Горизонтальное масштабирование в системе с источником событий, имеющей базу данных в памяти
Я читал об источниках событий, о ведении журналов событий и воссоздании состояния приложения при запуске сервера.
Что происходит, когда вам нужно масштабировать систему по горизонтали? Не будет ли необходимости в службе синхронизации между всеми серверами для поддержания работоспособности данных, поскольку событие, обрабатываемое одним сервером, должно обновлять состояние моего приложения в нескольких экземплярах?
Как добиться согласованности, или мне здесь не хватает какой-то концепции? Или эти системы могут иметь только конечную согласованность?
Могу ли я создавать системы, требующие высокого уровня согласованности, такие как приложение бухгалтерской книги с двойной записью, с использованием источников событий?
3 ответа
Для обеспечения высокой согласованности в горизонтально масштабируемой системе с источником событий вы, как правило, будете сегментировать (разбивать) объекты, состояние которых должно определяться с помощью событий, среди экземпляров службы. Запросы, которые должны быть строго согласованными внутри объекта (или агрегата, если мы говорим о проекте, управляемом доменом), затем направляются в правильный экземпляр; обычно также присутствует компонент координации, отвечающий за перемещение шардов в ответ на сбои экземпляра.
При этом полезно определить, какие запросы строго согласованы (т. Е. Должны маршрутизироваться на основе сегментирования), а какие в конечном итоге могут быть согласованными (могут обрабатываться представлением потока событий): поскольку последний не требует никакой синхронизации.
Я лично использовал Akka Persistence для определения акторов на основе событий для управления экземплярами агрегатов в приложениях, а затем использовал Akka Cluster Sharding для управления распределением этих субъектов по кластеру и маршрутизации запросов, но есть и другие системы, которые реализуют аналогичные функции.
Точный подход / дизайн зависит от точной архитектуры системы, варианта использования, программных компонентов и имеющихся требований.
Для обеспечения сохранения данных существуют различные шаблоны, такие как База данных для каждой службы, шаблон CQRS, шаблон источника событий, шаблон саги и общая база данных для шаблона службы. Возможно, вам придется выбрать один из них или их комбинацию в соответствии с вашими потребностями.
Шаблон источника событий должен быть необходим, если существует потребность в возможной согласованности данных между микросервисами в сочетании с синхронизацией данных между системами, поскольку хранилище событий становится источником истины. В случае источника событий все изменения состояния приложения или транзакций сохраняются в виде последовательности событий через источник событий, который полагается на объект события для записи / обновления изменения состояния. Текущее состояние приложения и дополнительный контекст того, как приложение перешло в это состояние, могут быть визуализированы с помощью этого шаблона и, таким образом, он позволяет реконструировать состояние приложения в любой момент времени. В общем, шаблон микросервиса ведения журнала аудита зависит от источника событий.
Для использования шаблона источника событий в соответствии с дизайном / требованиями вашей системы может потребоваться шаблон Saga для поддержания согласованности данных между микросервисами. Если транзакции охватывают несколько служб, можно попробовать шаблон Saga, в котором событие или сообщение публикуются для запуска следующего шага транзакции (здесь последовательность транзакций обновляет каждую службу). Saga также действует как обработчик ошибок, имея логику компенсации путем отправки событий отката. Шаблон Saga может быть выполнен с помощью Orchestrator, где отдельная служба будет заботиться о бизнес-логике, взаимодействуя / упорядочивая с другими службами в локальных транзакциях, которые будут выполняться. Образец саги также может быть выполнен с помощью хореографии, где без центральной координации,каждая служба будет ожидать обновления транзакции в других службах и, соответственно, запускать локальную транзакцию и соответственно обновлять другую службу.
Эту систему источников событий, в свою очередь, можно сделать гибкой, масштабируемой и простой в обслуживании в сочетании с шаблоном CQRS, который должен разделять рабочие нагрузки чтения и записи, при этом данные хранятся в виде серии событий, а не напрямую обновляются в хранилищах данных.
