Как сохранить разреженный индекс в LSM-дереве?
В разделе «Разработка приложений с интенсивным использованием данных» Мартин вводит структуру данных, называемую LSM-деревьями.
В основном это 3 части: таблица памяти в памяти (обычно красно-черное дерево), разреженный индекс в памяти и SSTables на диске (также известные как сегменты). Они работают вместе так:
Когда происходит запись, она сначала попадает в memtable, а когда заполняется, все данные сбрасываются в новый сегмент (со всеми отсортированными ключами).
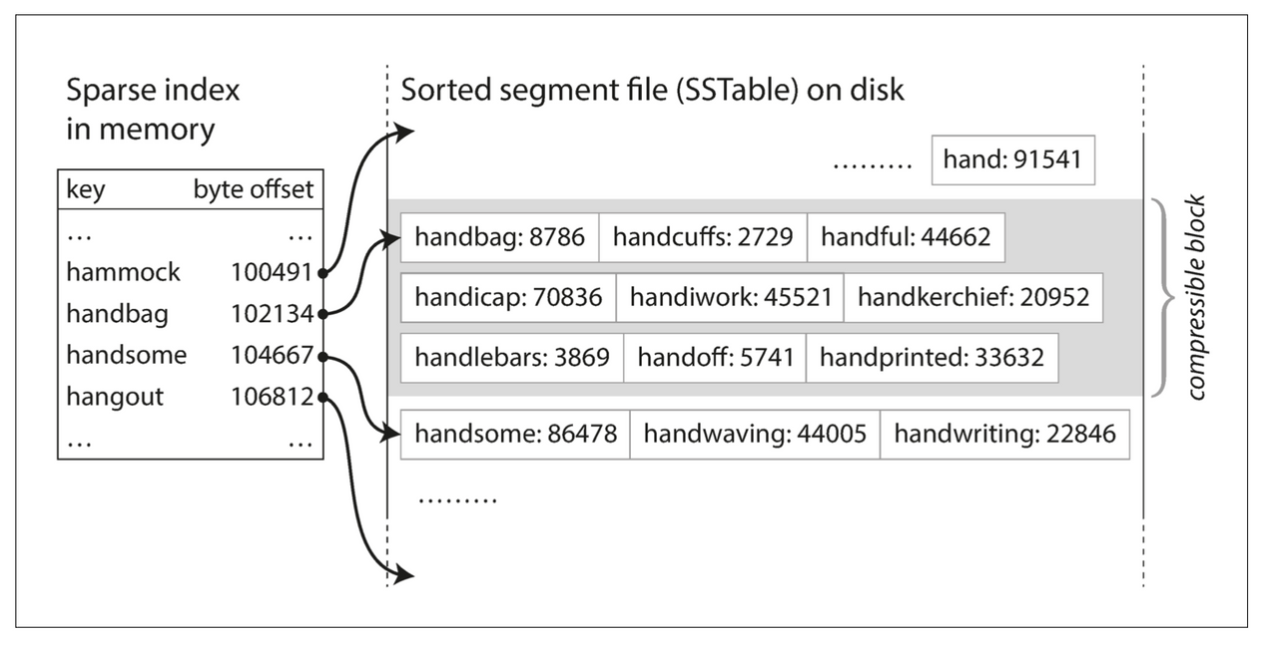
Когда происходит чтение, сначала выполняется поиск по memtable. Если ключа там нет, он ищет разреженный индекс, чтобы узнать, в каком сегменте может находиться ключ. См. Рисунок 1.
Периодически происходит уплотнение, объединяющее несколько сегментов в один. См. Рисунок 2.
Как видно из рисунка 2, ключи сортируются внутри сегмента, но ключи НЕ сортируются между сегментами. Это заставляет меня задаться вопросом: как мы поддерживаем разреженные ключи индекса st в индексе с увеличивающимся смещением?

1 ответ
Типичный подход состоит в том, чтобы иметь отдельный индекс для каждого файла сегмента, и этот индекс повторно генерируется во время сжатия / слияния файлов сегментов. Затем при чтении ключа мы должны проверить несколько файлов текущего сегмента, которые могут содержать ключ, и вернуть значение, которое появляется в самом последнем из этих сегментов.
Невозможно определить, просто взглянув на индекс, содержит ли конкретный сегмент определенный ключ. Чтобы избежать чтения с диска для каждого сегмента, общая оптимизация состоит в том, чтобы иметь фильтр Блума (или аналогичную структуру данных, такую как фильтр кукушки) для каждого сегмента, который суммирует ключи, содержащиеся в этом сегменте. Это позволяет операции чтения выполнять чтение с диска только для тех сегментов, которые фактически содержат желаемый ключ (с небольшой вероятностью выполнения ненужных операций чтения с диска из-за ложных срабатываний фильтра Блума).