Как прочитать числовое значение из файла Excel с помощью Spring Batch Excel
Я читаю значения из .xlsx, используя spring batch excel и POI. Я вижу, что числовые значения печатаются в формате, отличном от исходного значения в .xlsx
Пожалуйста, предложите мне, как распечатать значения как в файле .xlsx. Ниже приведены подробности.
В моем Excel значения следующие
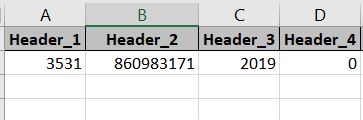
Значения печатаются, как показано ниже

Мой код такой, как показано ниже
public ItemReader<DataObject> fileItemReader(InputStream inputStream){
PoiItemReader<DataObject> reader = new PoiItemReader<DataObject>();
reader.setLinesToSkip(1);
reader.setResource(new InputStreamResource(DataObject));
reader.setRowMapper(excelRowMapper());
reader.open(new ExecutionContext());
return reader;
}
private RowMapper<DataObject> excelRowMapper() {
return new MyRowMapper();
}
public class MyRowMapper implements RowMapper<DataObject> {
@Override
public DataRecord mapRow(RowSet rowSet) throws Exception {
DataObject dataObj = new DataObject();
dataObj.setFieldOne(rowSet.getColumnValue(0));
dataObj.setFieldTwo(rowSet.getColumnValue(1));
dataObj.setFieldThree(rowSet.getColumnValue(2));
dataObj.setFieldFour(rowSet.getColumnValue(3));
return dataObj;
}
}
2 ответа
У меня была такая же проблема, и ее корнем является класс org.springframework.batch.item.excel.poi.PoiSheet внутри PoiItemReader. Проблема возникает в методе
public String[] getRow(final int rowNumber)где он получает объект org.apache.poi.ss.usermodel.Row и преобразует его в массив строк после определения типа каждого столбца в строке. В этом методе у нас есть код:
switch (cellType) {
case NUMERIC:
if (DateUtil.isCellDateFormatted(cell)) {
Date date = cell.getDateCellValue();
cells.add(String.valueOf(date.getTime()));
} else {
cells.add(String.valueOf(cell.getNumericCellValue()));
}
break;
case BOOLEAN:
cells.add(String.valueOf(cell.getBooleanCellValue()));
break;
case STRING:
case BLANK:
cells.add(cell.getStringCellValue());
break;
case ERROR:
cells.add(FormulaError.forInt(cell.getErrorCellValue()).getString());
break;
default:
throw new IllegalArgumentException("Cannot handle cells of type '" + cell.getCellTypeEnum() + "'");
}
В котором обработка ячейки, обозначенной как NUMERIC, есть. В этой строке значение ячейки преобразуется в двойное (
cell.getNumericCellValue()), и этот тип double преобразуется в String(). Проблема возникает в
String.valueOf() , который генерирует научную нотацию, если число слишком велико (>=10000000) или слишком мало (<0,001), и помещает «.0» в целочисленные значения.
Как альтернатива линии
cells.add(String.valueOf(cell.getNumericCellValue())), вы могли бы использовать
DataFormatter formatter = new DataFormatter();
cells.add(formatter.formatCellValue(cell));
который вернет вам точные значения ячеек в виде строки. Однако это также означает, что ваши десятичные числа будут зависеть от локали (вы получите строку «2,5» из документа, сохраненного в Excel, настроенном для Великобритании или Индии, и строку «2,5» из Франции или Бразилии).
Чтобы избежать этой зависимости, мы можем использовать решение, представленное на /questions/18304818/kak-napechatat-dvojnoe-znachenie-bez-nauchnoj-notatsii-s-ispolzovaniem-java/18304835#18304835:
DecimalFormat df = new DecimalFormat("0", DecimalFormatSymbols.getInstance(Locale.ENGLISH));
df.setMaximumFractionDigits(340);
cells.add(df.format(cell.getNumericCellValue()));
Это преобразует ячейку в двойную, а затем отформатирует ее в соответствии с английским шаблоном без научного обозначения или добавления «.0» к целым числам.
Моя реализация CustomPoiSheet (небольшая адаптация оригинального PoiSheet) была:
class CustomPoiSheet implements Sheet {
protected final org.apache.poi.ss.usermodel.Sheet delegate;
private final int numberOfRows;
private final String name;
private FormulaEvaluator evaluator;
/**
* Constructor which takes the delegate sheet.
