Apache Iceberg для индексации AWS S3
У меня есть пример использования, когда на S3 хранится около 100 миллионов файлов. У меня есть файл манифеста отдельно для расположения этих файлов на основе моей модели данных. Я хочу понять, подходит ли Apache Iceberg для индексирования моих файлов S3.
Читая по документациюIceberg , кажется, что в ней говорится о создании таблицы с одним столбцом, являющимся целевым местоположением S3. Если это так, то чем она отличается от обычной реляционной таблицы, в которой я храню путь S3 и другие столбцы, относящиеся к моей модели.
Любые указатели или примеры, когда люди использовали индексацию S3 с Iceberg, были бы полезны.
1 ответ
Это немного отличается от того, что происходит. Что делает Iceberg, так это создает вторичный уровень метаданных отдельно от фактических данных таблицы. Эти метаданные - это то, что на самом деле имеет поле «путь» для конкретной строки.
Если вы посмотрите на эту диаграмму 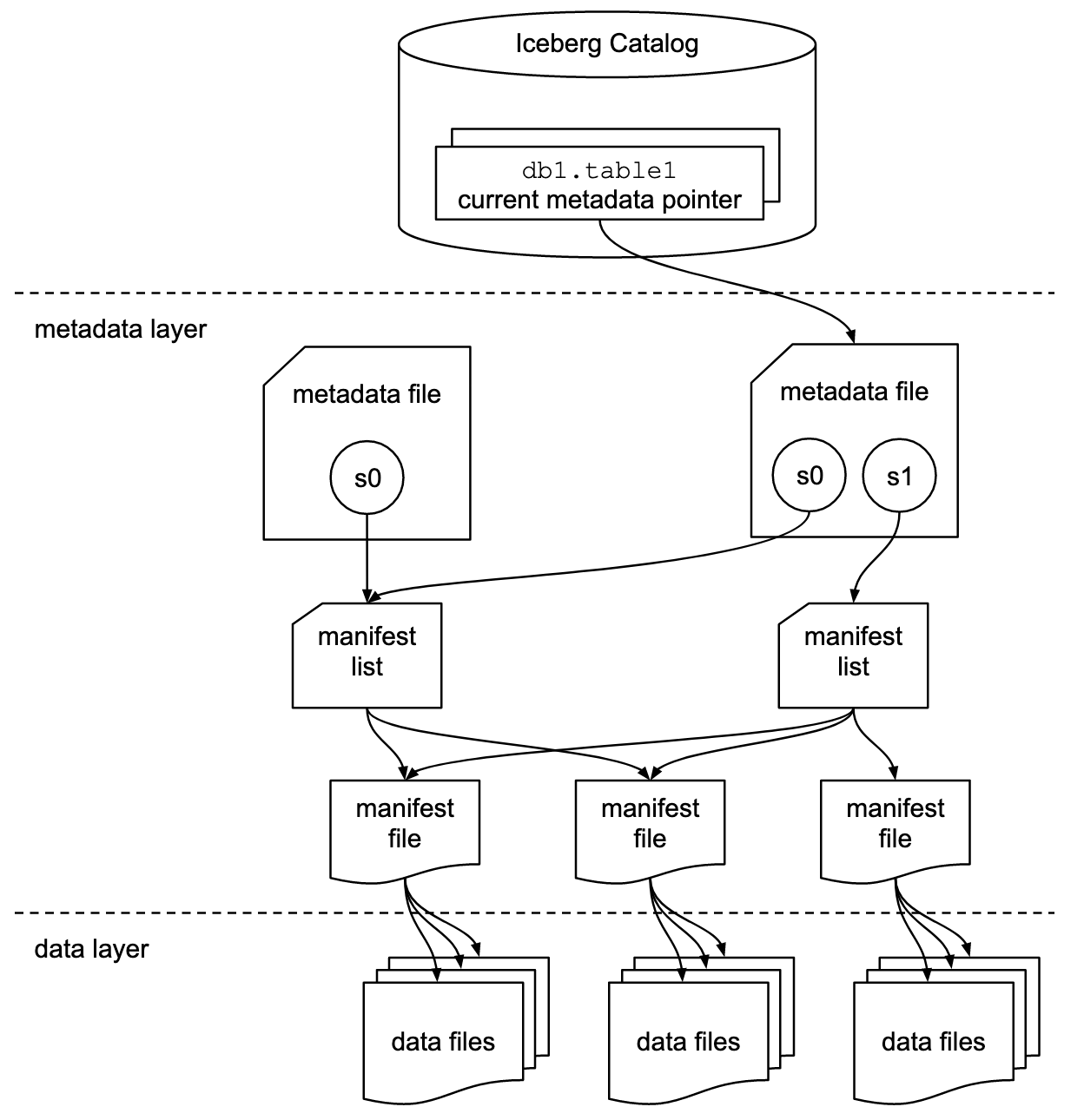
Информация о пути хранится в «файле манифеста» вместе с любыми показателями для этого конкретного файла. Это означает, что когда вы выполняете чтение, запрос может определить, какие файлы на самом деле читать, не касаясь базовых файлов данных.
Например, если у вас есть 3 файла со столбцом A, файл манифеста будет выглядеть примерно так
path/to/file1 | Max Value of ColA in File1 | Min Value of ColA in File1
path/to/file2 | Max Value of ColA in File2 | Min Value of ColA in File2
path/to/file3 | Max Value of ColA in File3 | Min Value of ColA in File3
Поэтому, когда я читаю этот файл, я оцениваю любые предикаты ColA, не касаясь file1, file2 или file3.
Эти «метаданные» можно прочитать из «таблицы метаданных» в Iceberg, но это просто SQL-представление файлов метаданных для конкретного снимка.