как обучить бертовскую модель с нуля с помощью huggingface?
Я нахожу ответ модели обучения с нуля в этом вопросе:Как обучить BERT с нуля на новом домене как для MLM, так и для NSP?
в одном ответе используются такие аргументы, как Trainer и TrainingArguments:
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir= "/path/to/output/dir/for/training/arguments"
overwrite_output_dir=True,
num_train_epochs=2,
per_gpu_train_batch_size= 16,
save_steps=10_000,
save_total_limit=2,
prediction_loss_only=True,
)
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=dataset,
)
trainer.train()
trainer.save_model("path/to/your/model")
но официальный документ huggingface также использует Trainer и TrainingArguments таким же образом для точной Тонкая настройка предварительно обученной моделинастройки . Итак, когда я использую Trainer и TrainingArguments для обучения модели, я обучаю модель с нуля или просто настраиваю?
1 ответ
Привет, во-первых, спасибо за ссылку на мой вопрос, я сделаю все возможное, чтобы прояснить его :)
Прежде всего, нет большой разницы между предварительной тренировкой и тонкой настройкой. Единственное отличие состоит в том, что при предварительном обучении вы тренируете свою модель с нуля, то есть вы инициализируете веса начальным значением (оно может быть случайным или нулевым), однако при точной настройке вы фактически загружаете предварительно обученную модель, а затем обучаете ее. снова для нисходящей задачи, поэтому в основном то, что вы делаете, это инициализация весов с помощью предварительно обученной модели. Поэтому вы можете использовать знания, полученные предварительно обученной моделью.
Давайте попробуем разобраться в архитектуре тонкой настройки и предварительной подготовки. На следующей диаграмме показан обзор архитектуры предварительного обучения.
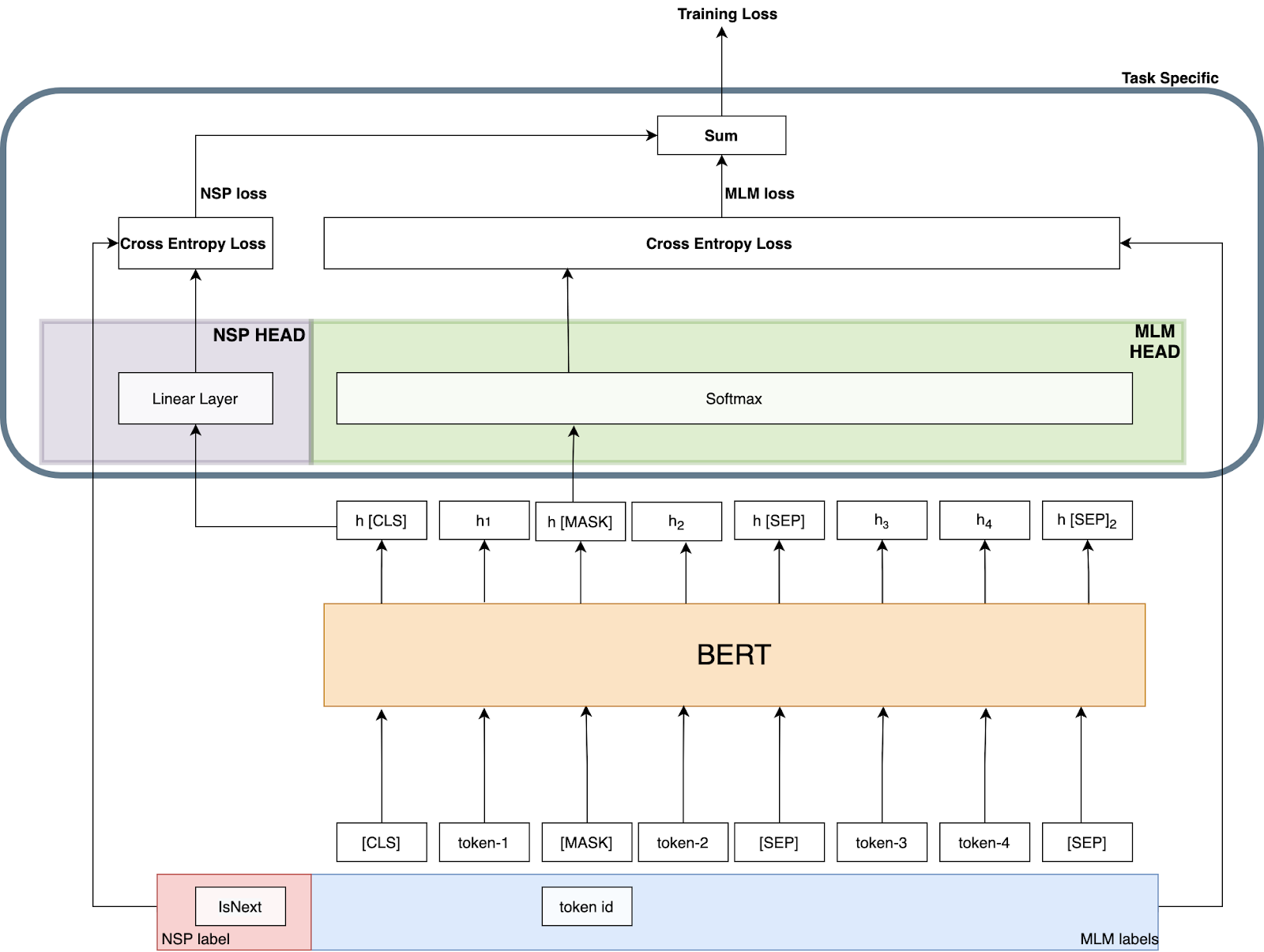
Когда вы настраиваете модель BERT, вы изменяете область и метки этой задачи. Когда вы меняете конкретную область задачи, вы меняете общую архитектуру. Вы меняете головы. Также это изменение коснулось названия модели, которую вы используете в Transformers. Например, BertForPreTraining использует одновременно заголовок MLM и NSP, тогда как BertForSequenceClassification использует линейный слой в качестве заголовка, как и в NSP. Но что их объединяет, так это то, что они обертывают модель BERT. Таким образом, мы просто меняем «специфическую для задачи» область (архитектуру). Именно это они имели в виду, заявляя: «Существует минимальная разница между предварительно обученной архитектурой и окончательной нижестоящей архитектурой». в бумаге BERT.
Если вы хотите изменить задачу предварительного обучения BERT, вы должны изменить архитектуру конкретной области задачи и меток ввода, как я сделал в « Предсказание того же предложения: новая задача предварительного обучения для BERT » (Github Repo). То же самое касается процесса тонкой настройки. Если вы хотите настроить архитектуру тонкой настройки для последующей задачи, все, что вам нужно сделать, это изменить архитектуру конкретной области задачи.
Так что не имеет значения использование Trainer для предварительной тренировки или тонкой настройки. Тренер в основном обновляет веса модели в соответствии с потерями при обучении. Если вы используете предварительно обученный BERT с головками, специфичными для последующих задач, он обновит веса как в модели BERT, так и в головках, специфичных для задачи (если вы не укажете иначе, заморозив веса модели BERT). Если вы используете необученную модель BERT с головками для конкретных задач, она также обновит веса.