"Ошибка разбора типа столбца" Redshift Spectrum
У меня есть сценарий использования спектра, использующий файлы большого количества json-файлов из s3. Я начал с сканирования данных с помощью сканера Glue для создания каталога данных. Затем с этим каталогом я создал внешнюю схему для ссылки на базу данных Glue, чтобы получить доступ к каталогу. Теперь я могу делать операторы select в строках корневого уровня, и это работает, например:
select t.id from glue_db.test t
Проблема в том, что, когда я делаю оператор select для объектов struct, я получаю эту ошибку "Ошибка синтаксического анализа типа столбца" t.actor.name "". Вот пример select (id - это строка внутри структуры актера):
select t.actor.name from glue_db.test t
Что мне не хватает? Я также пытался преобразовать JSON в паркет, и сталкиваюсь с теми же проблемами, пытаясь запросить вложенные данные.
Вот таблица клеевого определения:
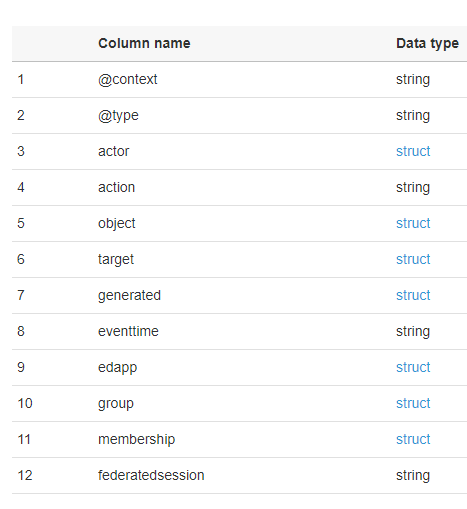
Вот структура актера:

1 ответ
Атрибуты, которые содержат вложенные значения, должны быть указаны в предложении FROM, чтобы Redshift знал, как получить к ним доступ. Также необходимо подтвердить, что созданный каталог Glue правильно указывает таблицы.
select a.id
from glue_db.test t, t.actor a
Пожалуйста, ознакомьтесь с этим руководством для получения справки о запросах вложенных данных с помощью Redshift Spectrum. https://docs.aws.amazon.com/redshift/latest/dg/tutorial-query-nested-data-sqlextensions.html
У меня была точно такая же ошибка, и после контакта с AWS Support я обнаружил, что символ обратной косой черты ( \) в имени поля вызывает именно это исключение, в вашем случае поля bb\user.id а также bb\user.externalId.
Поэтому для меня редактирование схемы и временное удаление поля, содержащего " \ ", или переименование поля, удаление обратной косой черты (например, bbuser.id) решил проблему.

Кредиты @ Hyruma92