*
* @param delegate the apache POI sheet
*/
CustomPoiSheet(final org.apache.poi.ss.usermodel.Sheet delegate) {
super();
this.delegate = delegate;
this.numberOfRows = this.delegate.getLastRowNum() + 1;
this.name=this.delegate.getSheetName();
}
/**
* {@inheritDoc}
*/
@Override
public int getNumberOfRows() {
return this.numberOfRows;
}
/**
* {@inheritDoc}
*/
@Override
public String getName() {
return this.name;
}
/**
* {@inheritDoc}
*/
@Override
public String[] getRow(final int rowNumber) {
final Row row = this.delegate.getRow(rowNumber);
if (row == null) {
return null;
}
final List<String> cells = new LinkedList<>();
final int numberOfColumns = row.getLastCellNum();
for (int i = 0; i < numberOfColumns; i++) {
Cell cell = row.getCell(i);
CellType cellType = cell.getCellType();
if (cellType == CellType.FORMULA) {
FormulaEvaluator evaluator = getFormulaEvaluator();
if (evaluator == null) {
cells.add(cell.getCellFormula());
} else {
cellType = evaluator.evaluateFormulaCell(cell);
}
}
switch (cellType) {
case NUMERIC:
if (DateUtil.isCellDateFormatted(cell)) {
Date date = cell.getDateCellValue();
cells.add(String.valueOf(date.getTime()));
} else {
// Returns numeric value the closer possible to it's value and shown string, only formatting to english format
// It will result in an integer string (without decimal places) if the value is a integer, and will result
// on the double string without trailing zeros. It also suppress scientific notation
// Regards to https://stackoverflow.com/a/25307973/9184574
DecimalFormat df = new DecimalFormat("0", DecimalFormatSymbols.getInstance(Locale.ENGLISH));
df.setMaximumFractionDigits(340);
cells.add(df.format(cell.getNumericCellValue()));
//DataFormatter formatter = new DataFormatter();
//cells.add(formatter.formatCellValue(cell));
//cells.add(String.valueOf(cell.getNumericCellValue()));
}
break;
case BOOLEAN:
cells.add(String.valueOf(cell.getBooleanCellValue()));
break;
case STRING:
case BLANK:
cells.add(cell.getStringCellValue());
break;
case ERROR:
cells.add(FormulaError.forInt(cell.getErrorCellValue()).getString());
break;
default:
throw new IllegalArgumentException("Cannot handle cells of type '" + cell.getCellTypeEnum() + "'");
}
}
return cells.toArray(new String[0]);
}
private FormulaEvaluator getFormulaEvaluator() {
if (this.evaluator == null) {
this.evaluator = delegate.getWorkbook().getCreationHelper().createFormulaEvaluator();
}
return this.evaluator;
}
}
И моя реализация CustomPoiItemReader (небольшая адаптация оригинального PoiItemReader), вызывающая CustomPoiSheet:
public class CustomPoiItemReader<T> extends AbstractExcelItemReader<T> {
private Workbook workbook;
@Override
protected Sheet getSheet(final int sheet) {
return new CustomPoiSheet(this.workbook.getSheetAt(sheet));
}
public CustomPoiItemReader(){
super();
}
@Override
protected int getNumberOfSheets() {
return this.workbook.getNumberOfSheets();
}
@Override
protected void doClose() throws Exception {
super.doClose();
if (this.workbook != null) {
this.workbook.close();
}
this.workbook=null;
}
/**
* Open the underlying file using the {@code WorkbookFactory}. We keep track of the used {@code InputStream} so that
* it can be closed cleanly on the end of reading the file. This to be able to release the resources used by
* Apache POI.
*
* @param inputStream the {@code InputStream} pointing to the Excel file.
* @throws Exception is thrown for any errors.
*/
@Override
protected void openExcelFile(final InputStream inputStream) throws Exception {
this.workbook = WorkbookFactory.create(inputStream);
this.workbook.setMissingCellPolicy(Row.MissingCellPolicy.CREATE_NULL_AS_BLANK);
}
}
просто измените свой код таким образом при чтении данных из Excel.
dataObj.setField(Float.valueOf(rowSet.getColumnValue(idx)).intValue();
это работает только для столбцов A,B,C