Какова логика минимального 15-минутного интервала в планировании AWS DataPipeline?
Недавно меня попросили создать механизм для получения данных с нашего RDS MySQL в режиме, близком к реальному времени, то есть в течение 5 секунд. до 5 минут Прочитав Lambda, Flydata и Data Pipelines, я выбрал AWS Data Pipeline, так как многие форумы упоминают его название, когда речь заходит о приеме данных практически в реальном времени.
AWS Data Pipeline позволяет нам планировать работу, поэтому я выбрал опцию планирования и настраивал ее запуск каждые 2 минуты.
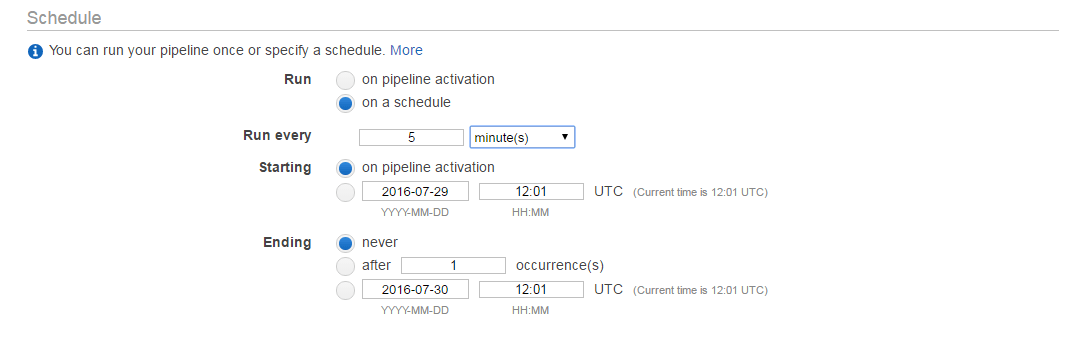
Здесь идет ужасная часть. Он также попросил меня установить интервал!! который должен быть больше 15 минут. Я имею в виду, почему бы это? Разве это не должно быть около реального времени? Теперь, когда я запустил свой Pipeline, он работал так. (После установки интервала 15 минут) 
Как это должно быть около реального времени? Я имею в виду, понимаете ли AWS, что почти в режиме реального времени это означает в течение нескольких секунд или, по крайней мере, нескольких минут, но 15-17 минут - это огромный шаг назад для меня. Может кто-нибудь сказать мне, как преодолеть эту проблему. Я думал о планировании нескольких конвейеров и задании предварительных условий, но я не уверен, что это сработает. пожалуйста помоги...
1 ответ
Я бы порекомендовал Amazon Kinesis для работы с данными в реальном времени.