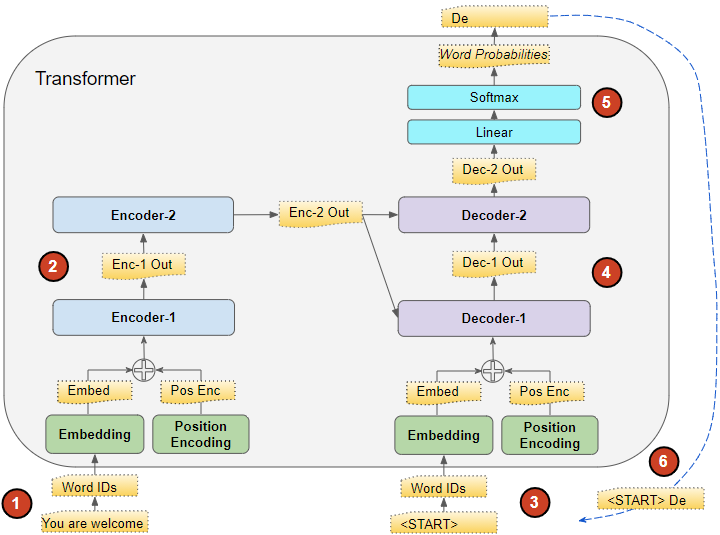
Проблема:
Однако, когда я смотрю на фактические формы проекции QKV в самовнимании декодера и на передачу выходных данных самовнимания декодера на Q-матрицу "enc-dec-Внимание", я вижу только 1 токен из выходных данных. использовал.
Я очень смущен тем, как формы для всех матриц в самовнимании декодера и enc-dec-Внимание могут совпадать с переменной длиной ввода в декодер во время логического вывода. Я просмотрел несколько онлайн-материалов, но не нашел ответа. Я вижу только BGemms в самовнимании декодера (не enc-dec-Внимание) с использованием переменных форм до тех пор, пока все предыдущие
k шагов, но все остальные драгоценные камни имеют фиксированный размер.
- Как такое возможно? Используется ли только 1 токен (последний из выходных данных декодера) для qkv matmuls в самовнимании и Q-matmul в enc-dec-Внимание (это то, что я вижу при запуске модели)?
- Может ли кто-нибудь уточнить, как все эти формы для QKV в самовнимании и Q в enc-dec-Внимание совпадают с длиной входного сигнала декодера, различающейся на каждом временном шаге?**
Еще одна диаграмма, показывающая самовнимание и enc-dec-внимание в декодере:
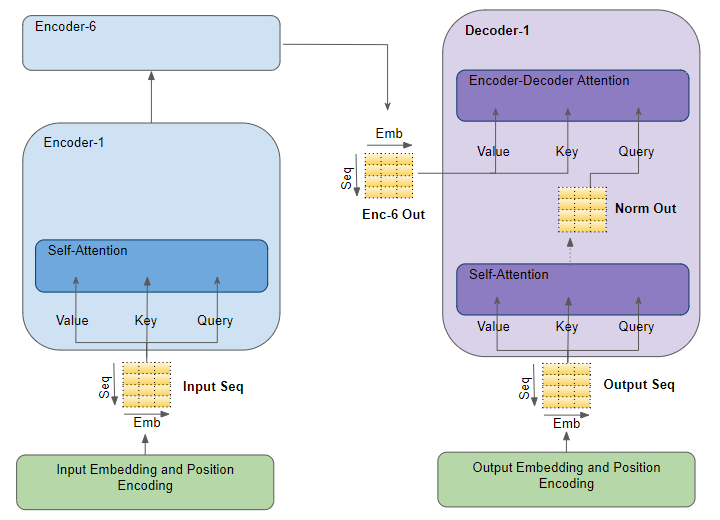
1 ответ
- Это возможно, потому что обычно в трансформаторе у вас есть предыдущие пары ключ-значение, которые активны только на этапе вывода. Эти предыдущие ключи и значения добавляются к этому одному токену, который был сгенерирован, а затем он передается на уровень внедрения и обновляется на каждом этапе генерации, чтобы сформировать окончательные ключи-значения, от которых зависит новый токен для создания следующего токена, в таким образом вы обращаете внимание на текущий токен и все ранее сгенерированные токены. Затем предыдущие ключи-значения снова обновляются для использования на следующем этапе генерации, чтобы понять, что лучше отслеживать процесс вывода токена за токеном, который я делал раньше. о, подождите, что за шаги первого поколения, тогда у нас нет прямой связи! что такое предыдущие ключи-значения? их тоже нет!
