Проблема с производительностью Java в Oracle Linux
Я запускаю очень "простой" тест с помощью.
@Fork(value = 1, jvmArgs = { "--illegal-access=permit", "-Xms10G", "-XX:+UnlockDiagnosticVMOptions", "-XX:+DebugNonSafepoints", "-XX:ActiveProcessorCount=7",
"-XX:+UseNUMA"
, "-XX:+UnlockDiagnosticVMOptions", "-XX:DisableIntrinsic=_currentTimeMillis,_nanoTime",
"-Xmx10G", "-XX:+UnlockExperimentalVMOptions", "-XX:ConcGCThreads=5", "-XX:ParallelGCThreads=10", "-XX:+UseZGC", "-XX:+UsePerfData", "-XX:MaxMetaspaceSize=10G", "-XX:MetaspaceSize=256M"}
)
@Benchmark
public String generateRandom() {
return UUID.randomUUID().toString();
}
Может быть, это не очень просто, потому что используется случайный, но такая же проблема есть в любых других тестах с java
На моем домашнем рабочем столе
Intel(R) Core(TM) i7-8700 CPU @ 3.20GHz 12 Threads (hyperthreading enabled ), 64 GB Ram, "Ubuntu" VERSION="20.04.2 LTS (Focal Fossa)"
Linux homepc 5.8.0-59-generic #66~20.04.1-Ubuntu SMP Thu Jun 17 11:14:10 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux
Производительность с 7 потоками:
Benchmark Mode Cnt Score Error Units
RulesBenchmark.generateRandom thrpt 5 1312295.357 ± 27853.707 ops/s
График пламени с результатом AsyncProfiler с 7 потоками дома 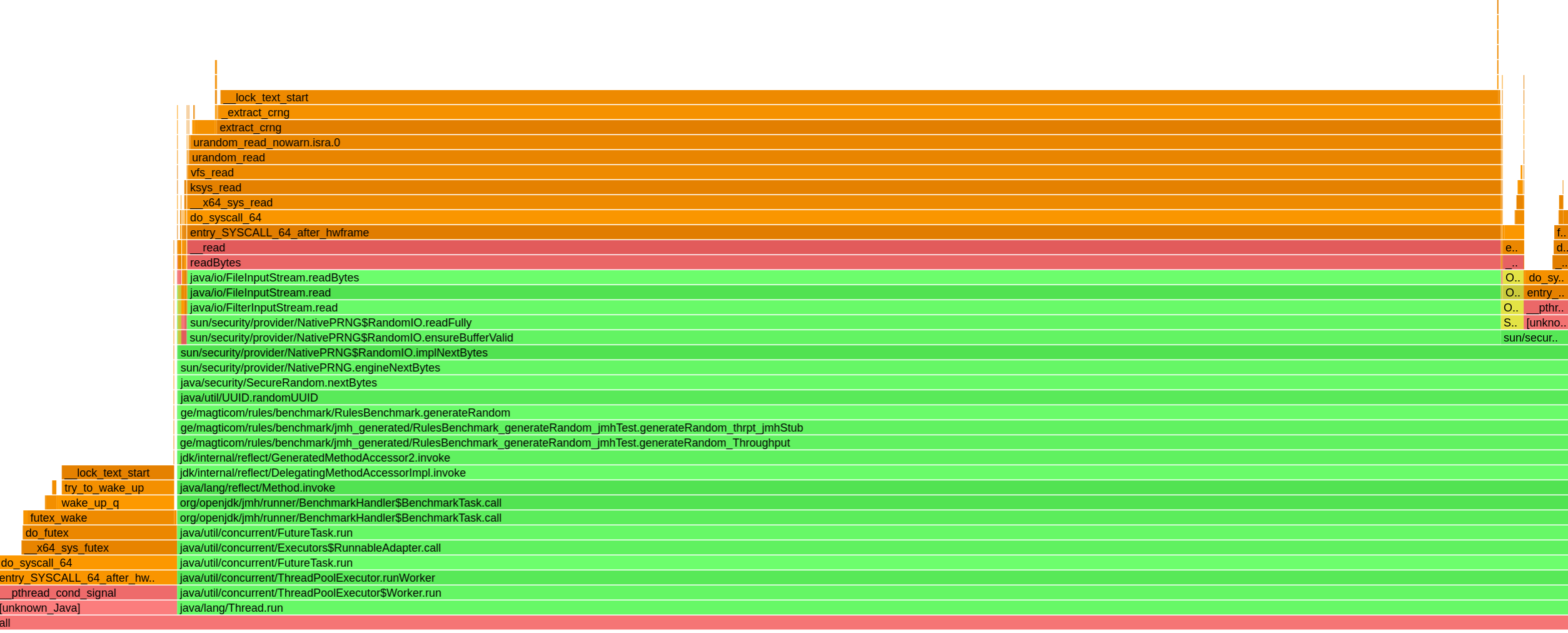
У меня проблема с Oracle Linux
Linux 5.4.17-2102.201.3.el8uek.x86_64 #2 SMP Fri Apr 23 09:05:57 PDT 2021 x86_64 x86_64 x86_64 GNU/Linux
Intel(R) Xeon(R) Gold 6258R CPU @ 2.70GHz with 56 Threads(hyperthreading disabled, the same when enabled and there is 112 cpu threads ) and 1 TB RAM I have half of performance (Even increasing threads) NAME="Oracle Linux Server" VERSION="8.4"
с 1 потоком у меня очень хорошая производительность:
Benchmark Mode Cnt Score Error Units
RulesBenchmark.generateRandom thrpt 5 2377471.113 ± 8049.532 ops/s
График пламени с AsyncProfiler Результат 1 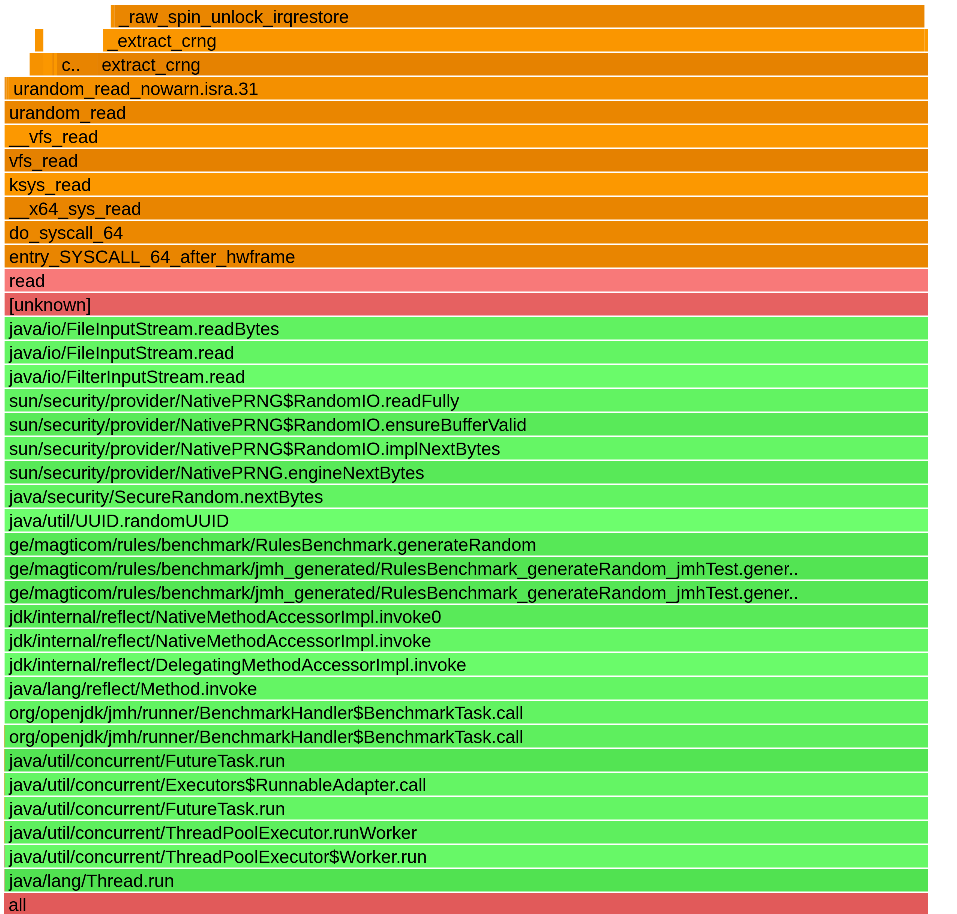 поток, но с 7 потоками
поток, но с 7 потоками
Benchmark Mode Cnt Score Error Units
RulesBenchmark.generateRandom thrpt 5 688612.296 ± 70895.058 ops/s
График пламени с потоком результата 7 AsyncProfiler

Возможно, это проблема NUMA, потому что есть 2 сокета, а система настроена только с 1 узлом NUMA numactl --hardware
available: 1 nodes (0)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55
node 0 size: 1030835 MB