AWS поддерживает схему источников событий через Amazon Kinesis Data Streams или Amazon EventBridge.. В решении на основе Kinesis Data Stream, изображенном ниже, потоки данных Kinesis действуют как ключевой объект хранилища событий, который фиксирует изменения приложения как события и сохраняет их в Amazon S3.
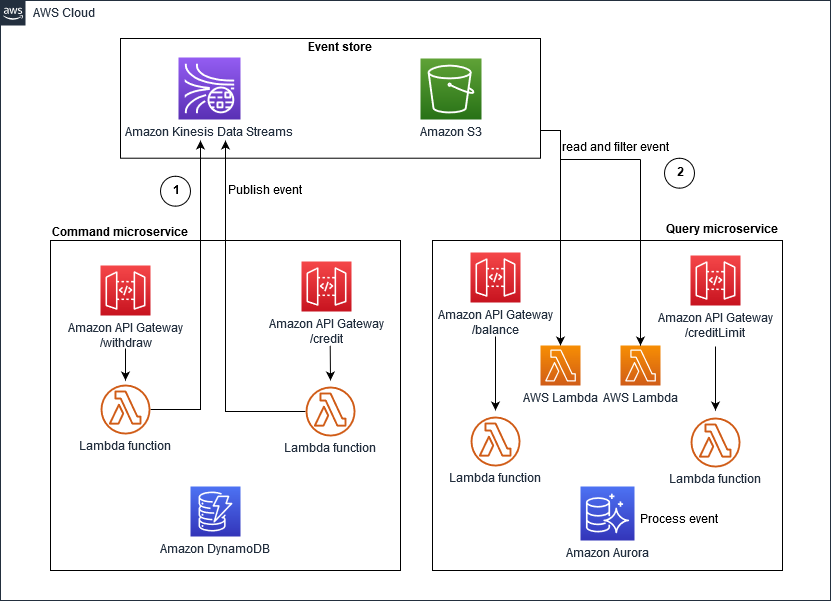
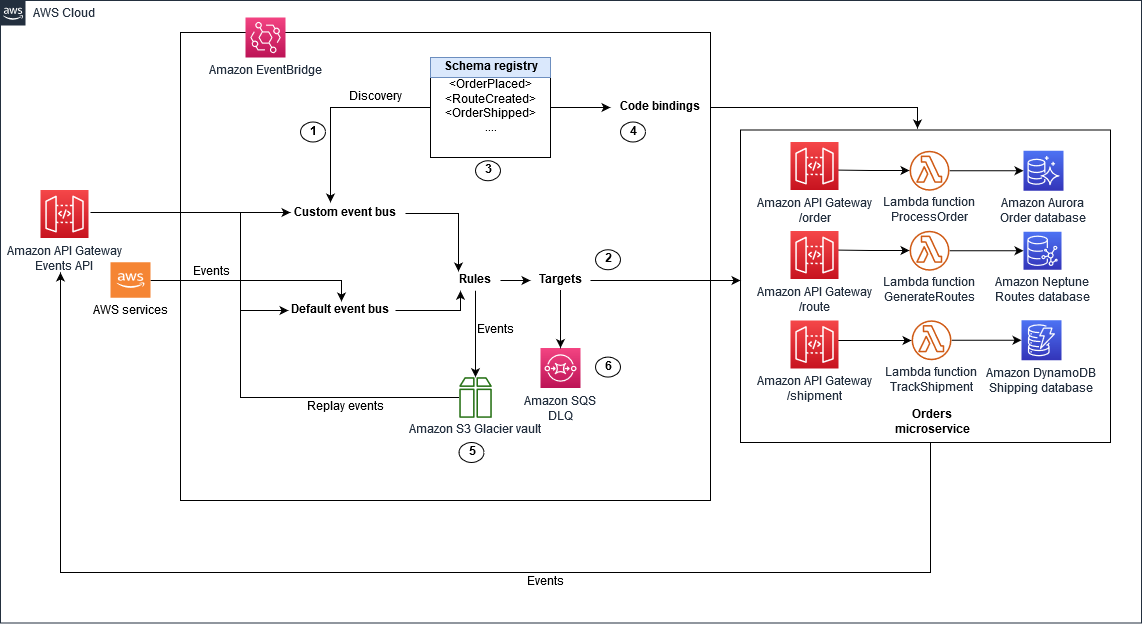
В решении на основе EventBridge, изображенном ниже, EventBridge используется в качестве хранилища событий и обеспечивает шину событий по умолчанию для событий, публикуемых сервисами AWS, а также вы можете создать настраиваемую шину событий для специфичных для домена шин.
