Тонкая настройка модели преобразователя предложений BERT
Я использую предварительно обученную модель преобразователя предложений BERT, как описано здесь https://www.sbert.net/docs/training/overview.html , чтобы получить вложения для предложений.
Я хочу точно настроить эти предварительно обученные вложения, и я следую инструкциям в руководстве, которое я связал выше. Согласно руководству, вы настраиваете предварительно обученную модель, вводя в нее пары предложений и метку, которая указывает оценку сходства между двумя предложениями в паре. Я понимаю, что эта тонкая настройка происходит с использованием архитектуры, показанной на изображении ниже:
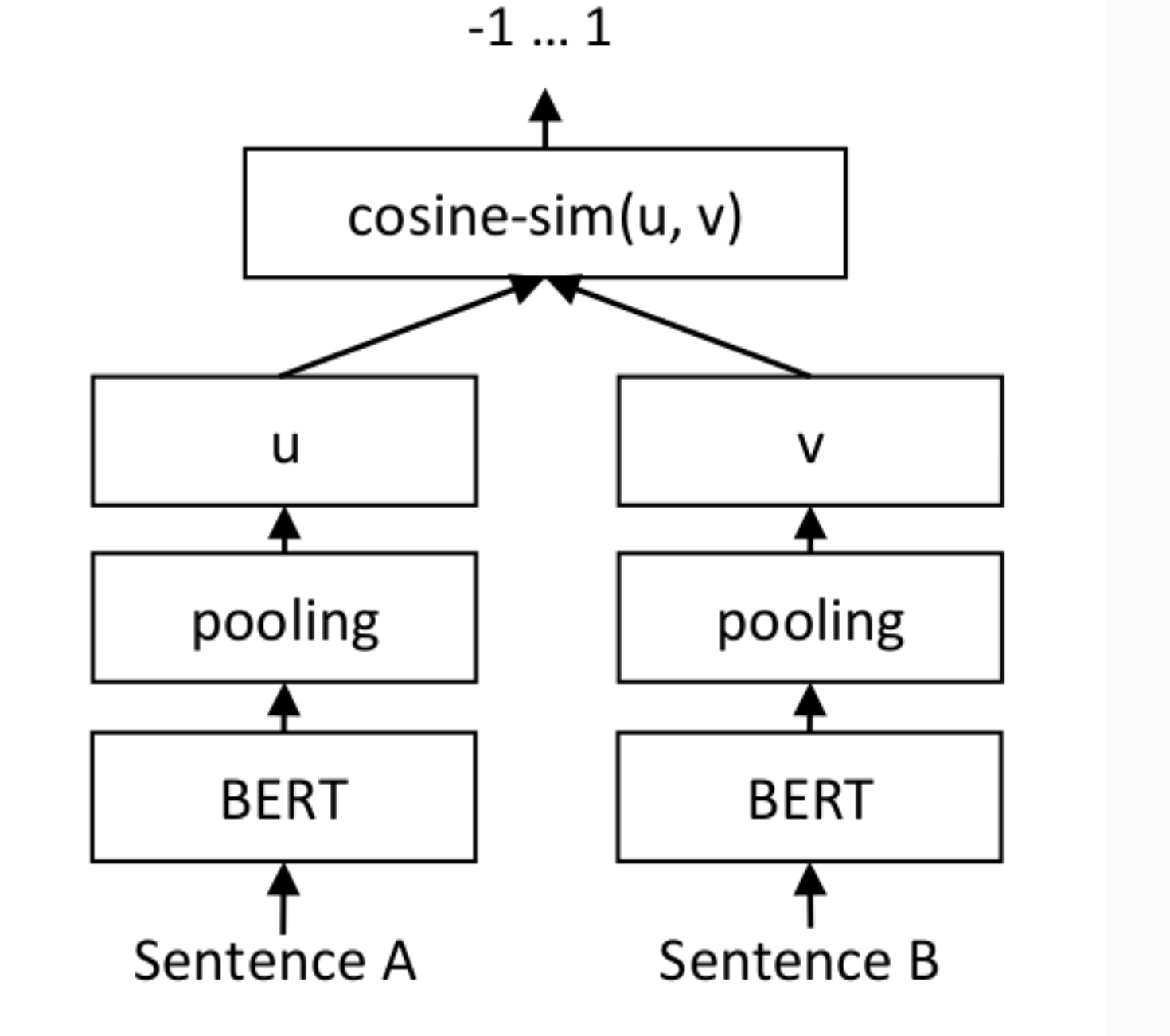
Каждое предложение в паре сначала кодируется с использованием модели BERT, а затем «объединяющий» слой агрегирует (обычно путем усреднения) встраивания слов, произведенных слоем Берта, для создания одного вложения для каждого предложения. Косинусное сходство двух вложений предложений вычисляется на последнем этапе и сравнивается с оценкой метки.
У меня вопрос - какие параметры оптимизируются при точной настройке модели с использованием данной архитектуры? Это тонкая настройка только параметров последнего слоя в модели BERT? Мне это не ясно, глядя на пример кода, показанный в руководстве для точной настройки модели.
1 ответ
Это на самом деле зависит от ваших требований. Если у вас много вычислительных ресурсов и вы хотите получить идеальное представление предложения, вам следует точно настроить все слои (что и было сделано в исходной модели Берта предложения).
Но если вы студент и хотите создать почти хорошее представление предложения, вы можете обучать только слои, не относящиеся к bert.