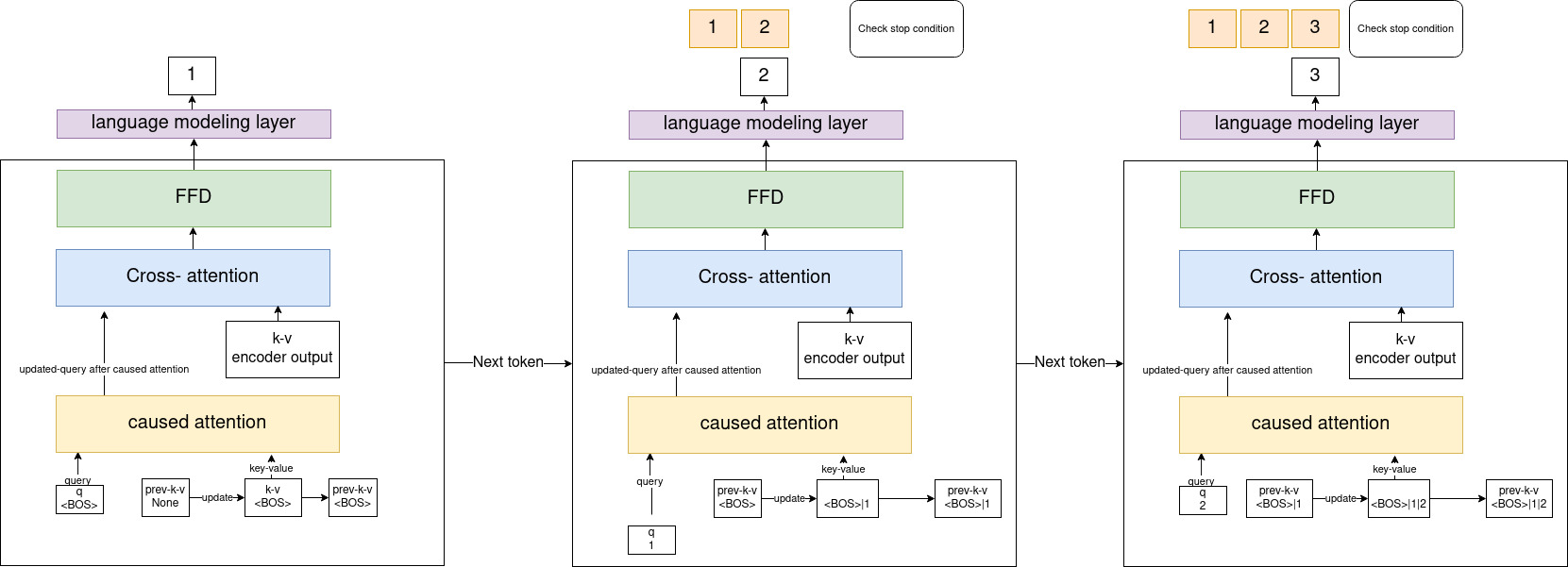
- Для форм входная форма для декодера фиксирована, как мы видим из приведенной выше диаграммы, она всегда одна (последний сгенерированный токен из выходных данных декодера!) обратите внимание, что форма вывода внимания всегда такая же, как форма запроса, т.е. Чтобы лучше понять, я приведу T5 от обнимания лица в качестве примера, это условие объясняет, о чем я говорю, когда впервые проецирую ключи и значения для генерации первого токена, а для жадного поиска вы можете увидеть здесь , как для генерации они вызывают весь преобразователь модель для создания только следующего токена, здесь они объединяют новый сгенерированный токен с предыдущими сгенерированными токенами, чтобы проверить условие остановкичто позже либо генерирует токен, либо достигает максимальной длины сгенерированных токенов.
Надеюсь, это ответит на ваш вопрос, все это было из моей предыдущей попытки понять процесс вывода.