Как можно адаптировать учебник из tensorflow: «Квантовое обучение с подкреплением» для TicTacToe? [закрыто]
Я слежу за записной книжкой:
https://www.tensorflow.org/quantum/tutorials/quantum_reinforcement_learning
и я попытался использовать его для. Имеет измерение состояния 9 (потому что существует 9 случаев) и 9 действий (числа от 0 до 8, каждое из которых соответствует размещению
'X'по футляру). Агент играет против случайного алгоритма, который здесь только для того, чтобы совершать случайные действия, как если бы агент играл против кого-то. Агент получает награду -2, если проигрывает, -1, если он применяет действие к уже выполненному делу, и +2, если он выигрывает, но проблема в том, что агент, похоже, не учится.
Вот изображение наград в разных играх, и оно не увеличивается
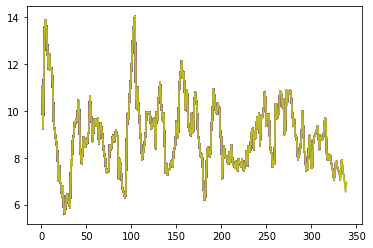
Я уже адаптировал количество кубитов к размеру состояния моей игры.
Мой вопрос: предполагается ли, что этот учебник работает только для
CartPoleа как игры? Пропустил ли я что-то, что нужно изменить в структуре алгоритма, чтобы я мог использовать его со своим
TicTacToe ?