Как визуализировать количество вхождений в фреймворке pandas?
У меня есть Dataframe с 16000 записями и 12 столбцами. Я (надеюсь) уже удалил дубликаты и значения Nan. Я хочу визуализировать количество вхождений в столбце «бренд» на круговой диаграмме с помощью Pandas. Но каждый бренд, который встречается менее 20 раз, должен быть сгруппирован и назван «Freie Tankstellen».
Я должен:
df_stations['brand'].value_counts().to_frame()< 20
Но я не знаю, как действовать, заранее спасибо!
elias_lay_u_schisslbauer_simon2021-06-12_11-57 - Блокнот Jupyter
,uuid,name,brand,street,house_number,post_code,city,latitude,longitude,first_active,openingtimes_json,state,istFrei
0,0e18d0d3-ed38-4e7f-a18e-507a78ad901d,OIL! Tankstelle München,OIL!,EVERSBUSCHSTRASSE,33,80999,MÜNCHEN,48.1807,11.4609,1970-01-01 01:00:00+01,"{""openingTimes"":[{""applicable_days"":192,""periods"":[{""startp"":""07:00"",""endp"":""20:00""}]},{""applicable_days"":63,""periods"":[{""startp"":""06:00"",""endp"":""22:00""}]}]}",Bayern,True
1,44e2bdb7-13e3-4156-8576-8326cdd20459,bft Tankstelle,BFT TANKSTELLE,SCHELLENGASSE ,53,36304,ALSFELD,50.7520089,9.2790394,1970-01-01 01:00:00+01,"{""openingTimes"":[{""applicable_days"":63,""periods"":[{""startp"":""06:00"",""endp"":""22:00""}]},{""applicable_days"":64,""periods"":[{""startp"":""07:00"",""endp"":""21:00""}]}]}",Hessen,True
2,ad812258-94e7-473d-aa80-d392f7532218,bft Bonn-Bad Godesberg,BFT,GODESBERGER ALLEE,55,53175,BONN,50.6951,7.14276,1970-01-01 01:00:00+01,"{""openingTimes"":[{""applicable_days"":31,""periods"":[{""startp"":""06:00"",""endp"":""22:00""}]},{""applicable_days"":32,""periods"":[{""startp"":""07:00"",""endp"":""22:00""}]},{""applicable_days"":64,""periods"":[{""startp"":""08:00"",""endp"":""22:00""}]}]}",Nordrhein-Westfalen,True
1 ответ
Решение
- Использовать
df.brand.value_counts()добавить столбец вdfс использованием.merge. - Используйте логическое индексирование, чтобы переименовать любое имя с
'total_count'меньше, чем,.lt, 20. - Получите новый
.value_countsдля'brand'и постройте горизонтальную полосу, используяpandas.DataFrame.plotс участиемkind='barh'. Если брендов не так много, используйтеkind='bar'и изменитьfigsize. можно использовать, но пока мне нравитсяpi, и кусочки пирога, я не люблю или рекомендуюpieграфики.- Основная цель использования круговой диаграммы, а не гистограммы, состоит в том, чтобы визуально указать, что набор значений представляет собой доли или проценты, которые в сумме составляют целое. Это сообщение требует значительных затрат: сравнивать значения с круговой диаграммой сложнее, чем с гистограммой, потому что зрителю труднее сравнивать углы, образуемые двумя дугами, чем сравнивать высоту для двух столбцов. - Бергстром, Карл Т .; Уэст, Джевин Д. Вызов ерунды (стр. 179). Издательская группа «Рэндом Хаус». Разжечь издание.
- С использованием
pandas v1.2.4а такжеmatplotlib v3.4.2
import pandas as pd
import numpy as np # for sample data
# sample data
data = ['Aloha Petroleum', 'Alon', 'American Gas', 'Amoco', 'ARCO', 'Billups', 'BP', "Buc-ee's", "Casey's General Stores", 'CEFCO', 'CENEX', 'Chevron', 'Circle K', 'Citgo', 'Clark Brands', 'Conoco', 'Costco', 'Crown', 'Cumberland Farms', 'Delta Sonic - Buffalo New York']
# probabilities for each brand
prob = [0.099, 0.099, 0.099, 0.0501, 0.0501, 0.0501, 0.05, 0.05, 0.05, 0.05, 0.05, 0.05, 0.05, 0.05, 0.05, 0.05, 0.05, 0.0009, 0.0009, 0.0009]
# sample dataframe
np.random.seed(2)
df = pd.DataFrame({'brand': np.random.choice(data, size=(16000,), p=prob)})
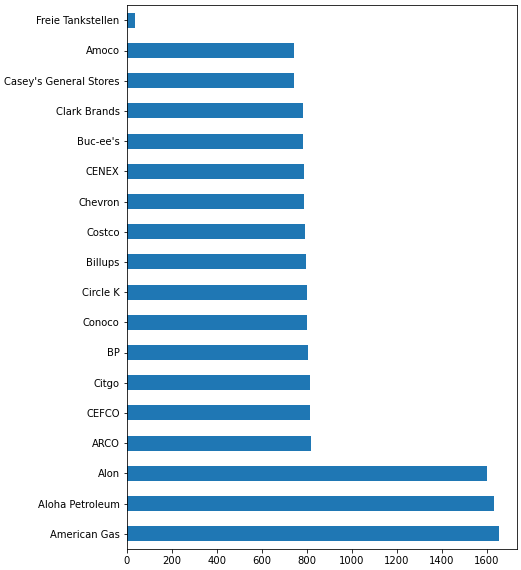
# add a column to the dataframe called total_count
df = df.merge(df.brand.value_counts(), left_on='brand', right_index=True).rename({'brand_y': 'total_count'}, axis=1)
# any brand with a total_count less than 20 is renamed
df.loc[df.total_count.lt(20), 'brand'] = 'Freie Tankstellen'
# plot the new value count with the updated brand name
df.brand.value_counts().plot(kind='barh', figsize=(7, 10))
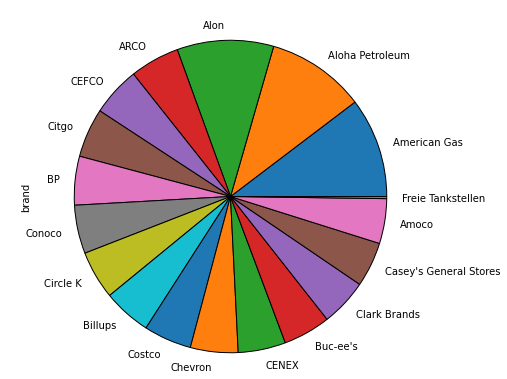
По сравнению с
kind='pie'
df.brand.value_counts().plot(kind='pie', figsize=(7, 10))