В случае GCP pub/sub используется как реестр, который действует как запись только для добавления событий, опубликованных на шине событий или в какой-либо очереди сообщений, а система событий может использоваться для запуска интересующих облачных функций (archiever, replayer, janitor, bqloader или др.) каждый раз, когда запись записывается в поток, и эти облачные функции должны масштабироваться в зависимости от объема запросов без какого-либо вмешательства.
Kafka поддерживает шаблон источника событий с темой и разделом.Есть несколько способов сохранения событий. Существует тип «все сущности», при котором вы можете хранить все события для всех типов сущностей в одной теме (разделенной), и есть опция «Тема для каждого типа сущности», где должна быть создана отдельная тема для всех событий. относящиеся к конкретному модулю / сущности, и есть опция «Тема-на-сущность», для каждого продукта / пользователя создается отдельная тема. Приложения Kafka Streams работают в кластере узлов, которые совместно используют некоторые темы. Kafka Streams обеспечивает высокоуровневые операции с данными, что значительно упрощает создание производных потоков. Соответственно, Kafka Streams поддерживает сворачивание потока в локальное хранилище. Реализация локального хранилища бывает двух типов, таких как механизм постоянного хранения (RocksDB, используется по умолчанию) и хранилище в памяти.Соответственно, вы можете свернуть поток событий в хранилище состояний, сохраняя локально «текущее состояние» каждой сущности из разделов, назначенных узлу. Если вы используете реализацию хранилища состояний RocksDB, вы ограничены только дисковым пространством в отношении того, сколько сущностей можно отслеживать на одном узле, и проблему масштабирования можно смягчить путем дальнейшего разбиения исходной темы. Вы можете использовать коннектор Kafka Connect, который будет обрабатывать все важные детали и помогать сохранять события или данные из событий в ElasticSearch или PostgreSQL. Кроме того, этап Kafka Streams может использоваться для обработки сценариев, когда одно событие запускает другие события в вашей системе. Также следует отметить, что Kafka изначально не был разработан для источников событий, однако его дизайн как движок потоковой передачи данных с реплицированными темами, секционированием,State store и потоковые API очень гибкие и идеально подходят для решения этой задачи.
Точное решение зависит от предъявляемых требований и показателей производительности, определенных для вашей системы.
Я добавляю это как ответ, потому что это понятнее, чем пытаться втиснуть его в комментарий. Леви звучит так, будто у него есть опыт в этом (поиск событий) - я нет.
Короткий ответ: ищите шаблоны проектирования, которые решают вашу проблему. (Я бы сказал вам, какими они были, если бы знал их :) Но можете поспорить, что вы не первый, кто столкнется с этой проблемой.
Еще одна вещь, которую вы можете сделать, если вы выбрали стек технологий, - это посмотреть, какие конкретные инструменты и шаблоны проектирования у них есть. Например, у меня есть работа над книгой Кафки, в которой говорится о подобных вещах, но в специфической манере; поставил бы любую сумму денег на то, что у AWS есть аналогичные рекомендации и т. д.
В любом случае, вот кое-что, что может помочь: