Подача изображения в сложенные блоки resnet для создания вложения
У вас есть какой-нибудь пример кода или документ, который ссылается на что-то вроде следующей диаграммы?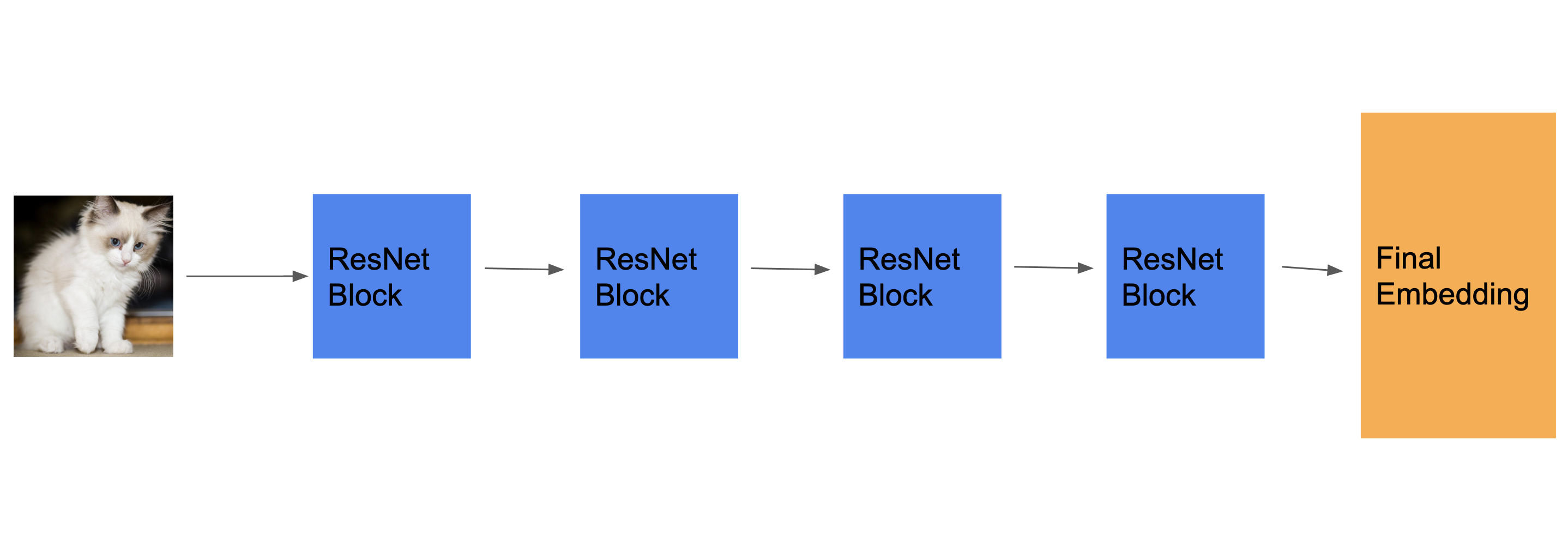
Я хочу знать, почему мы хотим складывать несколько блоков повторной сети, а не несколько сверточных блоков, как в более традиционных архитектурах? Любой пример кода или ссылка на него будут действительно полезны.
Кроме того, как я могу передать это что-то вроде следующего, которое может содержать модуль самовнимания для каждого блока resnet?