node 0 free: 1011029 MB
node distances:
node 0
0: 10
Но после отключения некоторых потоков процессора с помощью:
for i in {12..55}
do
# your-unix-command-here
echo '0'| sudo tee /sys/devices/system/cpu/cpu$i/online
done
Производительность немного улучшилась, не намного.
Это просто очень "простой" тест. На сложном тесте с реальным кодом это даже стоит, он тратит много времени на
.annobin___pthread_cond_signal.start
Я также развернул бродячий образ с той же версией
Oracle Linuxи версию ядра на моем домашнем рабочем столе и запускал его с 10 потоками процессора, а производительность была почти такой же (~1 млн операций в секунду), как и на моем рабочем столе. Так что дело не в ОС или ядре, а в какой-то конфигурации
Протестировано с несколькими версиями jDK и поставщиками (jdk 11 и выше). Это очень мало , производительность при использовании OpenJDK 11 от распределения YUM, но не имеет существенного значения.
Не могли бы вы дать какой-нибудь совет Спасибо заранее
1 ответ
По сути, ваш тест тестирует пропускную способность. Реализация по умолчанию синхронизирована (точнее, реализация по умолчанию смешивает форму ввода и вышеуказанный поставщик).
Парадокс заключается в том, что большее количество потоков приводит к большему количеству конфликтов и, следовательно, к снижению общей производительности, поскольку основная часть алгоритма в любом случае находится под глобальной блокировкой. Async-profiler действительно показывает, что узким местом является синхронизация на мониторе Java:
__lll_unlock_wake,
__pthread_cond_wait,
__pthread_cond_signal - все происходит из этой синхронизации.
Накладные расходы на конкуренцию определенно зависят от оборудования, прошивки и конфигурации ОС. Вместо того, чтобы пытаться уменьшить эти накладные расходы (что может быть сложно, поскольку, как вы знаете, однажды появится еще один патч безопасности, который, например, сделает системные вызовы в 2 раза медленнее), я бы предложил избавиться от разногласий в первом место.
Этого можно добиться, установив другой, неблокирующий
SecureRandomпровайдер, как показано в этом ответе . Я не буду давать рекомендации по конкретному
SecureRandomSpi, поскольку это зависит от ваших конкретных требований (пропускная способность / масштабируемость / безопасность). Упомяну только, что реализация может быть основана на