Сложенная гистограмма от уже суммированных подсчетов, используя ggplot2
Мне нужна помощь в раскраске гистограммы ggplot2, сгенерированной из уже суммированных данных подсчета.
Данные являются чем-то вроде подсчета числа # мужчин и # женщин, живущих в ряде различных областей. Достаточно просто построить гистограмму для общего количества (то есть мужчин и женщин):
set.seed(1)
N=100;
X=data.frame(C1=rnbinom(N,15,0.1), C2=rnbinom(N,15,0.1),C=rep(0,N));
X$C=X$C1+X$C2;
ggplot(X,aes(x=C)) + geom_histogram()
Тем не менее, я хотел бы раскрасить каждый столбец в соответствии с относительным вкладом от C1 и C2, чтобы я получил ту же гистограмму (то есть общую высоту столбцов), что и в приведенном выше примере, плюс я вижу соотношение типа "C1" и "C2" индивидуумы, как на гистограмме с накоплением.
Предложения по чистому способу сделать это с помощью ggplot2, используя данные типа "X" в примере?
3 ответа
Очень быстро вы можете делать то, что хочет ОП, используя stat="identity" вариант и plyr Пакет для ручного расчета гистограммы, вот так:
library(plyr)
X$mid <- floor(X$C/20)*20+10
X_plot <- ddply(X, .(mid), summarize, total=length(C), split=sum(C1)/sum(C)*length(C))
ggplot(data=X_plot) + geom_histogram(aes(x=mid, y=total), fill="blue", stat="identity") + geom_histogram(aes(x=mid, y=split), fill="deeppink", stat="identity")
По сути, мы просто создаем столбец "mids" для определения местоположения столбцов, а затем создаем два графика: один с количеством для общего количества (C) и один с столбцами, настроенными на количество одного из столбцов (C1). Вы должны быть в состоянии настроить здесь.

Обновление 1: я понял, что сделал небольшую ошибку при расчете среднего. Исправлено сейчас. Кроме того, я не знаю, почему я использовал выражение "ddply" для вычисления среднего. Это было глупо. Новый код понятнее и лаконичнее.
Обновление 2: я вернулся, чтобы просмотреть комментарий, и заметил что-то немного ужасающее: я использовал суммы в качестве частот гистограммы. Я немного очистил код, а также добавил предложения из комментариев относительно синтаксиса раскраски.
Вот взломать с помощью ggplot_build, Идея состоит в том, чтобы сначала получить свой старый / оригинальный сюжет:
p <- ggplot(data = X, aes(x=C)) + geom_histogram()
Хранится в p, Затем используйте ggplot_build(p)$data[[1]] чтобы извлечь данные, в частности, столбцы xmin а также xmax (чтобы получить те же разрывы / ширины гистограммы) и count столбец (чтобы нормализовать процент по count, Вот код:
# get old plot
p <- ggplot(data = X, aes(x=C)) + geom_histogram()
# get data of old plot: cols = count, xmin and xmax
d <- ggplot_build(p)$data[[1]][c("count", "xmin", "xmax")]
# add a id colum for ddply
d$id <- seq(nrow(d))
Как генерировать данные сейчас? Что я понимаю из вашего поста, так это. Возьмите, например, первый бар на вашем участке. Он имеет счет 2 и простирается от xmin = 147 в xmax = 156.8, Когда мы проверяем X для этих значений:
X[X$C >= 147 & X$C <= 156.8, ] # count = 2 as shown below
# C1 C2 C
# 19 91 63 154
# 75 86 70 156
Здесь я вычисляю (91+86)/(154+156)*(count=2) = 1.141935 а также (63+70)/(154+156) * (count=2) = 0.8580645 как два нормализованных значения для каждого бара мы будем генерировать.
require(plyr)
dd <- ddply(d, .(id), function(x) {
t <- X[X$C >= x$xmin & X$C <= x$xmax, ]
if(nrow(t) == 0) return(c(0,0))
p <- colSums(t)[1:2]/colSums(t)[3] * x$count
})
# then, it just normal plotting
require(reshape2)
dd <- melt(dd, id.var="id")
ggplot(data = dd, aes(x=id, y=value)) +
geom_bar(aes(fill=variable), stat="identity", group=1)
И это оригинальный сюжет:

И вот что я получаю:

Изменить: Если вы также хотите получить правильные перерывы, то вы можете получить соответствующие x координаты из старого сюжета и использовать его здесь вместо id:
p <- ggplot(data = X, aes(x=C)) + geom_histogram()
d <- ggplot_build(p)$data[[1]][c("count", "x", "xmin", "xmax")]
d$id <- seq(nrow(d))
require(plyr)
dd <- ddply(d, .(id), function(x) {
t <- X[X$C >= x$xmin & X$C <= x$xmax, ]
if(nrow(t) == 0) return(c(x$x,0,0))
p <- c(x=x$x, colSums(t)[1:2]/colSums(t)[3] * x$count)
})
require(reshape2)
dd.m <- melt(dd, id.var="V1", measure.var=c("V2", "V3"))
ggplot(data = dd.m, aes(x=V1, y=value)) +
geom_bar(aes(fill=variable), stat="identity", group=1)
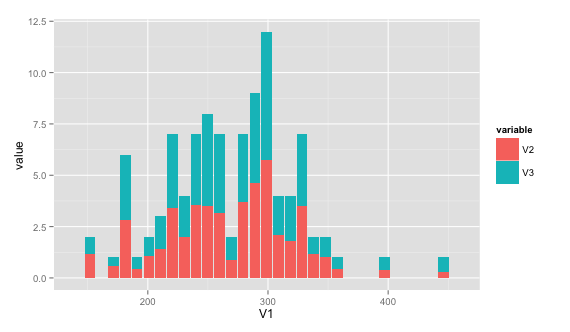
Как насчет:
library("reshape2")
mm <- melt(X[,1:2])
ggplot(mm,aes(x=value,fill=variable))+geom_histogram(position="stack")