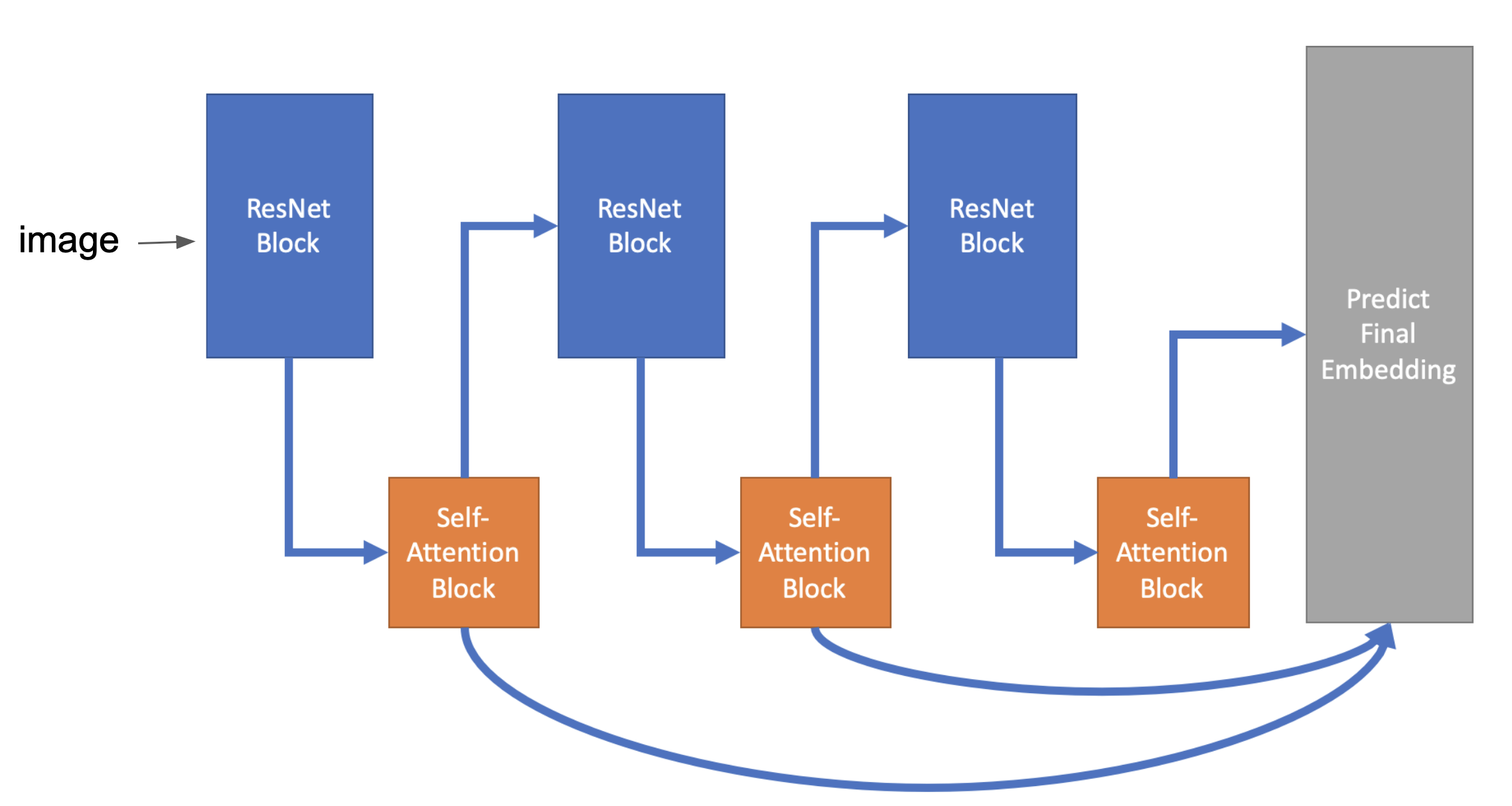
1 ответ
Применение собственного внимания к выходным данным блоков Resnet при очень высоком разрешении входного изображения может привести к проблемам с памятью: требования к памяти для блоков самовнимания растут квадратично с размером входных данных (= разрешение). Вот почему, например, в работах Xiaolong Wang, Ross Girshick, Abhinav Gupta, Kaiming He Non-Local Neural Networks (CVPR 2018) они представили самовнимание только на очень глубоком уровне архитектуры, когда карта характеристик была существенно ниже. отобранный.