GGRidges: слишком большой график плотности
У меня есть фрейм данных, который состоит из одной зависимой переменной и нескольких независимых переменных. Группы отношений были взяты из разных тестов (но это не важно для решения проблемы, с которой я столкнулся).
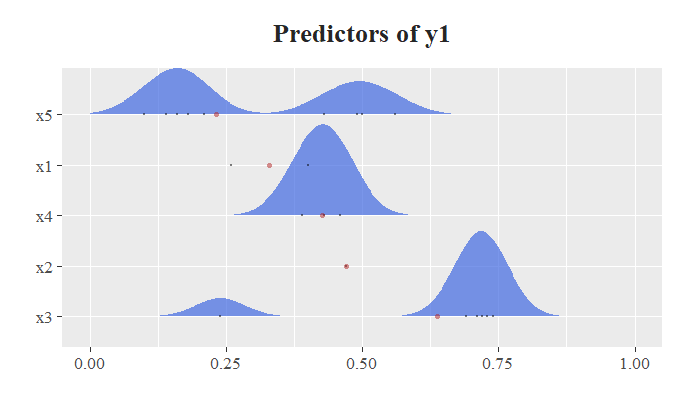
Я использую пакет ggridges для представления одного графика с графиками плотности для каждого отношения. Когда для одного отношения существует только одно значение, ggridges создает точку вместо графика плотности. Моя проблема в том, что в этом случае график плотности ниже перекрывается с пространством выше. Возможно, потому что ggridges не видит другой график плотности и расширяет пространство, которое может занять график плотности ниже. Опция "масштаб" может использоваться, чтобы избежать наложения двух графиков плотности, но не для того, чтобы избежать наложения между графиком плотности и точкой (по крайней мере, я так думаю).
Если я установлю масштаб = 0,5, я смогу решить проблему, но это не лучшая вещь, потому что каждый график плотности становится меньше. Также те, которые не пересекаются с другими.
Ниже я приложил воспроизводимый пример, который создает график с проблемой, с которой я столкнулся. Спасибо, кто мог бы помочь мне.
library(magrittr)
library(dplyr)
#>
#> Attaching package: 'dplyr'
#> The following objects are masked from 'package:stats':
#>
#> filter, lag
#> The following objects are masked from 'package:base':
#>
#> intersect, setdiff, setequal, union
library(forcats)
library(ggplot2)
library(ggridges)
library(RCurl)
#> Carico il pacchetto richiesto: bitops
y_ex <- c("y1","y1","y1","y1","y1","y1","y1","y1","y1","y1","y1","y1","y1","y1","y1","y1","y1","y1","y1","y1","y1","y1","y1")
x_ex <- c("x1","x1","x2","x3","x3","x3","x3","x3","x3","x4","x4","x4","x5","x5","x5","x5","x5","x5","x5","x5","x5","x5","x5")
value_ex <- c(0.26,0.40,0.47,0.72,0.71,0.69,0.74,0.73,0.24,0.39,0.43,0.46,0.21,0.18,0.14,0.10,0.16,-0.10,-0.11,0.56,0.50,0.49,0.43)
data_ex <- data.frame(y_ex,x_ex,value_ex)
r_ex <- data_ex %>%
dplyr::mutate(x_ex = forcats::fct_reorder(x_ex, desc(value_ex), fun = mean))
r_ex %>%
ggplot(aes(x = value_ex, y = x_ex)) +
ggtitle(paste0("Predictors of ",y_ex)) +
geom_density_ridges(fill = "royalblue",
scale = 0.9,
color = NA,
alpha = 0.7,
rel_min_height = 0.01) +
geom_point(size = 0.5, alpha = 0.5, pch = 16) +
geom_point(data = r_ex %>% group_by(x_ex) %>% dplyr::summarise(value_ex = mean(value_ex)),
color = "firebrick",
pch = 16,
alpha = 0.5) +
scale_y_discrete("") +
scale_x_continuous("", limits = c(0, 1)) +
theme_grey(base_size = 16, base_family = "serif") +
theme(plot.title = element_text(hjust = 0.5,
lineheight = .8,
face = "bold",
margin = margin(10, 0, 20, 0),
color = "gray15"),
legend.position = "none")
#> Picking joint bandwidth of 0.0453
#> Warning: Removed 2 rows containing non-finite values (stat_density_ridges).
#> Warning: Removed 2 rows containing missing values (geom_point).`
1 ответ
Происходит то, что эвристика масштабирования запутывается отсутствующими данными. Эвристика масштабирования берет полный диапазон базовых значений y и делит его на количество групп - 1, см. Здесь.
В вашем случае, эвристика масштабирования создает эталонную шкалу, которая в два раза больше, и поэтому вам следует использовать scale = 0.45 чтобы получить тот же эффект, который вы получаете с scale = 0.9 если бы не было пропущенных уровней.
Обратите внимание, что все области должны масштабироваться вместе, поскольку области под распределениями должны быть одинакового размера (1 в некоторых единицах). Ваш x5 распределения не такие высокие, потому что они бимодальные и, следовательно, намного шире.