Запись в CSV на Python- строки вставлены не на своем месте
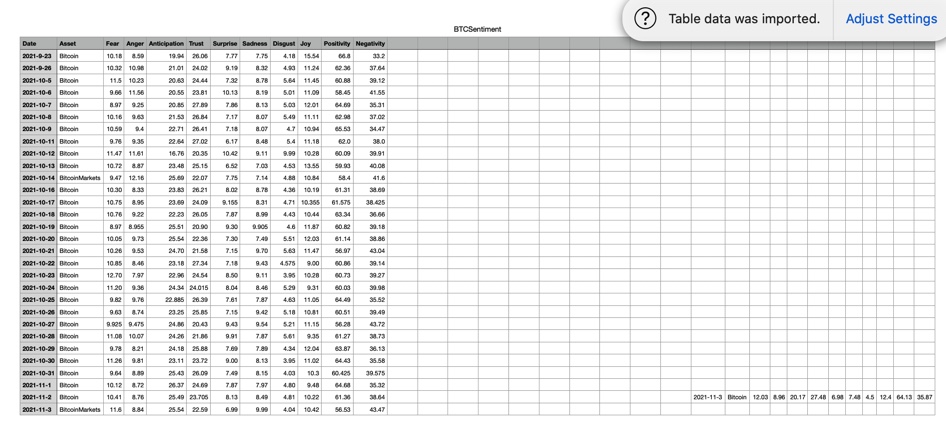
У меня есть функция, которая записывает набор информации в строках в файл CSV на Python. Функция должна добавить файл с новой строкой, однако я обнаружил, что иногда она ведет себя неправильно и помещает новую строку в отдельное пространство CSV (см. Рисунок в качестве примера).
Каждый раз, когда я переформатирую данные вручную, я снова удаляю все пустые ячейки, чтобы вы знали.
Надеюсь, кто-то может помочь, спасибо!
def Logger():
fileName = myDict[Sub]
with open(fileName, 'a+', newline="") as file:
writer = csv.writer(file)
if file.tell() == 0:
writer.writerow(["Date", "Asset", "Fear", "Anger", "Anticipation", "Trust", "Surprise", "Sadness", "Disgust", "Joy",
"Positivity", "Negativity"])
writer.writerow([date, Sub, fear, anger, anticip, trust, surprise, sadness, disgust, joy, positivity, negativity])
2 ответа
Сначала я подумал, что это просто вопрос отсутствия конечной новой строки и добавления новой строки к той же строке, сразу после последней строки, но я могу видеть то, что выглядит как строка пустых столбцов между ними.
Вся эта штука с добавлением выглядит запутанной. Если вам не нужно использовать Python и вместо этого вы можете использовать инструмент командной строки, я рекомендую GoCSV.
Вот пример файла на основе вашего скриншота, который я скопировал:
base.csv
Date,Asset,Fear,Anger,Anticipation,Trust,Surprise,Sadness,Disgust,Joy,Positivity,Negativity
Nov 1,5088,0.84,0.58,0.73,1.0,0.26,0.89,0.22,0.5,0.69,0.59
Nov 2,4580,0.0,0.88,0.7,0.71,0.57,0.78,0.2,0.22,0.21,0.17
Nov 3,2469,0.72,0.4,0.66,0.53,0.65,0.64,0.67,0.78,0.54,0.32,,,,,,,
Я называю это базовым, потому что это файл, который будет расти, и вы можете видеть, что у него проблема в последней строке: все эти дополнительные запятые (я не знаю, как они туда попали 🤷🏻♂️).
Первым шагом будет его очистка и удаление этих надоедливых лишних запятых:
% gocsv clean base.csv > tmp
% mv tmp > base.csv
и теперь base.csv выглядит так:
Date,Asset,Fear,Anger,Anticipation,Trust,Surprise,Sadness,Disgust,Joy,Positivity,Negativity
Nov 1,5088,0.84,0.58,0.73,1.0,0.26,0.89,0.22,0.5,0.69,0.59
Nov 2,4580,0.0,0.88,0.7,0.71,0.57,0.78,0.2,0.22,0.21,0.17
Nov 3,2469,0.72,0.4,0.66,0.53,0.65,0.64,0.67,0.78,0.54,0.32
Вот еще один набор данных, который нужно добавить, sample2.csv :
Date,Asset,Fear,Anger,Anticipation,Trust,Surprise,Sadness,Disgust,Joy,Positivity,Negativity
Nov 4,6040,0.69,0.89,0.72,0.44,0.21,0.15,0.03,0.63,0.78,0.42
Nov 5,7726,0.72,0.12,0.95,0.6,0.88,0.1,0.43,1.0,1.0,0.68
Nov 6,9028,0.87,0.34,0.46,0.57,0.15,0.3,0.8,0.32,0.17,0.42
Nov 7,3544,0.16,0.9,0.37,0.8,0.67,0.0,0.11,0.72,0.93,0.35
Команда стекаGoCSV выполнит эту работу:
% gocsv stack base.csv sample2.csv > tmp
% mv tmp base.csv
и теперь base.csv выглядит так:
Date,Asset,Fear,Anger,Anticipation,Trust,Surprise,Sadness,Disgust,Joy,Positivity,Negativity
Nov 1,5088,0.84,0.58,0.73,1.0,0.26,0.89,0.22,0.5,0.69,0.59
Nov 2,4580,0.0,0.88,0.7,0.71,0.57,0.78,0.2,0.22,0.21,0.17
Nov 3,2469,0.72,0.4,0.66,0.53,0.65,0.64,0.67,0.78,0.54,0.32
Nov 4,6040,0.69,0.89,0.72,0.44,0.21,0.15,0.03,0.63,0.78,0.42
Nov 5,7726,0.72,0.12,0.95,0.6,0.88,0.1,0.43,1.0,1.0,0.68
Nov 6,9028,0.87,0.34,0.46,0.57,0.15,0.3,0.8,0.32,0.17,0.42
Nov 7,3544,0.16,0.9,0.37,0.8,0.67,0.0,0.11,0.72,0.93,0.35
Это можно записать и упростить следующим образом:
% gocsv clean base.csv > base
% gocsv clean sample.csv > sample
% gocsv stack base sample > base.csv
% rm base sample
Попробуйте вместо этого ...
def Logger(col_one, col_two):
fileName = 'data.csv'
with open(fileName, 'a+') as file:
writer = csv.writer(file)
file.seek(0)
if file.read().strip() == '':
writer.writerow(["Date", "Asset"])
writer.writerow([col_one, col_two])